This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A summary of sessions at the first DataEngineering Open Forum at Netflix on April 18th, 2024 The DataEngineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our dataengineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
DataEngineers of Netflix?—?Interview Interview with Dhevi Rajendran Dhevi Rajendran This post is part of our “DataEngineers of Netflix” interview series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix.
Finally, imagine yourself in the role of a data platform reliability engineer tasked with providing advanced lead time to data pipeline (ETL) owners by proactively identifying issues upstream to their ETL jobs. Design a flexible data model ? —?Represent Enable seamless integration?—?
In this article, Rogerio Robetti discusses the challenges in auto-scaling stateful storage systems and proposes an opinionated design solution to automatically scale up (vertical) and scale out (horizontal) from a single node up to several nodes in a cluster with minimum configuration and interference of the operator. By Rogerio Robetti
We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits. This article will list some of the use cases of AutoOptimize, discuss the design principles that help enhance efficiency, and present the high-level architecture.
4:45pm-5:45pm NFX 202 A day in the life of a Netflix Engineer Dave Hahn , SRE Engineering Manager Abstract : Netflix is a large, ever-changing ecosystem serving millions of customers across the globe through cloud-based systems and a globally distributed CDN. We explore all the systems necessary to make and stream content from Netflix.
Whether in analyzing A/B tests, optimizing studio production, training algorithms, investing in content acquisition, detecting security breaches, or optimizing payments, well structured and accurate data is foundational. Users configure the workflow to read the data in a window (e.g. data arrives too late to be useful).
As Big data and ML became more prevalent and impactful, the scalability, reliability, and usability of the orchestrating ecosystem have increasingly become more important for our data scientists and the company. Another dimension of scalability to consider is the size of the workflow.
Inconsistent network performance affecting data synchronization. Introduce scalable microservices architectures to distribute computational loads efficiently. Key issues include: A shortage of edge-native dataengineers and architects. Limited understanding of edge-specific use cases among traditional IT teams.
The Machine Learning Platform (MLP) team at Netflix provides an entire ecosystem of tools around Metaflow , an open source machine learning infrastructure framework we started, to empower data scientists and machine learning practitioners to build and manage a variety of ML systems.
has hours of system design content. They also do live system design discussions every week. Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! Learn to balance architecture trade-offs and designscalable enterprise-level software.
has hours of system design content. They also do live system design discussions every week. Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! Learn to balance architecture trade-offs and designscalable enterprise-level software.
has hours of system design content. They also do live system design discussions every week. Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! Learn to balance architecture trade-offs and designscalable enterprise-level software.
Level up on in-demand technologies and prep for your interviews on Educative.io, featuring popular courses like the bestselling Grokking the System Design Interview. Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Try the 30-day free trial!
Grokking the System Design Interview is a popular course on Educative.io (taken by 20,000+ people) that's widely considered the best System Design interview resource on the Internet. Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes.
has hours of system design content. They also do live system design discussions every week. Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! Created by former senior-level AWS engineers of 15 years. Who's Hiring?
Grokking the System Design Interview is a popular course on Educative.io (taken by 20,000+ people) that's widely considered the best System Design interview resource on the Internet. Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes.
Level up on in-demand technologies and prep for your interviews on Educative.io, featuring popular courses like the bestselling Grokking the System Design Interview. Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Try the 30-day free trial!
Level up on in-demand technologies and prep for your interviews on Educative.io, featuring popular courses like the bestselling Grokking the System Design Interview. Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Try the 30-day free trial!
Level up on in-demand technologies and prep for your interviews on Educative.io, featuring popular courses like the bestselling Grokking the System Design Interview. Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Try the 30-day free trial!
Zendesk reduced its data storage costs by over 80% by migrating from DynamoDB to a tiered storage solution using MySQL and S3. The company considered different storage technologies and decided to combine the relational database and the object store to strike a balance between querybility and scalability while keeping the costs down.
Level up on in-demand technologies and prep for your interviews on Educative.io, featuring popular courses like the bestselling Grokking the System Design Interview. Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Try the 30-day free trial!
Level up on in-demand technologies and prep for your interviews on Educative.io, featuring popular courses like the bestselling Grokking the System Design Interview. Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Try the 30-day free trial!
has hours of system design content. They also do live system design discussions every week. Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! Who's Hiring? InterviewCamp.io Try out their platform. Cool Products and Services.
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Level up on in-demand technologies and prep for your interviews on Educative.io, featuring popular courses like the bestselling Grokking the System Design Interview. Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Try the 30-day free trial!
Level up on in-demand technologies and prep for your interviews on Educative.io, featuring popular courses like the bestselling Grokking the System Design Interview. Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Try the 30-day free trial!
