This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By Abhinaya Shetty , Bharath Mummadisetty At Netflix, our Membership and Finance DataEngineering team harnesses diverse data related to plans, pricing, membership life cycle, and revenue to fuel analytics, power various dashboards, and make data-informed decisions. What is late-arriving data? Let’s dive in!
A summary of sessions at the first DataEngineering Open Forum at Netflix on April 18th, 2024 The DataEngineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our dataengineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
DataEngineers of Netflix?—?Interview Interview with Pallavi Phadnis This post is part of our “ DataEngineers of Netflix ” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Pallavi Phadnis is a Senior Software Engineer at Netflix.
DataEngineers of Netflix?—?Interview Interview with Kevin Wylie This post is part of our “DataEngineers of Netflix” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Kevin, what drew you to dataengineering?
by Jun He , Yingyi Zhang , and Pawan Dixit Incremental processing is an approach to process new or changed data in workflows. The key advantage is that it only incrementally processesdata that are newly added or updated to a dataset, instead of re-processing the complete dataset.
DataEngineers of Netflix?—?Interview Interview with Dhevi Rajendran Dhevi Rajendran This post is part of our “DataEngineers of Netflix” interview series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix.
DataEngineers of Netflix?—?Interview Interview with Samuel Setegne Samuel Setegne This post is part of our “DataEngineers of Netflix” interview series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. What drew you to Netflix?
Obviously not all tools are made with the same use case in mind, so we are planning to add more code samples for other (than classical batch ETL) dataprocessing purposes, e.g. Machine Learning model building and scoring. The main workflow definition file holds the logic of a single run, in this case one day-worth of data.
Finally, imagine yourself in the role of a data platform reliability engineer tasked with providing advanced lead time to data pipeline (ETL) owners by proactively identifying issues upstream to their ETL jobs. Design a flexible data model ? —?Represent Enable seamless integration?—? push or pull.
There are several benefits of such optimizations like saving on storage, faster query time, cheaper downstream processing, and an increase in developer productivity by removing additional ETLs written only for query performance improvement. Some of the optimizations are prerequisites for a high-performance data warehouse.
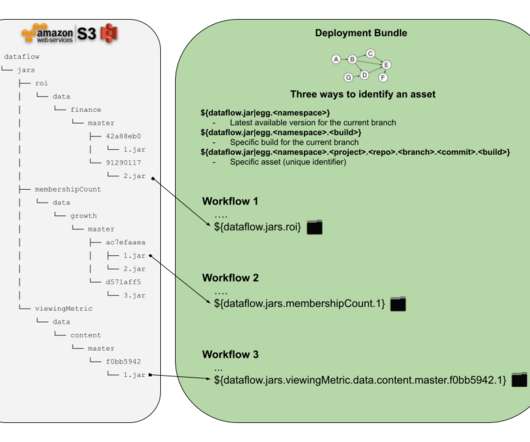
see “data pipeline” Intro The problem of managing scheduled workflows and their assets is as old as the use of cron daemon in early Unix operating systems. The design of a cron job is simple, you take some system command, you pick the schedule to run it on and you are done. workflow ?—?see Example: 0 0 * * MON /home/alice/backup.sh
At Netflix, our data scientists span many areas of technical specialization, including experimentation, causal inference, machine learning, NLP, modeling, and optimization. Together with data analytics and dataengineering, we comprise the larger, centralized Data Science and Engineering group.
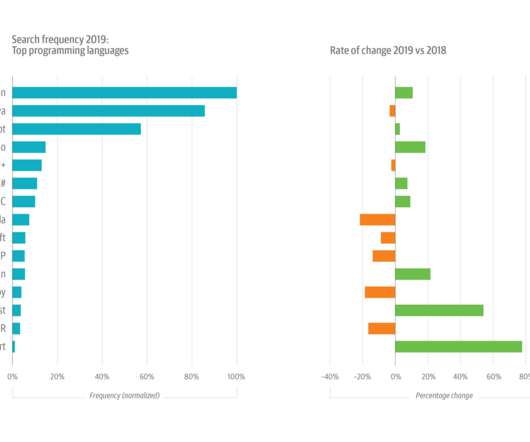
This year’s growth in Python usage was buoyed by its increasing popularity among data scientists and machine learning (ML) and artificial intelligence (AI) engineers. The shift to cloud native design is transforming both software architecture and infrastructure and operations. Coincidence?
