This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Engineers from across the company came together to share best practices on everything from Data Processing Patterns to Building Reliable Data Pipelines. The result was a series of talks which we are now sharing with the rest of the DataEngineering community!
This article sets out to explore some of the essential tools required by organizations in the domain of dataengineering to efficiently improve data quality and triage/analyze data for effective business-centric machine learning analytics, reporting, and anomaly detection.
A summary of sessions at the first DataEngineering Open Forum at Netflix on April 18th, 2024 The DataEngineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our dataengineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
By Abhinaya Shetty , Bharath Mummadisetty At Netflix, our Membership and Finance DataEngineering team harnesses diverse data related to plans, pricing, membership life cycle, and revenue to fuel analytics, power various dashboards, and make data-informed decisions. Let’s dive in!
DataEngineers of Netflix?—?Interview Interview with Pallavi Phadnis This post is part of our “ DataEngineers of Netflix ” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Pallavi Phadnis is a Senior Software Engineer at Netflix.
In the data-driven landscape of today, automation has become indispensable across industries, not just to maximize efficiency but, more importantly, to ensure quality. This holds true for the critical field of dataengineering as well.
DataEngineers of Netflix?—?Interview Interview with Samuel Setegne Samuel Setegne This post is part of our “DataEngineers of Netflix” interview series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. What drew you to Netflix?
In an era characterized by an exponential increase in data generation, organizations must effectively leverage this wealth of information to maintain their competitive edge. As dataengineers, we are tasked with implementing these sophisticated solutions, ensuring organizations can derive actionable insights from vast datasets.
Every image you hover over isnt just a visual placeholder; its a critical data point that fuels our sophisticated personalization engine. Collecting raw impression events Filtering & Enriching Raw Impressions Once the raw impression events are queued, a stateless Apache Flink job takes charge, meticulously processing this data.
Maintaining Uber’s large-scale data warehouse comes with an operational cost in terms of ETL functions and storage. In our experience, optimizing for operational efficiency requires answering one key question: for which tables does the maintenance cost supersede utility?
This is a guest post by Eunice Do , DataEngineer at TripleLift , a technology company leading the next generation of programmatic advertising. The system is the data pipeline at TripleLift. TripleLift is an adtech company, and like most companies in this industry, we deal with high volumes of data on a daily basis.
Building and Scaling Data Lineage at Netflix to Improve Data Infrastructure Reliability, and Efficiency By: Di Lin , Girish Lingappa , Jitender Aswani Imagine yourself in the role of a data-inspired decision maker staring at a metric on a dashboard about to make a critical business decision but pausing to ask a question?—?“Can
Netflix’s engineering culture is predicated on Freedom & Responsibility, the idea that everyone (and every team) at Netflix is entrusted with a core responsibility and they are free to operate with freedom to satisfy their mission. In the Efficiency space, our data teams focus on transparency and optimization.
As organizations continue to adopt multicloud strategies, the complexity of these environments grows, increasing the need to automate cloud engineering operations to ensure organizations can enforce their policies and architecture principles. This requires significant dataengineering efforts, as well as work to build machine-learning models.
Operational automation–including but not limited to, auto diagnosis, auto remediation, auto configuration, auto tuning, auto scaling, auto debugging, and auto testing–is key to the success of modern data platforms. the retry success probability) and compute cost efficiency (i.e., Multi-objective optimizations.
It also improves the engineering productivity by simplifying the existing pipelines and unlocking the new patterns. We will show how we are building a clean and efficient incremental processing solution (IPS) by using Netflix Maestro and Apache Iceberg. Users configure the workflow to read the data in a window (e.g.
We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits. This article will list some of the use cases of AutoOptimize, discuss the design principles that help enhance efficiency, and present the high-level architecture.
Welcome to the first post in our exciting series on mastering offline data pipeline's best practices, focusing on the potent combination of Apache Airflow and data processing engines like Hive and Spark. Working together, they form the backbone of many modern dataengineering solutions.
