This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
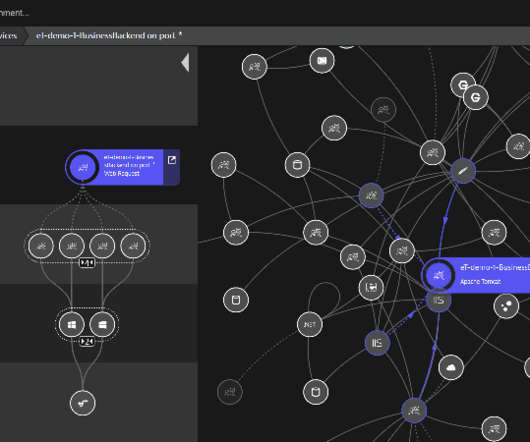
Therefore, they need an environment that offers scalable computing, storage, and networking. Hyperconverged infrastructure (HCI) is an IT architecture that combines servers, storage, and networking functions into a unified, software-centric platform to streamline resource management. What is hyperconverged infrastructure?
The implications of software performance issues and outages have a significantly broader impact than in the past—with the potential to negatively impact revenue, customer experiences, patient outcomes, and, of course, brand reputation. Ideally, resiliency plans would lead to complete prevention.
Of course, we could define a static threshold for each disk within the IT system. This release extends auto-adaptive baselines to the following generic metric sources, all in the context of Dynatrace Smartscape topology: Built-in OneAgent infrastructure monitoring metrics (host, process, network, etc.).
The basic premise of AIOps is: Automatically monitor and analyze large sets of data across applications, logs, hosts, services, networks, meta, and processes through to end users and outcomes. Dynatrace is a full-stack, all-in-one platform strategy vs a niche tool in a single category. So why are we sometimes omitted?
The obvious slow down impact happens when your network throughput becomes saturated. The longer it takes a page to load, the more likely the web server or load balancer is tied up serving those connections, leading to failed network requests. Do you have time and resources to go through your traditional tender practices?
The short answers are, of course ‘all the time’ and ‘everyone’, but this mutual disownership is a common reason why performance often gets overlooked. Of course, it is impossible to fix (or even find) every performance issue during the development phase. The reason I refer to this as Proactive testing is becasue we generally do.
Indeed, organizations view IT modernization and cloud computing as intertwined with their business strategy and COVID-19 recovery plans. According to a data from Dimensional Research, 95% of respondents say visibility problems have prompted an application or network performance issue. Cloud observability is a known problem for IT pros.
Artificial intelligence for IT operations, or AIOps, combines big data and machine learning to provide actionable insight for IT teams to shape and automate their operational strategy. It may have third-party calls, such as content delivery networks, or more complex requests to a back end or microservice-based application.
The crisis has emphasized the importance of having a strategy for maintaining stability and performance. For example, a good course of action is knowing which impacted servers run mission-critical services and remediating those first. The ripple effects on the global supply chain have been equally significant.
Sometimes, you need to check the availability of internal resources that aren’t accessible from outside your network. A private Synthetic location is a location in your private network infrastructure where you install a Synthetic-enabled ActiveGate. Of course, you can still configure private locations per environment.
Of course writes were much less common than reads, so I added a caching layer for reads, and that did the trick. A critical part of the code yellow was ensuring Google's sites would be fast for users across the globe, even if they had slow networks and low end devices.
Of course, more sophisticated tools may definitely do better job in creating a simple and intuitive interface (still providing a way to invoke more sophisticated functionality when needed). It definitely changes the performance engineering strategy and there are many questions to be sorted out eventually.
You will need a way of reaching the specific kind of client you would like to work with, and that needs a strategy that word of mouth cannot supply. Unfortunately, it is just as easy to get that strategy wrong, and doing so can prove a waste of time and money. Networking. Make it a video course instead. Large preview ).
At the limit, statically generated, edge delivered, and HTML-first pages look like the optimal strategy. Enabling dynamic commerce requires close integration between server and client, an optimized streaming and data fetch strategy, and a production platform that operates at scale.
Data replication strategies like full, incremental, and log-based replication are crucial for improving data availability and fault tolerance in distributed systems, while synchronous and asynchronous methods impact data consistency and system costs. By implementing data replication strategies, distributed storage systems achieve greater.
Over the course of this post, we will talk about our approach to this migration, the strategies that we employed, and the tools we built to support this. However, with the new microservice, even fetching this cached data needed to incur a network round trip, which added some latency. This meant that data that was static (e.g.
This article strips away the complexities, walking you through best practices, top tools, and strategies you’ll need for a well-defended cloud infrastructure. Of course, this is only true if the native solutions are used within the corresponding environment. These include alert fatigue, lack of context, and absence of strategy.