Edge computing has transformed how businesses and industries process and manage data. By bringing computation closer to the data source, edge-based deployments reduce latency, enhance real-time capabilities, and optimize network bandwidth. Leverage tiered storage systems that dynamically offload data based on priority.
The Machine Learning Platform (MLP) team at Netflix provides an entire ecosystem of tools around Metaflow , an open source machine learning infrastructure framework we started, to empower data scientists and machine learning practitioners to build and manage a variety of ML systems.
4:45pm-5:45pm NFX 202 A day in the life of a Netflix Engineer Dave Hahn , SRE Engineering Manager Abstract : Netflix is a large, ever-changing ecosystem serving millions of customers across the globe through cloud-based systems and a globally distributed CDN.
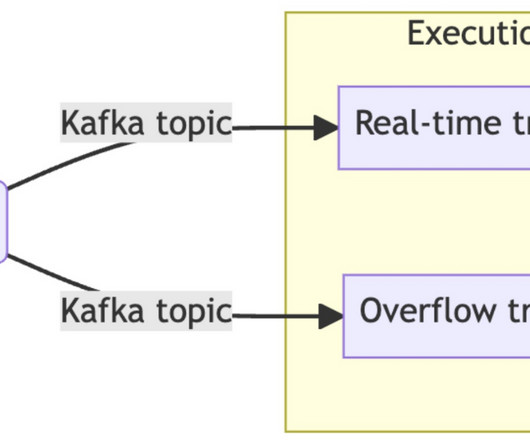
HubSpot adopted routing messages over multiple Kafka topics (called swimlanes) for the same producer to avoid the build-up in the consumer group lag and prioritize the processing of real-time traffic.
The voice service then constructs a message for the device and places it on the message queue, which is then processed and sent to Pushy to deliver to the device. To support this growth, we’ve revisited Pushy’s past assumptions and design decisions with an eye towards both Pushy’s future role and future stability.
In the data domain, it is common to have a super large number of jobs within a single workflow. For example, a workflow to backfill hourly data for the past five years can lead to 43800 jobs (24 * 365 * 5), each of which processesdata for an hour. All the requests are processed via distributed queues for message passing.
Level up on in-demand technologies and prep for your interviews on Educative.io, featuring popular courses like the bestselling Grokking the System Design Interview. Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Try the 30-day free trial!
has hours of system design content. They also do live system design discussions every week. Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! Learn to balance architecture trade-offs and design scalable enterprise-level software.
Level up on in-demand technologies and prep for your interviews on Educative.io, featuring popular courses like the bestselling Grokking the System Design Interview. Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Try the 30-day free trial!
has hours of system design content. They also do live system design discussions every week. Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! Learn to balance architecture trade-offs and design scalable enterprise-level software.
has hours of system design content. They also do live system design discussions every week. Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! Learn to balance architecture trade-offs and design scalable enterprise-level software.
has hours of system design content. They also do live system design discussions every week. Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! The result is a process that doesn't get you the best employees you could.
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Level up on in-demand technologies and prep for your interviews on Educative.io, featuring popular courses like the bestselling Grokking the System Design Interview. Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Try the 30-day free trial!
Level up on in-demand technologies and prep for your interviews on Educative.io, featuring popular courses like the bestselling Grokking the System Design Interview. Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Try the 30-day free trial!
has hours of system design content. They also do live system design discussions every week. Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! Created by former senior-level AWS engineers of 15 years. Who's Hiring?
In this way, no human intervention is required in the remediation process. We used feature hashing to process the non-numeric values because they come from a high cardinality and dynamic set of values. Multi-objective optimizations. Auto Remediation generates recommendations by considering both performance (i.e., user name).
