This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A summary of sessions at the first DataEngineering Open Forum at Netflix on April 18th, 2024 The DataEngineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our dataengineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
By Abhinaya Shetty , Bharath Mummadisetty At Netflix, our Membership and Finance DataEngineering team harnesses diverse data related to plans, pricing, membership life cycle, and revenue to fuel analytics, power various dashboards, and make data-informed decisions. We will talk about this shortly.
DataEngineers of Netflix?—?Interview Interview with Kevin Wylie This post is part of our “DataEngineers of Netflix” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Kevin, what drew you to dataengineering?
DataEngineers of Netflix?—?Interview Interview with Pallavi Phadnis This post is part of our “ DataEngineers of Netflix ” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Pallavi Phadnis is a Senior Software Engineer at Netflix.
DataEngineers of Netflix?—?Interview Interview with Samuel Setegne Samuel Setegne This post is part of our “DataEngineers of Netflix” interview series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. What drew you to Netflix?
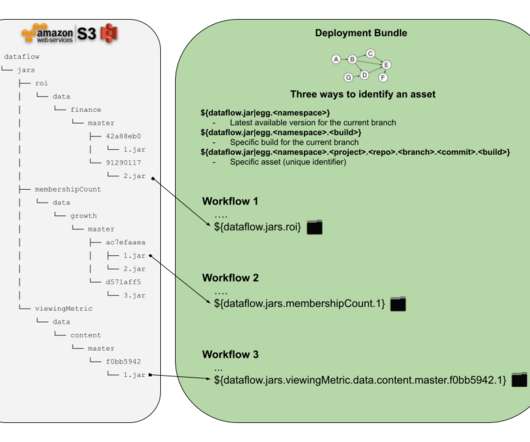
Dataflow Dataflow is a command line utility built to improve experience and to streamline the data pipeline development at Netflix. The most commonly used one is dataflow project , which helps folks in managing their data pipeline repositories through creation, testing, deployment and few other activities. test_sparksql_write.py
Full ownership often means building new data pipelines, navigating complex schemas and large data sets, developing or improving metrics for business performance, and creating intuitive visualizations and dashboards?—?always Others have grown into new areas as part of their professional development at Netflix.
As a micro-service owner, a Netflix engineer is responsible for its innovation as well as its operation, which includes making sure the service is reliable, secure, efficient and performant. How can we develop templated detection modules (rules- and ML-based) and data streams to increases speed of development?
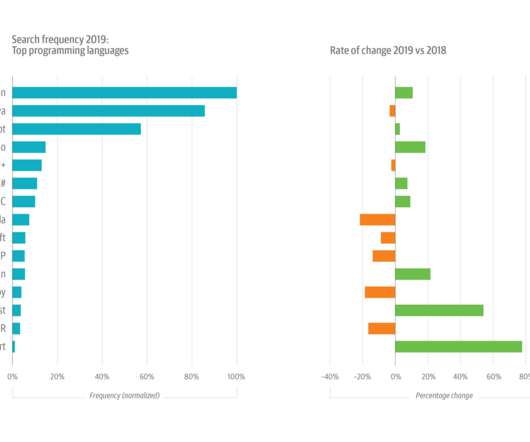
There’s plenty of security risks for business executives, sysadmins, DBAs, developers, etc., The laggard use case was Python-based web development frameworks, which grew by just 3% in usage, year over year. there’s a Python library for virtually anything a developer or data scientist might need to do. to be wary of.
We adopted the following mission statement to guide our investments: “Provide a complete and accurate data lineage system enabling decision-makers to win moments of truth.” Nonetheless, Netflix data landscape (see below) is complex and many teams collaborate effectively for sharing the responsibility of our data system management.
Let’s define some requirements that we are interested in delivering to the Netflix dataengineers or anyone who would like to schedule a workflow with some external assets in it. Conclusions This new method available for Netflix dataengineers makes workflow management easier, more transparent and more reliable.
Developing automation takes time. This requires significant dataengineering efforts, as well as work to build machine-learning models. To learn more about how Dynatrace drives more efficient IT operations by automating IT processes, read the ebook, Developing an AIOps strategy for cloud observability. Read eBook now!
At this scale, we can gain a significant amount of performance and cost benefits by optimizing the storage layout (records, objects, partitions) as the data lands into our warehouse. Some of the optimizations are prerequisites for a high-performance data warehouse.
At Netflix, our data scientists span many areas of technical specialization, including experimentation, causal inference, machine learning, NLP, modeling, and optimization. Together with data analytics and dataengineering, we comprise the larger, centralized Data Science and Engineering group.
