This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Financial dataengineering in SAS involves the management, processing, and analysis of financial data using the various tools and techniques provided by the SAS software suite. Here are some key aspects of financial dataengineering in SAS: 1.
Engineers from across the company came together to share best practices on everything from Data Processing Patterns to Building Reliable Data Pipelines. The result was a series of talks which we are now sharing with the rest of the DataEngineering community! In this video, Sr. In this video, Sr.
This article sets out to explore some of the essential tools required by organizations in the domain of dataengineering to efficiently improve data quality and triage/analyze data for effective business-centric machine learning analytics, reporting, and anomaly detection.
By Abhinaya Shetty , Bharath Mummadisetty At Netflix, our Membership and Finance DataEngineering team harnesses diverse data related to plans, pricing, membership life cycle, and revenue to fuel analytics, power various dashboards, and make data-informed decisions.
A summary of sessions at the first DataEngineering Open Forum at Netflix on April 18th, 2024 The DataEngineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our dataengineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
DataEngineers of Netflix?—?Interview Interview with Kevin Wylie This post is part of our “DataEngineers of Netflix” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Kevin, what drew you to dataengineering?
DataEngineers of Netflix?—?Interview Interview with Pallavi Phadnis This post is part of our “ DataEngineers of Netflix ” series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. Pallavi Phadnis is a Senior Software Engineer at Netflix.
DataEngineers of Netflix?—?Interview Interview with Dhevi Rajendran Dhevi Rajendran This post is part of our “DataEngineers of Netflix” interview series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. DataEngineers of Netflix?—?Interview
DataEngineers of Netflix?—?Interview Interview with Samuel Setegne Samuel Setegne This post is part of our “DataEngineers of Netflix” interview series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. What drew you to Netflix?
Dataengineering projects often require the setup and management of complex infrastructures that support data processing, storage, and analysis. In this article, we will explore the benefits of leveraging IaC for dataengineering projects and provide detailed implementation steps to get started.
This holds true for the critical field of dataengineering as well. As organizations gather and process astronomical volumes of data, manual testing is no longer feasible or reliable. This comprehensive guide takes an in-depth look at automated testing in the dataengineering domain.
It's midnight in the dim and cluttered office of The New York Times, currently serving as the "situation room." A powerful surge of traffic is inevitable. During every major election, the wave would crest and crash against our overwhelmed systems before receding, allowing us to assess the damage.
As dataengineers, we are tasked with implementing these sophisticated solutions, ensuring organizations can derive actionable insights from vast datasets. This article explores the intricacies of vector search using Elasticsearch , focusing on effective techniques and best practices to optimize performance.
This article discusses the challenges and best practices of data migration when transferring on-premise data to the cloud. The article will also explore the role of dataengineering in ensuring successful data transfer and integration and different approaches to data migration.
The data community is striving to incorporate the core concepts of engineering rigor found in software communities but still has further to go. This is achieved through practices like Infrastructure as Code for deployments, automated testing, application observability, and end-to-end application lifecycle ownership.
This is a guest post by Eunice Do , DataEngineer at TripleLift , a technology company leading the next generation of programmatic advertising. The system is the data pipeline at TripleLift. TripleLift is an adtech company, and like most companies in this industry, we deal with high volumes of data on a daily basis.
The Engineer enjoys making data available by piping it in from new sources in optimal ways, building robust data models, prototyping systems, and doing project-specific engineering.
Data lineage, an automated visualization of the relationships for how data flows across tables and other data assets, is a must-have in the dataengineering toolbox.
Welcome to the first post in our exciting series on mastering offline data pipeline's best practices, focusing on the potent combination of Apache Airflow and data processing engines like Hive and Spark. Working together, they form the backbone of many modern dataengineering solutions.
By Abhinaya Shetty , Bharath Mummadisetty In the inaugural blog post of this series, we introduced you to the state of our pipelines before Psyberg and the challenges with incremental processing that led us to create the Psyberg framework within Netflix’s Membership and Finance dataengineering team.
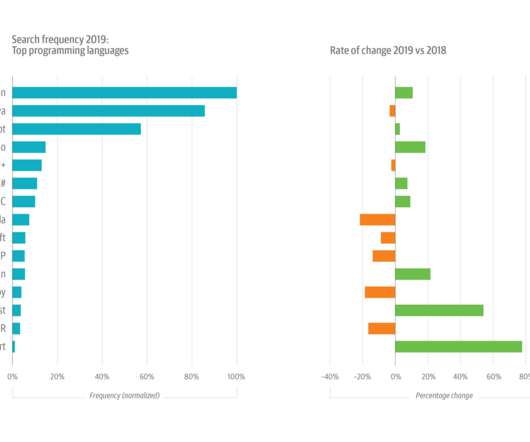
The results for data-related topics are both predictable and—there’s no other way to put it—confusing. Starting with dataengineering, the backbone of all data work (the category includes titles covering data management, i.e., relational databases, Spark, Hadoop, SQL, NoSQL, etc.). This follows a 3% drop in 2018.
