This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It’s not just about collecting data or where it’s processed, [but] it’s taking that data and adding context to it so we can deliver answers and automation at scale.” The post Using modern observability to chart a course to successful digital transformation appeared first on Dynatrace news.
Unrealized optimization potential of business processes due to monitoring gaps Imagine a retail company facing gaps in its business process monitoring due to disparate data sources. Due to separated systems that handle different parts of the process, the view of the process is fragmented.
Organizations choose data-driven approaches to maximize the value of their data, achieve better business outcomes, and realize cost savings by improving their products, services, and processes. Data is then dynamically routed into pipelines for further processing. Commitment to privacy.
In addition to service-level monitoring, certain services within the OpenTelemetry demo application expose process-level metrics, such as CPU and memory consumption, number of threads, or heap size for services written in different languages. This query confirms the suspicion that a particular product might be wrong.
Acceptance, of course, is not guaranteed, but its always worth a try! OpenTelemetry provides us with a standard for generating, collecting, and emitting telemetry, and we have existing tooling that leverages OTel data to help us understand work processes and workflows. Its also quite a bit smaller, and much cozier.
And the evolution not only has called for modern testing strategies and tools but a detailed-oriented process with the inclusion of test methodologies. However, the only thing that defines the success or failure of a test strategy is the precise selection of tools, technology, and a suitable methodology to aid the entire QA process.
A lack of automation and standardization often results in a labour-intensive process across post-production and VFX with a lot of dependencies that introduce potential human errors and security risks. What if we started charting a course to break free from many of these technical limitations and found ways to enhance creativity?
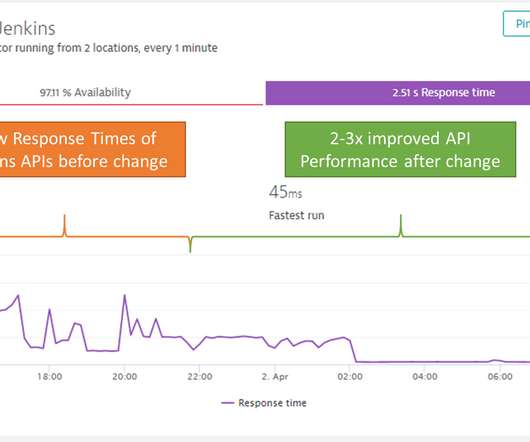
Besides a lot of memory being allocated by core Jenkins components, there was one allocation that stuck out; over the course of the analyzed 14 hours, 557 million KXmlParser objects got initialized (call to constructor) allocating 1.62TB (yes – that is Terabyte) of memory. Step #4 – JDK 11 thread leak.
Your one-stop shop for discovering, learning, and activating monitoring Dynatrace Hubacts as the central entry point to the Dynatrace platform, simplifying the onboarding process for new customers and helping existing customers stay updated with the latest features. Of course, seeing is believing.
These blog posts, published over the course of this year, span a huge feature set comprising Davis 2.0, Enrich technical root-cause data with domain and/or business process-related information by ingesting external, third-party events into Davis. Key benefits of the Dynatrace Davis 2.0 AI causation engine. We opened up the Davis 2.0
AI and DevOps, of course The C suite is also betting on certain technology trends to drive the next chapter of digital transformation: artificial intelligence and DevOps. According to IDC, AI technology will be inserted into the processes and products of at least 90% of new enterprise apps by 2025. And according to Statista , $2.4
The second major concern I want to discuss is around the data processing chain. The four stages of data processing. That brings me to the four stages of data processing which is another way of looking at the data processing chain. Four stages of data processing with a costly tool switch. Lost and rebuilt context.
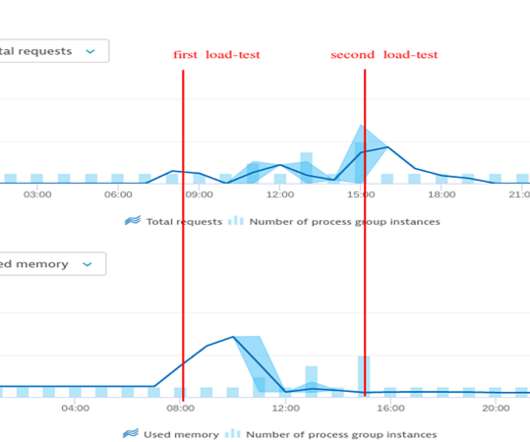
We were in the process of developing a new feature and wanted to make sure it could handle the expected load behavior. However, to be 100% sure we fixed the memory leak for good, we had to dig deeper and investigate the event broker process and its critical health metrics provided by the Dynatrace OneAgent. And of course: no more OOMs.
