This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
DataEngineers of Netflix?—?Interview Interview with Pallavi Phadnis This post is part of our “ DataEngineers of Netflix ” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Pallavi Phadnis is a Senior Software Engineer at Netflix.
Dataengineering projects often require the setup and management of complex infrastructures that support data processing, storage, and analysis. In this article, we will explore the benefits of leveraging IaC for dataengineering projects and provide detailed implementation steps to get started.
In software engineering, we've learned that building robust and stable applications has a direct correlation with overall organization performance. The data community is striving to incorporate the core concepts of engineering rigor found in software communities but still has further to go.
Building and Scaling Data Lineage at Netflix to Improve DataInfrastructure Reliability, and Efficiency By: Di Lin , Girish Lingappa , Jitender Aswani Imagine yourself in the role of a data-inspired decision maker staring at a metric on a dashboard about to make a critical business decision but pausing to ask a question?—?“Can
Netflix’s engineering culture is predicated on Freedom & Responsibility, the idea that everyone (and every team) at Netflix is entrusted with a core responsibility and they are free to operate with freedom to satisfy their mission. All these micro-services are currently operated in AWS cloud infrastructure.
With the rapid adoption of cloud computing , businesses are moving their IT infrastructure to the cloud. This article discusses the challenges and best practices of data migration when transferring on-premise data to the cloud.
As organizations continue to adopt multicloud strategies, the complexity of these environments grows, increasing the need to automate cloud engineering operations to ensure organizations can enforce their policies and architecture principles. This requires significant dataengineering efforts, as well as work to build machine-learning models.
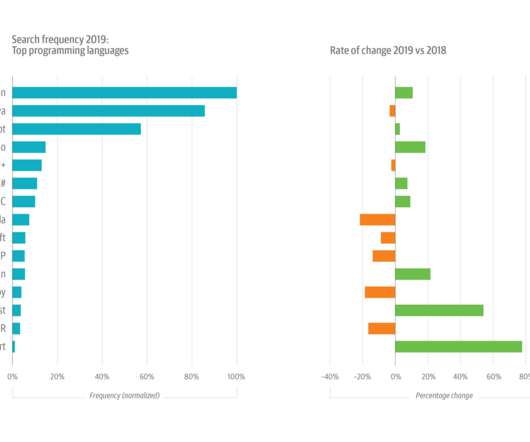
Languages Over time, the extraction of data from Netflix’s source systems has grown to encompass a wider range of end-users, such as engineers, data scientists, analysts, marketers, and other stakeholders. A large number of our data users employ SparkSQL, pyspark, and Scala.
by Shefali Vyas Dalal AWS re:Invent is a couple weeks away and our engineers & leaders are thrilled to be in attendance yet again this year! Netflix shares how Amazon EC2 Auto Scaling allows its infrastructure to automatically adapt to changing traffic patterns in order to keep its audience entertained and its costs on target.
Berg , Romain Cledat , Kayla Seeley , Shashank Srikanth , Chaoying Wang , Darin Yu Netflix uses data science and machine learning across all facets of the company, powering a wide range of business applications from our internal infrastructure and content demand modeling to media understanding.
This year’s growth in Python usage was buoyed by its increasing popularity among data scientists and machine learning (ML) and artificial intelligence (AI) engineers. Software architecture, infrastructure, and operations are each changing rapidly. Also: infrastructure and operations is trending up, while DevOps is trending down.
Our customers are product and engineering teams at Netflix that build these software services and platforms. Our goal is to manage security risks to Netflix via clear, opinionated security guidance, and by providing risk context to Netflix engineering teams to make pragmatic risk decisions at scale.
At Netflix, our data scientists span many areas of technical specialization, including experimentation, causal inference, machine learning, NLP, modeling, and optimization. Together with data analytics and dataengineering, we comprise the larger, centralized Data Science and Engineering group.
SIEM platforms offer centralized management of security operations, making it easier for organizations to monitor, manage, and secure their IT infrastructure. Correlation Engine: SIEM systems analyze and correlate the collected data to identify patterns, anomalies, and potential security incidents.
Once identified, … The post Less is More: EngineeringData Warehouse Efficiency with Minimalist Design appeared first on Uber Engineering Blog. In our experience, optimizing for operational efficiency requires answering one key question: for which tables does the maintenance cost supersede utility?
