This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Dataengineering projects often require the setup and management of complex infrastructures that support data processing, storage, and analysis. In this article, we will explore the benefits of leveraging IaC for dataengineering projects and provide detailed implementation steps to get started.
Building and Scaling Data Lineage at Netflix to Improve DataInfrastructure Reliability, and Efficiency By: Di Lin , Girish Lingappa , Jitender Aswani Imagine yourself in the role of a data-inspired decision maker staring at a metric on a dashboard about to make a critical business decision but pausing to ask a question?—?“Can
Central engineering teams enable this operational model by reducing the cognitive burden on innovation teams through solutions related to securing, scaling and strengthening (resilience) the infrastructure. All these micro-services are currently operated in AWS cloud infrastructure.
Optionally, this step can use the Write-Audit-Publish pattern to ensure that data is correct before it is made available to the rest of the company. See example below: - template: id: wap type: wap tables: - ${CATALOG}/${DATABASE}/${TABLE} write_jobs: - job: id: write type: Spark spark: script: $S3{./src/sparksql_write.sql}
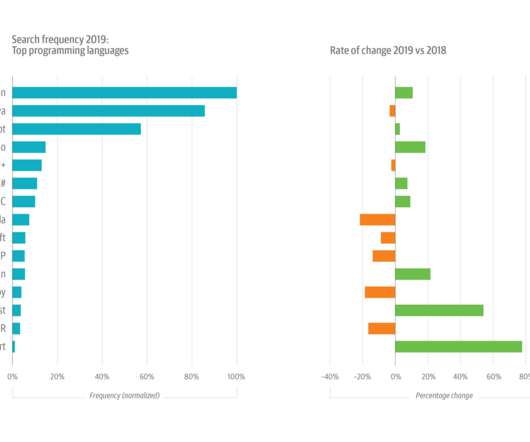
This year’s growth in Python usage was buoyed by its increasing popularity among data scientists and machine learning (ML) and artificial intelligence (AI) engineers. Software architecture, infrastructure, and operations are each changing rapidly. Also: infrastructure and operations is trending up, while DevOps is trending down.
Some of the optimizations are prerequisites for a high-performance data warehouse. Sometimes DataEngineers write downstream ETLs on ingested data to optimize the data/metadata layouts to make other ETL processes cheaper and faster. Both automatic (event-driven) as well as manual (ad-hoc) optimization.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
However, the datainfrastructure to collect, store and process data is geared toward developers (e.g., In AWS’ quest to enable the best data storage options for engineers, we have built several innovative database solutions like Amazon RDS, Amazon RDS for Aurora, Amazon DynamoDB, and Amazon Redshift.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
As I mentioned, we live in a world where massive volumes of data are being generated, every day, from connected devices, websites, mobile apps, and customer applications running on top of AWS infrastructure. Put simply, data is not always readily available and accessible to organizational end users.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content