Of course, you can also create your own custom alerts based on any metric displayed on a dashboard. Of course this extension also comes with preconfigured alerts. Of course, these extensions are just a first step towards full observability for the Kubernetes control plane. What’s next?
Of course, this requires a VM that provides rock-solid isolation, and in AWS Lambda, this is the Firecracker microVM. In this case, as the provisioning life cycle diagram shows, the worker node has to be provisioned with the given Lambda function, which does, of course, take some time. The virtual CPU is turned off.
Here, you can define the template for your event and describe all essential information for the subsequent process. Of course, you always have the option to reopen an anomaly detector directly in Notebooks, where all configuration settings are carried over. We’re, of course, highly interested in your feedback.
The implications of software performance issues and outages have a significantly broader impact than in the past—with the potential to negatively impact revenue, customer experiences, patient outcomes, and, of course, brand reputation. Ideally, resiliency plans would lead to complete prevention.
The aforementioned principles have, of course, a major impact on the overall architecture. As a result, we created Grail with three different building blocks, each serving a special duty: Ingest and process. Ingest and process with Grail. Work with different and independent data types. Grail architectural basics. Retain data.
We’re proud to say that Davis CoPilot is multilingual: you can ask questions and get answers in many different languages, including French, Spanish, German, Portuguese, Chinese, Japanese, and, of course, English. The conversational interface provides step-by-step guidance, making the onboarding process smoother and more efficient.
Of course, development teams need to understand how their code behaves in production and whether any issues need to be fixed. The app scans all incoming logs for various patterns and uses DQL (Dynatrace Query Language) to collect context like hosts, other processes, and traces for each potential problem.
Process Improvements (50%) The allocation for process improvements is devoted to automation and continuous improvement SREs help to ensure that systems are scalable, reliable, and efficient. Streamlining the CI/CD process to ensure optimal efficiency. These tasks collectively ensure uninterrupted production service.
Of course, the most important aspect of activating Dynatrace on Kubernetes is the incalculable level of value the platform unlocks. Of course, everything is deployed using standard kubectl commands. Send metrics, logs, and traces to more than one Dynatrace environment. Solve common race condition problems related to node autoscaling.
Application modernization centers on bringing monolithic, on-premises applications — which IT teams usually update and maintain with waterfall development processes — into cloud architecture and release patterns. Of course, cloud application modernization solutions are not always focused on rebuilding from the ground up.
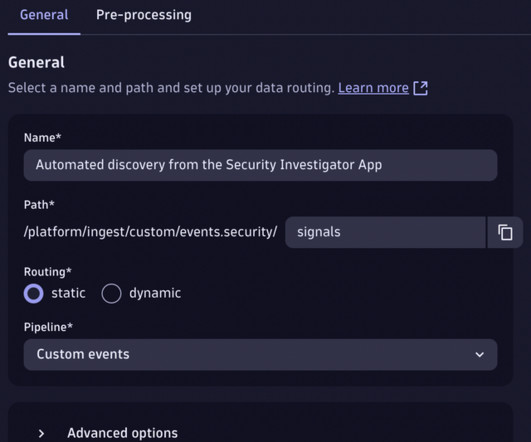
OpenPipeline allows you to create custom endpoints for data ingestion and process the events in the pipeline (for example, adding custom pipe-dependent fields to simplify data analysis in a later phase). Go to the Pre-processing tab and add a new processor with the type Add Fields. Ready to give this a shot yourself?
Of course, this example was easy to troubleshoot because were using a built-in failure simulation. The result of this query confirms our suspicion that there might be something wrong with a particular product, as all the errors seem to be caused by requests for a particular product ID: Figure 7.
Of course, you need to balance these opportunities with the business goals of the applications served by these hosts. And while these examples were resolved by just asking a few questions, in many cases, the answers are more elusive, requiring real-time and historical drill-downs into the processes and dependencies specific to each host.