This event is designed to help senior developers navigate their immediate development challenges, focusing exclusively on the technical aspects that matter right now. InfoQ is delighted to announce a new two-day conference, InfoQ Dev Summit Boston 2024, taking place June 24-25, 2024. By Artenisa Chatziou
including bug bounty, pentesting, PSIRT (product security incident response), security reviews, and developer security education?—?via As the team skews towards more software engineering focused talent, ramping up to support the shared Appsec-focused on-call has been challenging. via a shared on-call rotation.
Occasionally, these use cases involve terabytes of data, so we have to pay attention to performance. By targeting @titus, Metaflow tasks benefit from these battle-hardened features out of the box, with no in-depth technical knowledge or engineering required from the ML engineers or data scientist end.
These challenges are currently addressed in suboptimal and less cost efficient ways by individual local teams to fulfill the needs, such as Lookback: This is a generic and simple approach that dataengineers use to solve the data accuracy problem. Users configure the workflow to read the data in a window (e.g.
3:15pm-4:15pm OPN 209 Netflix’s application deployment at scale Andy Glover , Director Delivery Engineering & Paul Roberts, AWS Abstract : Spinnaker is an open-source continuous-delivery platform created by Netflix to improve its developers’ efficiency and reduce the time it takes to get an application into production.
Since memory management is not something one usually associates with classification problems, this blog focuses on formulating the problem as an ML problem and the dataengineering that goes along with it. for us at Netflix, this is a combination of the device type, app session ID and software development kit version (SDK version).
History & motivation There were two main motivating use cases that drove Pushy’s initial development and usage. These pain points coincided with the introduction of KeyValue, which was a new offering from the CDE team that is roughly “HashMap as a service” for Netflix developers.
increasing at > 100% a year, the need for a scalable data workflow orchestrator has become paramount for Netflix’s business needs. After perusing the current landscape of workflow orchestrators, we decided to develop a next generation system that can scale horizontally to spread the jobs across the cluster consisting of 100’s of nodes.
The one thing I don’t see, and the one thing that more than anything else captures the value in Agile, is the ongoing conversation between the customer (however that’s conceived) and the developer. Agile is not, and never was, about getting developers to write software faster. This is important. Neckbeards? Geeks and nerds?
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc. Please apply here. Join more than 265,000 other learners.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc. Please apply here. Join more than 265,000 other learners.
You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc. Please apply here. Join more than 265,000 other learners.
You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc. Please apply here. Try the 30-day free trial!
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
My work is typically developed in R or Python. I focus on improving experimentation methodology to test how well the newest files are working: do they need less bits to stream while providing a higher video quality? Do they cause less errors?
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc. Please apply here. Try the 30-day free trial!
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Source code is relatively less important compared to typical applications; the training data is what determines how the model behaves, and the training process is all about tweaking parameters in the application so that it delivers correct results most of the time. You need a repository for models and for the training data.
You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc. Please apply here. Join more than 300,000 other learners.
For efficient error handling, Netflix developed an error classification service, called Pensive, which leverages a rule-based classifier for error classification. To address these challenges, we have developed a new feature, called Auto Remediation , which integrates the rule-based classifier with an ML service.
Containers for local development and probably in UAT. Explore serverless functions to create Skills++: Induct Technical Architects, Developer Experience (DevX) 50-100 Engineers Focus: Finding new ways to add more value quickly for your customers by exploiting data. Test coverage (50-70%).
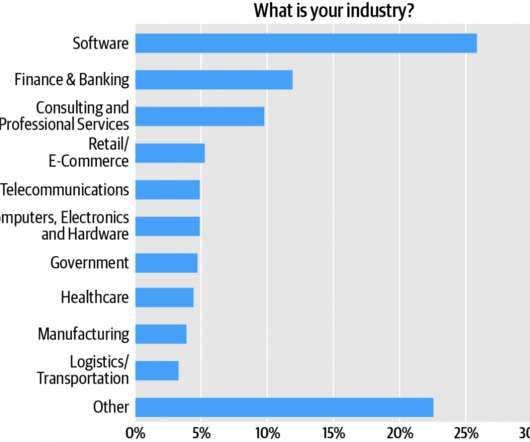
Adding architects and engineers, we see that roughly 55% of the respondents are directly involved in software development. Technical roles represented in the “Other” category include IT managers, dataengineers, DevOps practitioners, data scientists, systems engineers, and systems administrators.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content