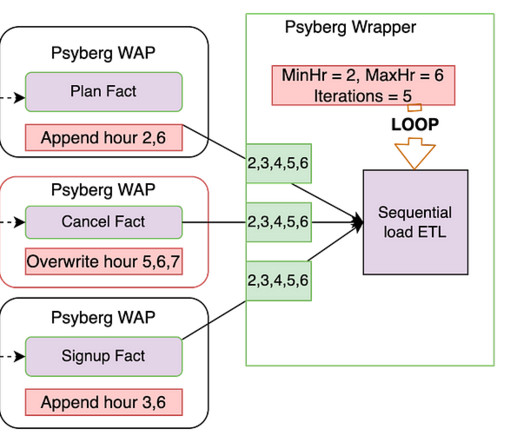
By Abhinaya Shetty , Bharath Mummadisetty In the inaugural blog post of this series, we introduced you to the state of our pipelines before Psyberg and the challenges with incremental processing that led us to create the Psyberg framework within Netflix’s Membership and Finance dataengineering team.
By focusing solely on updates and avoiding reprocessing of data based on a fixed lookback window, both Stateless and Stateful Data Processing maintain a minimal change footprint. This approach ensures data processing is both efficient and accurate.
—?and what the role entails by Julie Beckley & Chris Pham This Q&A provides insights into the diverse set of skills, projects, and culture within Data Science and Engineering (DSE) at Netflix through the eyes of two team members: Chris Pham and Julie Beckley. Photo from a team curling offsite?—?There’s There’s us to the right!
by Shefali Vyas Dalal AWS re:Invent is a couple weeks away and our engineers & leaders are thrilled to be in attendance yet again this year! Technology advancements in content creation and consumption have also increased its data footprint. Please stop by our “Living Room” for an opportunity to connect or reconnect with Netflixers.
At Netflix, our data scientists span many areas of technical specialization, including experimentation, causal inference, machine learning, NLP, modeling, and optimization. Together with data analytics and dataengineering, we comprise the larger, centralized Data Science and Engineering group.
Real-Time Data Processing Bottlenecks Edge computing is lauded for enabling real-time data processing, but scaling such systems without delays remains a hurdle. As data streams grow in complexity, processing efficiency can decline. Inconsistent network performance affecting data synchronization.
Without these integrations, projects would be stuck at the prototyping stage, or they would have to be maintained as outliers outside the systems maintained by our engineering teams, incurring unsustainable operational overhead. Importantly, all the use cases were engineered by practitioners themselves.
Usability Netflix is a data-driven company, where key decisions are driven by data insights, from the pixel color used on the landing page to the renewal of a TV-series. Data scientists, engineers, non-engineers, and even content producers all run their data pipelines to get the necessary insights.
With these clear benefits, we continued to build out this functionality for more devices, enabling the same efficiency wins. It was very efficient, but it had a set job size, requiring manual intervention if we wanted to horizontally scale it, and it required manual intervention when rolling out a new version.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. How to screen candidates efficiently, effectively, and without bias.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. How to screen candidates efficiently, effectively, and without bias.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. How to screen candidates efficiently, effectively, and without bias.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. How to screen candidates efficiently, effectively, and without bias.
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
by Shefali Vyas Dalal AWS re:Invent is a couple weeks away and our engineers & leaders are thrilled to be in attendance yet again this year! Technology advancements in content creation and consumption have also increased its data footprint. We’ve compiled our speaking events below so you know what we’ve been working on.
by Shefali Vyas Dalal AWS re:Invent is a couple weeks away and our engineers & leaders are thrilled to be in attendance yet again this year! Technology advancements in content creation and consumption have also increased its data footprint. We’ve compiled our speaking events below so you know what we’ve been working on.
In recent times, in order to gain valuable insights or to develop the data-driven products companies such as Netflix, Spotify, Uber, AirBnB have built internal data pipelines. If built correctly, data pipelines can offer strategic advantages to the business. It can be used to power new analytics, insight, and product features.
Recently, Google announced A2 Virtual Machines (VMs)' general availability based on the NVIDIA Ampere A100 Tensor Core GPUs in Compute Engine. By Steef-Jan Wiggers.
Airflow provides rich scheduling and execution semantics enabling dataengineers to easily define complex pipelines, running at regular intervals. Workflow platforms have emerged as a crucial component for these companies, enabling them to orchestrate complex tasks, automate processes, and ensure efficient collaboration.
SUS206 Sustainability and AWS silicon — Kamran Khan AWS Senior Product Manager Inferential/Trainium/FPGA, David Chaiken Pinterest Chief Architect, and Paul Mazurkiewicz AWS Senior Principal Engineer. Excellent talk on the NOAA programs to share data and build communities around it.
A unified data management (UDM) system combines the best of data warehouses, data lakes, and streaming without expensive and error-prone ETL. It offers reliability and performance of a data warehouse, real-time and low-latency characteristics of a streaming system, and scale and cost-efficiency of a data lake.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content