4:45pm-5:45pm NFX 202 A day in the life of a Netflix Engineer Dave Hahn , SRE Engineering Manager Abstract : Netflix is a large, ever-changing ecosystem serving millions of customers across the globe through cloud-based systems and a globally distributed CDN. We explore all the systems necessary to make and stream content from Netflix.
4:45pm-5:45pm NFX 202 A day in the life of a Netflix Engineer Dave Hahn , SRE Engineering Manager Abstract : Netflix is a large, ever-changing ecosystem serving millions of customers across the globe through cloud-based systems and a globally distributed CDN. We explore all the systems necessary to make and stream content from Netflix.
Uber uses Presto, an open-source distributed SQL query engine, to provide analytics across several data sources, including Apache Hive, Apache Pinot, MySQL, and Apache Kafka. To improve its performance, Uber engineers explored the advantages of dealing with quick queries, a.k.a.
AWS recently announced the general availability (GA) of Amazon EC2 P5 instances powered by the latest NVIDIA H100 Tensor Core GPUs suitable for users that require high performance and scalability in AI/ML and HPC workloads. The GA is a follow-up to the earlier announcement of the development of the infrastructure. By Steef-Jan Wiggers
Unfortunately, building data pipelines remains a daunting, time-consuming, and costly activity. Not everyone is operating at Netflix or Spotify scale dataengineering function. Often companies underestimate the necessary effort and cost involved to build and maintain data pipelines.
This event is designed to help senior developers navigate their immediate development challenges, focusing exclusively on the technical aspects that matter right now. InfoQ is delighted to announce a new two-day conference, InfoQ Dev Summit Boston 2024, taking place June 24-25, 2024. By Artenisa Chatziou
The DAG Model and the Misconception Data pipelines are commonly implemented as Directed Acyclic Graphs (DAGs), where data flows through a series of processing steps, with each step represented as a node and the dependencies between steps represented as edges.
James Munro discusses ArcticDB and the practicalities of building a performant time-series datastore and why transactions, particularly the Isolation in ACID is just not worth it. By James Munro
He specifically delved into Venice DB, the NoSQL data store used for feature persistence. At the QCon London 2024 conference, Félix GV from LinkedIn discussed the AI/ML platform powering the company’s products. By Rafal Gancarz
Canva evaluated different data massaging solutions for its Product Analytics Platform, including the combination of AWS SNS and SQS, MKS, and Amazon KDS, and eventually chose the latter, primarily based on its much lower costs. The company compared many aspects of these solutions, like performance, maintenance effort, and cost.
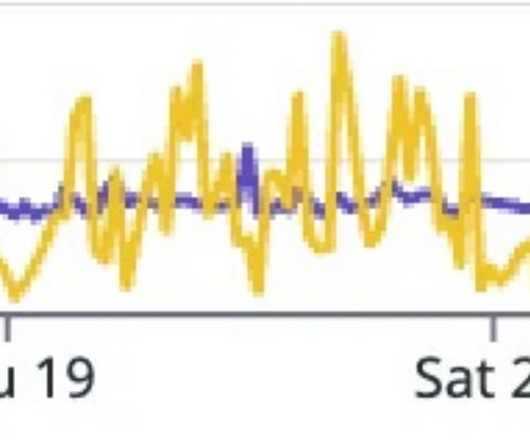
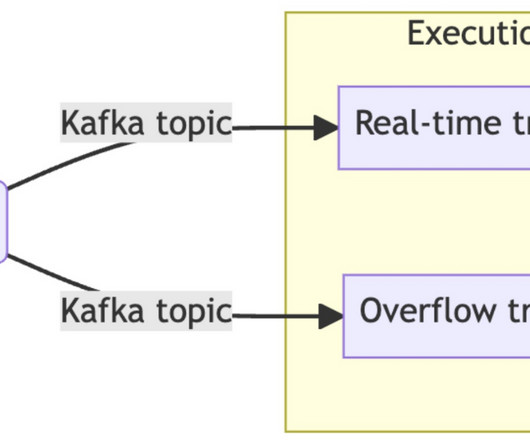
HubSpot adopted routing messages over multiple Kafka topics (called swimlanes) for the same producer to avoid the build-up in the consumer group lag and prioritize the processing of real-time traffic.
LinkedIn introduced Couchbase as a centralized caching tier for scaling member profile reads to handle increasing traffic that has outgrown their existing database cluster. The new solution achieved over 99% hit rate, helped reduce tail latencies by more than 60% and costs by 10% annually. By Rafal Gancarz
Microsoft recently announced the general availability (GA) of Azure Managed Lustre, a managed file system for high-performance computing (HPC) and AI workloads. By Steef-Jan Wiggers
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content