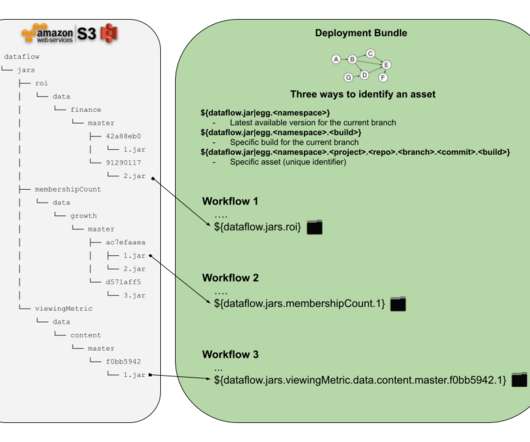
Let’s define some requirements that we are interested in delivering to the Netflix dataengineers or anyone who would like to schedule a workflow with some external assets in it. Conclusions This new method available for Netflix dataengineers makes workflow management easier, more transparent and more reliable.
Some of the optimizations are prerequisites for a high-performance data warehouse. Sometimes DataEngineers write downstream ETLs on ingested data to optimize the data/metadata layouts to make other ETL processes cheaper and faster.
This is particularly important as we build out new functionality that relies on Pushy; a strong, stable infrastructure foundation allows our partners to continue to build on top of Pushy with confidence. KeyValue is an abstraction over the storage engine itself, which allows us to choose the best storage engine that meets our SLO needs.
Cloud Network Insight is a suite of solutions that provides both operational and analytical insight into the Cloud Network Infrastructure to address the identified problems. As with any sustainable engineering design, focusing on simplicity is very important.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Try the 30-day free trial!
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Try the 30-day free trial!
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Try the 30-day free trial!
by Shefali Vyas Dalal AWS re:Invent is a couple weeks away and our engineers & leaders are thrilled to be in attendance yet again this year! Netflix shares how Amazon EC2 Auto Scaling allows its infrastructure to automatically adapt to changing traffic patterns in order to keep its audience entertained and its costs on target.
by Shefali Vyas Dalal AWS re:Invent is a couple weeks away and our engineers & leaders are thrilled to be in attendance yet again this year! Netflix shares how Amazon EC2 Auto Scaling allows its infrastructure to automatically adapt to changing traffic patterns in order to keep its audience entertained and its costs on target.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Try the 30-day free trial!
In such a data intensive environment, making key business decisions such as running marketing and sales campaigns, logistic planning, financial analysis and ad targeting require deriving insights from these data. However, the datainfrastructure to collect, store and process data is geared toward developers (e.g.,
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Try the 30-day free trial!
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Try the 30-day free trial!
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Try the 30-day free trial!
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Try the 30-day free trial!
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Try the 30-day free trial!
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Try the 30-day free trial!
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
This year’s growth in Python usage was buoyed by its increasing popularity among data scientists and machine learning (ML) and artificial intelligence (AI) engineers. Software architecture, infrastructure, and operations are each changing rapidly. Also: infrastructure and operations is trending up, while DevOps is trending down.
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Jules Damji discusses which infrastructure should be used for distributed fine-tuning and training, how to scale ML workloads, how to accommodate large models, and how can CPUs and GPUs be utilized? By Jules Damji
SUS206 Sustainability and AWS silicon — Kamran Khan AWS Senior Product Manager Inferential/Trainium/FPGA, David Chaiken Pinterest Chief Architect, and Paul Mazurkiewicz AWS Senior Principal Engineer. Excellent talk on the NOAA programs to share data and build communities around it.
In recent times, in order to gain valuable insights or to develop the data-driven products companies such as Netflix, Spotify, Uber, AirBnB have built internal data pipelines. If built correctly, data pipelines can offer strategic advantages to the business. It can be used to power new analytics, insight, and product features.
The GA is a follow-up to the earlier announcement of the development of the infrastructure. AWS recently announced the general availability (GA) of Amazon EC2 P5 instances powered by the latest NVIDIA H100 Tensor Core GPUs suitable for users that require high performance and scalability in AI/ML and HPC workloads. By Steef-Jan Wiggers
Since then Donna’s been bringing her expertise to Pulumi , a startup promising to make infrastructure automation much more friendly and less, well, YAML’ey. From dataengineering, to cost management, via conversations about team dynamics and architecture, we like to get involved with all-things-cloud-and-DevOps related at our clients.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content