DRM-free, of course. Some of the biggest size savings and performance improvements can come through a better image optimization strategy. Packed with useful tips and techniques , the book has a sharp focus on practical application and longevity of your image optimization strategies. Image Content Delivery Networks. +.
A CDN (Content Delivery Network) is a network of geographically distributed servers that brings web content closer to where end users are located, to ensure high availability, optimized performance and low latency. M-CDN enables enacting a failover strategy with additional CDN providers that have not been impacted.
A performance budget as a mechanism for planning a web experience and preventing performance decay might consist of the following yardsticks: Overall page weight, Total number of HTTP requests, Page-load time on a particular mobile network, First Input Delay (FID). And of course, you need to host and deliver your images.
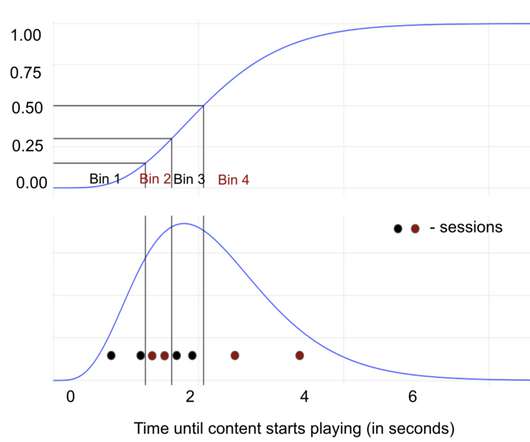
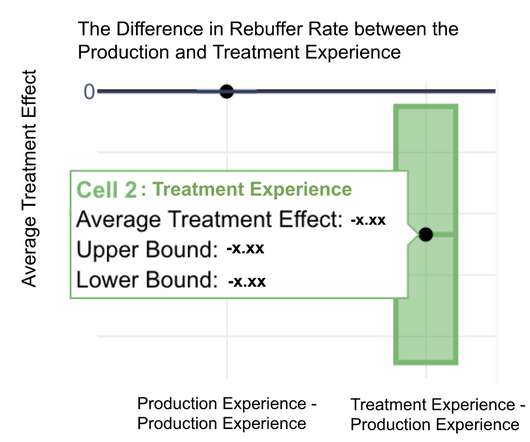
Suppose the encoding team develops more efficient encodes that improve video quality for members with the lowest quality (those streaming on low bandwidth networks). Your instinct might tell you this is caused by an unusually slow network, but you still become frustrated that the video quality is not perfect.
Suppose the encoding team develops more efficient encodes that improve video quality for members with the lowest quality (those streaming on low bandwidth networks). Your instinct might tell you this is caused by an unusually slow network, but you still become frustrated that the video quality is not perfect.
The secret sharer: evaluating and testing unintended memorization in neural networks Carlini et al., ” regardless of whether the search strategy is a greedy search, or a broader beam search. Of course, we’ll be dealing with random spaces much larger than the set of numbers from zero to nine.
DRM-free, of course. Some of the biggest size savings and performance improvements can come through a better image optimization strategy. Packed with useful tips and techniques , the book has a sharp focus on practical application and longevity of your image optimization strategies. Image Content Delivery Networks. +.
However, with today’s highly connected digital world, monitoring use cases expand to the services, processes, hosts, logs, networks, and of course, end-users that access these applications — including a company’s customers and employees. Mobile apps, websites, and business applications are typical use cases for monitoring.
Even though the network design for each data center is massively redundant, interruptions can still occur. No two zones are allowed to share low-level core dependencies, such as power supply or a core network. Of course, all sorts of automation immediately kick in to mitigate any impact to even that subset. Regional isolation.
Suppose the encoding team develops more efficient encodes that improve video quality for members with the lowest quality (those streaming on low bandwidth networks). Your instinct might tell you this is caused by an unusually slow network, but you still become frustrated that the video quality is not perfect.
Options 1 and 2 are of course the ‘scale out’ options, whereas option 3 is ‘scale up’. An IDS/IPS monitors network flows and matches incoming packets (or more strictly, Protocol Data Units, PDUs) against a set of rules. Increasing the amount of work we can do on a single unit. IDS/IPS requirements.
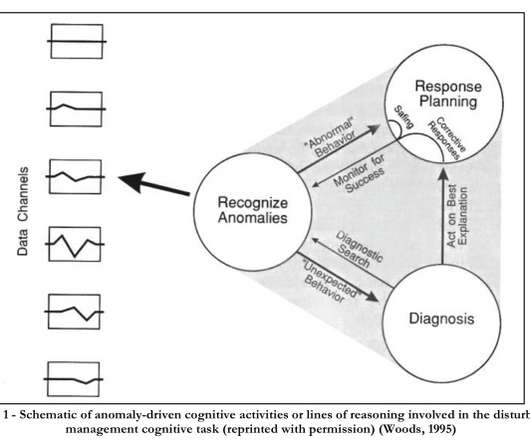
The Internet itself, over which these systems operate, is a dynamically distributed network spanning national borders and policies with no central coordinating agent. Moreover: Causality is complex and networked. if anomalies are recognised during the course of monitoring, those observation are fed back into response planning.
