This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A summary of sessions at the first DataEngineering Open Forum at Netflix on April 18th, 2024 The DataEngineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our dataengineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
By Abhinaya Shetty , Bharath Mummadisetty At Netflix, our Membership and Finance DataEngineering team harnesses diverse data related to plans, pricing, membership life cycle, and revenue to fuel analytics, power various dashboards, and make data-informed decisions.
DataEngineers of Netflix?—?Interview Interview with Kevin Wylie This post is part of our “DataEngineers of Netflix” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Kevin, what drew you to dataengineering?
DataEngineers of Netflix?—?Interview Interview with Pallavi Phadnis This post is part of our “ DataEngineers of Netflix ” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Pallavi Phadnis is a Senior Software Engineer at Netflix.
DataEngineers of Netflix?—?Interview Interview with Dhevi Rajendran Dhevi Rajendran This post is part of our “DataEngineers of Netflix” interview series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix.
DataEngineers of Netflix?—?Interview Interview with Samuel Setegne Samuel Setegne This post is part of our “DataEngineers of Netflix” interview series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. What drew you to Netflix?
Once identified, … The post Less is More: EngineeringData Warehouse Efficiency with Minimalist Design appeared first on Uber Engineering Blog. In our experience, optimizing for operational efficiency requires answering one key question: for which tables does the maintenance cost supersede utility?
The main workflow definition file holds the logic of a single run, in this case one day-worth of data. This logic consists of the following parts: DDL code, table metadata information, data transformation and a few audit steps. It’s designed to run for a single date, and meant to be called from the daily or backfill workflows.
Now, imagine yourself in the role of a software engineer responsible for a micro-service which publishes data consumed by few critical customer facing services (e.g. You are about to make structural changes to the data and want to know who and what downstream to your service will be impacted.
At Netflix, our data scientists span many areas of technical specialization, including experimentation, causal inference, machine learning, NLP, modeling, and optimization. Together with data analytics and dataengineering, we comprise the larger, centralized Data Science and Engineering group.
In this article, Rogerio Robetti discusses the challenges in auto-scaling stateful storage systems and proposes an opinionated design solution to automatically scale up (vertical) and scale out (horizontal) from a single node up to several nodes in a cluster with minimum configuration and interference of the operator. By Rogerio Robetti
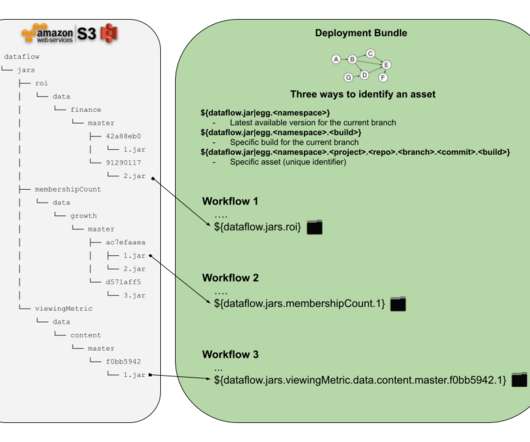
see “data pipeline” Intro The problem of managing scheduled workflows and their assets is as old as the use of cron daemon in early Unix operating systems. The design of a cron job is simple, you take some system command, you pick the schedule to run it on and you are done. workflow ?—?see Example: 0 0 * * MON /home/alice/backup.sh
We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits. This article will list some of the use cases of AutoOptimize, discuss the design principles that help enhance efficiency, and present the high-level architecture.
It also improves the engineering productivity by simplifying the existing pipelines and unlocking the new patterns. Users configure the workflow to read the data in a window (e.g. The window is set based on users’ domain knowledge so that users have a high confidence that the late arriving data will be included or will not matter (i.e.
by Shefali Vyas Dalal AWS re:Invent is a couple weeks away and our engineers & leaders are thrilled to be in attendance yet again this year! Technology advancements in content creation and consumption have also increased its data footprint. We’ve compiled our speaking events below so you know what we’ve been working on.
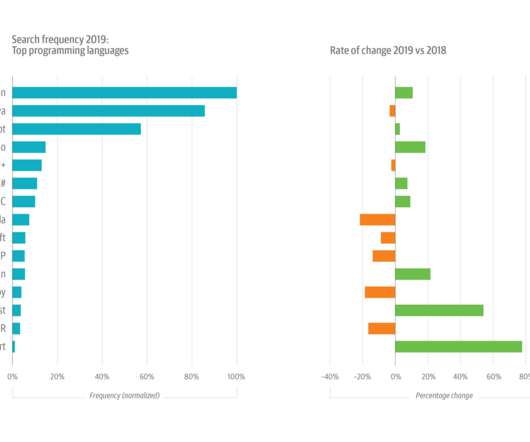
This year’s growth in Python usage was buoyed by its increasing popularity among data scientists and machine learning (ML) and artificial intelligence (AI) engineers. The shift to cloud native design is transforming both software architecture and infrastructure and operations. Interestingly, R itself continues to decline.