Open a host, cluster, cloud service, or database view in one of these apps, and you immediately see logs alongside other relevant metrics, processes, SLOs, events, vulnerabilities, and data offered by the app. See for yourself Watch a demo of logs in context within various Dynatrace Apps in this Dynatrace University course.
Then after being introduced to the “World Wide Web” and new types of businesses and marketing opportunities, she shifted her career course to focus on technology. Intentional—and unintentional—mentoring Quackenbush also asked panelists about their mentors during their careers and whether mentorship was a formal process.
Over the course of several posts, we have seen how, as a result of the evolution of application architectures, new needs arise in the field of testing. While reflecting on this, I remembered that in my learning process, there was a lesson that stood out from the rest. We have focused on a specific one.
Of course, we have opinions on all of these, but we think those arent the most useful questions to ask right now. Weve taught this SDLC in a live course with engineers from companies like Netflix, Meta, and the US Air Force and recently distilled it into a free 10-email course to help teams apply it in practice.
If we look over the course of “Cyberweek” (below), no retailers experienced massive spikes indicating digital performance issues. In the past, I tried to understand where in the page-loading process was the majority of time spent. .” From click to fulfillment.
While there are still quite a lot of cases where it is still applicable, it needs to evolve into more sophisticated processes tightly integrated with development and other parts of performance engineering. Yes, the tools and process should be easier for non-experts to incorporate some performance testing into continuous development process.
Automatically get solutions to your host or process issues. To start the automated OneAgent troubleshooting workflow, just select Run OneAgent diagnostics on the affected host or process. Of course, you can delete the collected diagnostic data at any time. Diagnostic files ZIP. Monitoring state JSON. Monitored entities folder.
This creates a billing process that is simplified and straightforward. Together, Dynatrace and Azure are setting the course for success for enterprises tomorrow. Additionally, this integration centralizes billing, permitting users to receive a singular, all-inclusive bill for all Azure services, Dynatrace included.
This, of course, is exacerbated by the new Vitals announcement, whereby data from the Chrome User eXperience Report will be used to aid and influence rankings. Of course, the whole point of this article is performance profiling, so let’s move over to the Network tab. Everything is very Google centric. And now you do. Drop me a line!
Solution #2: Sanitize sensitive data at processing time. Naming rules are applied on every user action at processing time. And, of course, we’re constantly improving Dynatrace capabilities to ensure maximum visibility while honoring your end users’ privacy.
An excel sheet with services/process and such and who was responsible for them was already in existence but can get to be a pain to find and open it up, and hope that it was updated”. It said: Remember, keep your dashboards clean, simple, cool, and of course FUN! Chad came up with the perfect solution: Dynatrace Markup Tile !
Although Dynatrace can’t help with the manual remediation process itself , end-to-end observability, AI-driven analytics, and key Dynatrace features proved crucial for many of our customers’ remediation efforts. For example, a good course of action is knowing which impacted servers run mission-critical services and remediating those first.
If during the ticket handling another alert is raised this process repeats – but maybe with a different set of people who are working in parallel. This might be disputable, of course, but from an operations perspective one could question: “Are problems that only last for a couple of minutes worth investigating? ”
Dynatrace University is the team within Dynatrace that provides certification, self-paced micro-learning courses, and interactive instructor-led training. In the past, setting up all the hosts, clusters, and demo applications was a manual process that was very time consuming and error-prone. Dynatrace University. Automation.
Many business metrics may be captured through backend service call traces as transactions are processed. Business processes and events may be written to system logs or tracked and stored by an ERP solution, exposed via an application programming interface (API). Of course, customer experience goes beyond just online transactions.
The bank’s digital marketing team receives an alert from Adobe Analytics that there’s an anomaly in abandonment in their new account enrollment process. The best part is business teams don’t need to do anything different in their daily processes or change how they collect and manipulate data in Adobe.
Configs can of course also be used within yourflow. You can see the actual command and args that were sub-processed in the Metaboost Execution section below. Unlike parameters, configs can be used more widely in your flow code, particularly, they can be used in step or flow level decorators as well as to set defaults for parameters.
Of course, your customers expect both fast innovation and reliability. Process restarts (for example, JVM memory leaks) —Trigger a service restart or related actions for applications with underlying bug fixes that have been deprioritized or delayed. Dynatrace news.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content