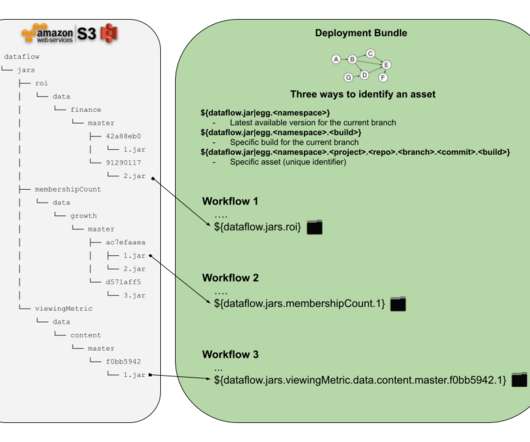
Let’s define some requirements that we are interested in delivering to the Netflix dataengineers or anyone who would like to schedule a workflow with some external assets in it. Conclusions This new method available for Netflix dataengineers makes workflow management easier, more transparent and more reliable.
From a dataengineer's point of view, financial risk management is a series of data analysis activities on financial data. The financial sector imposes its unique requirements on dataengineering.
Some of the optimizations are prerequisites for a high-performance data warehouse. Sometimes DataEngineers write downstream ETLs on ingested data to optimize the data/metadata layouts to make other ETL processes cheaper and faster.
While our engineering teams have and continue to build solutions to lighten this cognitive load (better guardrails, improved tooling, …), data and its derived products are critical elements to understanding, optimizing and abstracting our infrastructure. Give us a holler if you are interested in a thought exchange.
We adopted the following mission statement to guide our investments: “Provide a complete and accurate data lineage system enabling decision-makers to win moments of truth.” Please share your experience by adding your comments below and stay tuned for more on data lineage at Netflix in the follow up blog posts. .
This requires significant dataengineering efforts, as well as work to build machine-learning models. While automating IT processes without integrated AIOps can create challenges, the approach to artificial intelligence itself can also introduce potential issues. AI that is based on machine learning needs to be trained.
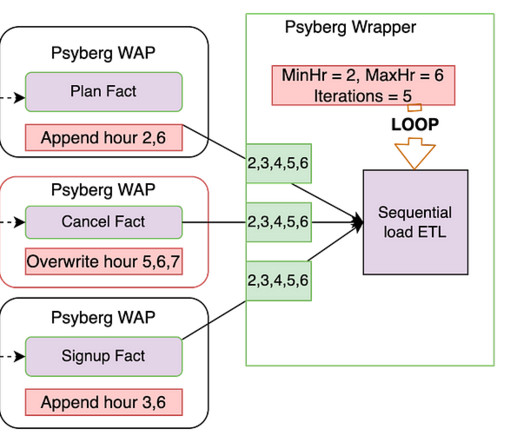
This helps overwrite data only when required and minimizes unnecessary reprocessing. As seen above, by chaining these Psyberg workflows, we could automate the catchup for late-arriving data from hours 2 and 6. The DataEngineer does not need to perform any manual intervention in this case and can thus focus on more important things!
Problem Statement In DataEngineering , the data/log collection is a challenging task for high-volume sources. Compliance Reporting: SIEM solutions help organizations meet regulatory compliance requirements by providing reporting and audit trail capabilities.
These challenges are currently addressed in suboptimal and less cost efficient ways by individual local teams to fulfill the needs, such as Lookback: This is a generic and simple approach that dataengineers use to solve the data accuracy problem. Users configure the workflow to read the data in a window (e.g.
At Netflix, our data scientists span many areas of technical specialization, including experimentation, causal inference, machine learning, NLP, modeling, and optimization. Together with data analytics and dataengineering, we comprise the larger, centralized Data Science and Engineering group.
Every image you hover over isnt just a visual placeholder; its a critical data point that fuels our sophisticated personalization engine. Part 1: Creating the Source of Truth for Impressions By: TulikaBhatt Imagine scrolling through Netflix, where each movie poster or promotional banner competes for your attention.
Since memory management is not something one usually associates with classification problems, this blog focuses on formulating the problem as an ML problem and the dataengineering that goes along with it. Some nuances while creating this dataset come from the on-field domain knowledge of our engineers.
Key issues include: A shortage of edge-native dataengineers and architects. Talent and Expertise Shortages The rapid evolution of edge computing technologies has outpaced the availability of skilled professionals who can design, implement, and manage these systems effectively. High costs of training and retaining talent.
Our focus has been on improving overall security assurance as opposed to just vulnerability prevention. We are now expanding this approach to more parts of our ecosystem.
1:45pm-2:45pm NFX 201 More Data Science with less engineering: ML Infrastructure Ville Tuulos , Machine Learning Infrastructure Engineering Manager Abstract : Netflix is known for its unique culture that gives an extraordinary amount of freedom to individual engineers and data scientists.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Our intuitive software allows dataengineers to maintain pipelines without writing code, and lets analysts gain access to data in minutes instead of months.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content