The Machine Learning Platform (MLP) team at Netflix provides an entire ecosystem of tools around Metaflow , an open source machine learning infrastructure framework we started, to empower data scientists and machine learning practitioners to build and manage a variety of ML systems.
The evolution of your technology architecture should depend on the size, culture, and skill set of your engineering organization. There are no hard-and-fast rules to figure out interdependency between technology architecture and engineering organization but below is what I think can really work well for product startup.
Uber uses Presto, an open-source distributed SQL query engine, to provide analytics across several data sources, including Apache Hive, Apache Pinot, MySQL, and Apache Kafka. To improve its performance, Uber engineers explored the advantages of dealing with quick queries, a.k.a.
Usability Netflix is a data-driven company, where key decisions are driven by data insights, from the pixel color used on the landing page to the renewal of a TV-series. Data scientists, engineers, non-engineers, and even content producers all run their data pipelines to get the necessary insights.
The rule-based classifier classifies job errors based on a set of predefined rules and provides insights for schedulers to decide whether to retry the job and for engineers to diagnose and remediate the job failure. Rule Execution Engine is responsible for matching the collected logs against a set of predefined rules.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Stateful JavaScript Apps. Generous free tier.
Talent and Expertise Shortages The rapid evolution of edge computing technologies has outpaced the availability of skilled professionals who can design, implement, and manage these systems effectively. Key issues include: A shortage of edge-native dataengineers and architects. High costs of training and retaining talent.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Cool Products and Services. Try the 30-day free trial!
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Stateful JavaScript Apps. Generous free tier.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Cool Products and Services. Try the 30-day free trial!
has hours of system design content. They also do live system design discussions every week. Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! this is going to be a challenging journey for any backend engineer! Who's Hiring?
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Cool Products and Services. Try the 30-day free trial!
has hours of system design content. They also do live system design discussions every week. Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! this is going to be a challenging journey for any backend engineer! Who's Hiring?
has hours of system design content. They also do live system design discussions every week. Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! this is going to be a challenging journey for any backend engineer! Who's Hiring?
has hours of system design content. They also do live system design discussions every week. Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! this is going to be a challenging journey for any backend engineer! Who's Hiring?
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Cool Products and Services. Try the 30-day free trial!
Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Cool Products and Services. Try the 30-day free trial!
When it comes to organising engineering teams, a popular view has been to organise your teams based on either Spotify's agile model (i.e. One thing stand-out to me is being intentional and practical about your engineering organisation design. squads, chapters, tribes, and guilds) or simply follow Amazon's two-pizza team model.
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Cool Products and Services. Try the 30-day free trial!
has hours of system design content. They also do live system design discussions every week. Scrapinghub is hiring a Senior Software Engineer (Big Data/AI). this is going to be a challenging journey for any backend engineer! this is going to be a challenging journey for any backend engineer! Who's Hiring?
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Cool Products and Services. Try the 30-day free trial!
Sisu Data is looking for machine learning engineers who are eager to deliver their features end-to-end, from Jupyter notebook to production, and provide actionable insights to businesses based on their first-party, streaming, and structured relational data. Apply here. Cool Products and Services. Try the 30-day free trial!
To support this growth, we’ve revisited Pushy’s past assumptions and design decisions with an eye towards both Pushy’s future role and future stability. KeyValue is an abstraction over the storage engine itself, which allows us to choose the best storage engine that meets our SLO needs.
by Shefali Vyas Dalal AWS re:Invent is a couple weeks away and our engineers & leaders are thrilled to be in attendance yet again this year! Technology advancements in content creation and consumption have also increased its data footprint. We’ve compiled our speaking events below so you know what we’ve been working on.
by Shefali Vyas Dalal AWS re:Invent is a couple weeks away and our engineers & leaders are thrilled to be in attendance yet again this year! Technology advancements in content creation and consumption have also increased its data footprint. We’ve compiled our speaking events below so you know what we’ve been working on.
In this tutorial, you are going to learn about QuestDB SQL extensions which prove to be very useful with time-series data. Using some sample data sets, you will learn how designated timestamps work and how to use extended SQL syntax to write queries on time-series data.
As with any sustainable engineeringdesign, focusing on simplicity is very important. We found ourselves needing to hold more than 120 thousand messages in flight at a time in order to keep up with the volumes of files. Requirements There are multiple ways you can solve this problem and many technologies to choose from.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content