4:45pm-5:45pm NFX 202 A day in the life of a Netflix Engineer Dave Hahn , SRE Engineering Manager Abstract : Netflix is a large, ever-changing ecosystem serving millions of customers across the globe through cloud-based systems and a globally distributed CDN.
4:45pm-5:45pm NFX 202 A day in the life of a Netflix Engineer Dave Hahn , SRE Engineering Manager Abstract : Netflix is a large, ever-changing ecosystem serving millions of customers across the globe through cloud-based systems and a globally distributed CDN.
When a project is going off track because some requirement wasn’t understood properly, you need to fix that as soon as possible—not after a year-long development process. This has to do with the concept of bounded context from Domain Driven Design.). When processes change, who wins, who loses, and why? Coincidence?
In the era of big data and complex dataprocessing, data pipelines have emerged as a popular solution for managing and manipulating data. They provide a systematic approach to extract, transform, and load (ETL) data from various sources, enabling organizations to derive valuable insights.
In recent times, in order to gain valuable insights or to develop the data-driven products companies such as Netflix, Spotify, Uber, AirBnB have built internal data pipelines. If built correctly, data pipelines can offer strategic advantages to the business. Depending on frameworks, dataprocessing units (a.k.a
A common theme across all these trends is to remove the complexity by simplifying data management as a whole. In 2018, we anticipate that ETL will either lose relevance or the ETL process will disintegrate and be consumed by new data architectures. Unified data management architecture.
One thing stand-out to me is being intentional and practical about your engineering organisation design. First and foremost, being intentional about organisation design requires good and honest discussions about all possible option. Specialisation could be around products, business process, or technologies. Certainly not.
Developing Extract–transform–load (ETL) workflow is a time-consuming activity yet a very important component of data warehousing process. The process to develop ETL workflow is often ad-hoc, complex, trial and error based. It has been suggested that formal modeling of ETL process can alleviate most of these pain points.
Canva evaluated different data massaging solutions for its Product Analytics Platform, including the combination of AWS SNS and SQS, MKS, and Amazon KDS, and eventually chose the latter, primarily based on its much lower costs. The company compared many aspects of these solutions, like performance, maintenance effort, and cost.
Udacity Udacity provides nanodegree programs on all automation languages like C++, Machine Learning, Dataengineer, Robotics and more. They have diploma courses in Software Testing, Introduction to Python, Diploma in Design Thinking, Diploma in Python Programming. Test Management Improving the Test Process.
This type of talk is close to my heart since I strongly feel we need to do a lot of deep thinking (and subsequent knowledge sharing) of design and architecture patterns with Serverless. Over the past 9 months John’s been helping our friends at Beyondsoft with their new open-source Serverless data lake project?—?
Our data scientists faced numerous challenges in our previous infrastructure. Complex business logic was embedded directly into the ETL pipelines by dataengineers. In order to replicate results, scientists had to delve deep into the data, code, and documentation.
Previously, I wrote about Amazon QuickSight , a new service targeted at business users that aims to simplify the process of deriving insights from a wide variety of data sources quickly, easily, and at a low cost. Put simply, data is not always readily available and accessible to organizational end users.
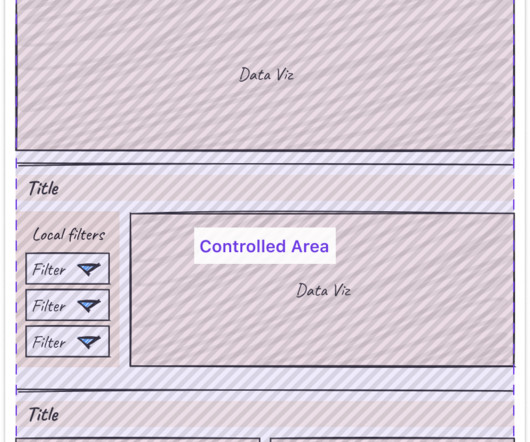
Dashboard DesignTips Rina Chang , SusieLu What is design, and why does it matter? Often people think design is about how things look, but design is actually about how things work. Everything is designed, because were all making choices about how things work, but not everything is designed well.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content