This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits. This article will list some of the use cases of AutoOptimize, discuss the design principles that help enhance efficiency, and present the high-level architecture.
To support this growth, we’ve revisited Pushy’s past assumptions and design decisions with an eye towards both Pushy’s future role and future stability. KeyValue is an abstraction over the storage engine itself, which allows us to choose the best storage engine that meets our SLO needs.
Edge computing has transformed how businesses and industries process and manage data. By bringing computation closer to the data source, edge-based deployments reduce latency, enhance real-time capabilities, and optimize network bandwidth. As data streams grow in complexity, processing efficiency can decline.
4:45pm-5:45pm NFX 202 A day in the life of a Netflix Engineer Dave Hahn , SRE Engineering Manager Abstract : Netflix is a large, ever-changing ecosystem serving millions of customers across the globe through cloud-based systems and a globally distributed CDN. We explore all the systems necessary to make and stream content from Netflix.
Whether in analyzing A/B tests, optimizing studio production, training algorithms, investing in content acquisition, detecting security breaches, or optimizing payments, well structured and accurate data is foundational. Users configure the workflow to read the data in a window (e.g. data arrives too late to be useful).
The Machine Learning Platform (MLP) team at Netflix provides an entire ecosystem of tools around Metaflow , an open source machine learning infrastructure framework we started, to empower data scientists and machine learning practitioners to build and manage a variety of ML systems.
4:45pm-5:45pm NFX 202 A day in the life of a Netflix Engineer Dave Hahn , SRE Engineering Manager Abstract : Netflix is a large, ever-changing ecosystem serving millions of customers across the globe through cloud-based systems and a globally distributed CDN. We explore all the systems necessary to make and stream content from Netflix.
4:45pm-5:45pm NFX 202 A day in the life of a Netflix Engineer Dave Hahn , SRE Engineering Manager Abstract : Netflix is a large, ever-changing ecosystem serving millions of customers across the globe through cloud-based systems and a globally distributed CDN. We explore all the systems necessary to make and stream content from Netflix.
One downside of the iterative design of the optimizer is that any bottleneck can block completion and cause a timeout, which we initially observed in a non-trivial number of cases. Upon further profiling, we found that most of the latency came from the candidate generated step (i.e.,
The new solution achieved over 99% hit rate, helped reduce tail latencies by more than 60% and costs by 10% annually. LinkedIn introduced Couchbase as a centralized caching tier for scaling member profile reads to handle increasing traffic that has outgrown their existing database cluster. By Rafal Gancarz
Unfortunately, building data pipelines remains a daunting, time-consuming, and costly activity. Not everyone is operating at Netflix or Spotify scale dataengineering function. Often companies underestimate the necessary effort and cost involved to build and maintain data pipelines.
A unified data management (UDM) system combines the best of data warehouses, data lakes, and streaming without expensive and error-prone ETL. It offers reliability and performance of a data warehouse, real-time and low-latency characteristics of a streaming system, and scale and cost-efficiency of a data lake.
He specifically delved into Venice DB, the NoSQL data store used for feature persistence. At the QCon London 2024 conference, Félix GV from LinkedIn discussed the AI/ML platform powering the company’s products. By Rafal Gancarz
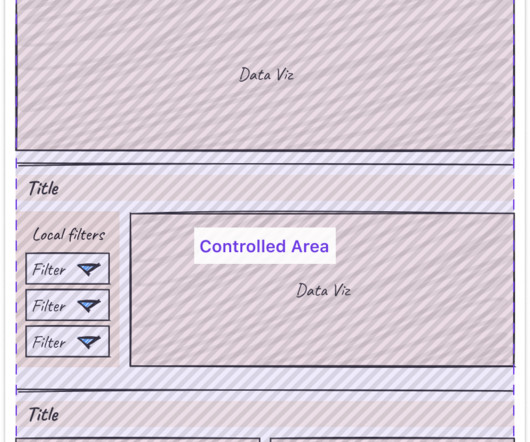
Dashboard DesignTips Rina Chang , SusieLu What is design, and why does it matter? Often people think design is about how things look, but design is actually about how things work. Everything is designed, because were all making choices about how things work, but not everything is designed well.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content