So far, it’s been a painless shift in power, which as Eric Matthes, author of Python Crash Course , argues, should come as no surprise, since “Guido has carried himself, and his role in the community, with such poise for so long.” Will Quarkus bear out its promise and the faith of its early fans?
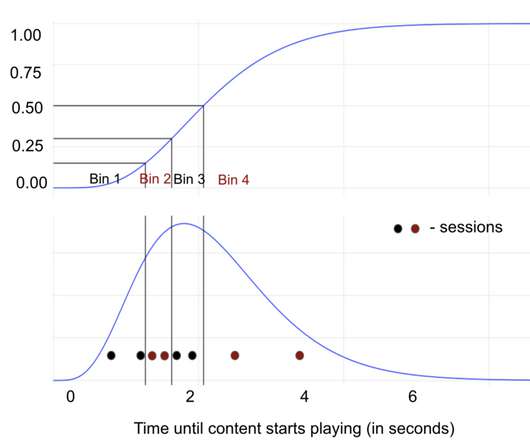
This post describes how the Netflix TVUI team implemented a robust strategy to quickly and easily detect performance anomalies before they are released?—?and Both of these metrics will fluctuate over the course of a test, so we post metric values at regular intervals throughout the test. so are power levels and network bandwidth.
A CDN (Content Delivery Network) is a network of geographically distributed servers that brings web content closer to where end users are located, to ensure high availability, optimized performance and low latency. M-CDN enables enacting a failover strategy with additional CDN providers that have not been impacted.
Souders presents his 14 rules throughout the course of the book while discussing the importance of front-end performance. Sounders, along with 8 expert contributors, expands upon the tips in the first book and offers best practices in JavaScript, network, and browser optimization. Web Performance in Action: Building Faster Web Pages.
Some sensory memory does stick, of course. In a 1999 study of workplace interruptions , groups of workers were subjected to various disruptions in the course of their day-to-day responsibilities. We can't consciously choose what information is stored in it, and we can't will it to last longer. (If Do delays really hurt productivity?
Key metrics here include memory requests, CPU requests, disk utilization, and network throughput. Automation has become an essential part of many organizations’ overall digital transformation strategies for cloud-native environments. Of course, not all automation is created equal. Control plane performance.
Physalia is designed to offer consistency and high-availability, even under network partitions. And, of course, it is designed to minimise the blast radius of any failures that do occur. Using Jepsen to make sure that API responses remained linearizable under network failure cases. Physalia in the large.
Next, we’ll look at how to set up servers and clients (that’s the hard part unless you’re using a content delivery network (CDN)). Using just a few (but still more than one), however, could nicely balance congestion growth with better performance, especially on high-speed networks. Servers and Networks. Network Configuration.
MySQL, PostgreSQL, MongoDB, MariaDB, and others each have unique strengths and weaknesses and should be evaluated based on factors such as scalability, compatibility, performance, security, data types, community support, licensing rules, compliance, and, of course, the all-important learning curve if your choice is new to you.
A telecom giant changing its outsourcing strategy to negotiate better terms with its service partners. Immerse yourself in an online network for questioning, collaborating and providing the support needed to guide successful continuous improvement journeys . A leading U.S healthcare leader doubling its feature velocity.
However, end-to-end testing does have some pitfalls that are cause for concern: End-to-end tests are slow and, thus, pose a significant hurdle in every continuous integration and continuous deployment (CI/CD) strategy. Cypress’ test runner is open-source, so it fits our product strategy. A selection of examples, recipes, and courses.
" Of course, no technology change happens in isolation, and at the same time NoSQL was evolving, so was cloud computing. VPC Endpoints give you the ability to control whether network traffic between your application and DynamoDB traverses the public Internet or stays within your virtual private cloud.
In that spirit, what we’re looking at in this article is focused more on the incremental wins and less on providing an exhaustive list or checklist of performance strategies. Using a network request inspector, I’m going to see if there’s anything we can remove via the Network panel in DevTools. Again, every millisecond counts.
The gotcha here is that, if your mobile experience isn’t optimized for various devices and network conditions, these customers will never appear in your analytics — just because your website or app will be barely usable on their devices, and so they are unlikely to return. Driving Business Metrics.
This is helpful for those on poor or expensive networks, so they don’t have to pay an exorbitant cost just to visit your website. However, countless research (including the stats for our own site here, and others by the likes of Alex Russell ) has shown that Android devices are the platform of choice for poorer countries with slower networks.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content