This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Compare Latency. On average, ScaleGrid achieves almost 30% lower latency over DigitalOcean for the same deployment configurations. ScaleGrid provides 30% more storage on average vs. DigitalOcean for MySQL at the same affordable price. Read-Intensive Latency Benchmark. Balanced Workload Latency Benchmark.
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. Understanding distributed storage is imperative as data volumes and the need for robust storage solutions rise.
Narrowing the gap between serverless and its state with storage functions , Zhang et al., Shredder is " a low-latency multi-tenant cloud store that allows small units of computation to be performed directly within storage nodes. " SoCC’19. "Narrowing Shredder’s implementation is built on top of Seastar.
It enables a Production Office Coordinator to keep a Production’s cast, crew, and vendors organized and up to date with the latest information throughout the course of a title’s filming. We are expected to process 1,000 watermarks for a single distribution in a minute, with non-linear latency growth as the number of watermarks increases.
Now that we suspect file I/O it’s necessary to go to Graph Explorer-> Storage-> File I/O. With a bit of column rearranging we get this impressive result: What this says is that, over the course of two right-mouse clicks, RuntimeBroker.exe , thread 10,252, issued 229,604 ReadFile calls, reading a total of 15,686,586 bytes.
A Dedicated Log Volume (DLV) is a specialized storage volume designed to house database transaction logs separately from the volume containing the database tables. DLVs are particularly advantageous for databases with large allocated storage, high I/O per second (IOPS) requirements, or latency-sensitive workloads.
These guidelines work well for a wide range of applications, though the optimal settings, of course, depend on the workload. Storage The type of storage and disk used for database servers can have a significant impact on performance and reliability. have been released since then with some major changes. and MariaDB 10.5.4
Oh, and there’s a scheduler too of course to keep all the plates spinning. On the Cloudburst design teams’ wish list: A running function’s ‘hot’ data should be kept physically nearby for low-latency access. A low-latency autoscaling KVS can serve as both global storage and a DHT-like overlay network.
Edge servers are the middle ground – more compute power than a mobile device, but with latency of just a few ms. The client MWW combines these estimates with an estimate of the input/output transmission time (latency) to find the worker with the minimum overall execution latency.
It’s limited by the laws of physics in terms of end-to-end latency. We saw earlier that there is end-user pressure to replace batch systems with much lower latency online systems. We are observing significant demand from users in terms of avoiding batch telemetry pipelines altogether. Emphasis mine ). Emphasis mine ).
" Of course, no technology change happens in isolation, and at the same time NoSQL was evolving, so was cloud computing. Performant – DynamoDB consistently delivers single-digit millisecond latencies even as your traffic volume increases.
They can run applications in Sweden, serve end users across the Nordics with lower latency, and leverage advanced technologies such as containers, serverless computing, and more. We help Supercell to quickly develop, deploy, and scale their games to cope with varying numbers of gamers accessing the system throughout the course of the day.
DynamoDB was the first service at AWS to use SSD storage. These high-throughput, low-latency requirements need caching, not as a consideration, but as a best practice. You just point your existing application at the DAX endpoint, and as a read-through/write-through cache, DAX seamlessly handles caching for you.
Coupled with stateless application servers to execute business logic and a database-like system to provide persistent storage, they form a core component of popular data center service archictectures. The network latency of fetching data over the network, even considering fast data center networks. Who knew! ;). From RInK to LInK.
This operation is quite expensive but our database can run it in a few milliseconds or less, thanks to several optimizations that allow the node to execute most of them in memory with no or little access to mass storage. Of course, we are still talking about a low number of rows and running threads but the gain is there.
Big news this week was of course the launch of Cluster GPU instances for Amazon EC2. Understanding Throughput-Oriented Architectures - background article in CACM on massively parallel and throughput vs latency oriented architectures. Driving Storage Costs Down for AWS Customers. Expanding the Cloud - The AWS Storage Gateway.
It takes you through the thinking processes and engineering practices behind the design of a key part of the control plane for AWS Elastic Block Storage (EBS): the Physalia database that stores configuration information. This work is latency critical, because volume IO is blocked until it is complete. This paper is a real joy to read.
Alternatives to MongoDB Enterprise There are plenty of alternatives, but we’re not going to cover them all here, of course. Redis can handle a high volume of operations per second, making it useful for running applications that require low latency. Such organizations might seek a more straightforward alternative.
Making queries to an inference engine has many of the same throughput, latency, and cost considerations as making queries to a datastore, and more and more applications are coming to depend on such queries. First off there still is a model of course (but then there are servers hiding behind a serverless abstraction too!). autoscaling).
Reverb also take a snapshot of the client’s local storage (e.g. If the server-side responder is also being replayed, then Reverb inserts a new request into the server-side log… When the response is generated, Reverb buffers it and uses a model of network latency to determine where to inject the response into the client-side log.
Our approach differs substantially by (1) providing economic incentives for data to be contributed and integrated into existing schemas, (2) offering a SQL interface instead of graph based approaches, (3) including the computational and storage infrastructure in the architectural vision. An embodiment for structured data for IoT.
Websites are now more than just the storage and retrieval of information to present content to users. They now allow users to interact more with the company in the form of online forms, shopping carts, Content Management Systems (CMS), online courses, etc. Network latency. Network Latency. The list goes on and on.
This approach often leads to heavyweight high-latency analytical processes and poor applicability to realtime use cases. The straightforward approaches for implementation of this system are: Log all events in a large storage like Hadoop and compute unique visitor periodically using heavy MapReduce jobs or whatever.
As with traditional storage, applications are writing to a shared storage environment which is necessary to support VM movement. It is the shared storage that often causes performance issues for data bases which are otherwise separated across nodes. The idea here is to simulate the two main storage workloads of a DB.
Therefore any programming abstraction must be low latency and the kernel needs to be kept off the path of persistent data access as much as possible. Traditional pointers address a memory location (often virtual of course). This means that the overheads of system calls become much more noticeable.
For response times (latencies) reporting a simple metric such as ‘average’ is next to useless. Instead we want to understand what’s happening at different latency percentiles (e.g A characteristic of latency distributions is that they have a long tail. Why do we need a new sketch? At the 50th percentile, an accuracy within 0.5%
Back on December 5, 2017, Microsoft announced that they were using AMD EPYC 7551 processors in their storage-optimized Lv2-Series virtual machines. Of course, if I were buying an AMD-based server for on-premises SQL Server use right now, I would try to get the newer, frequency-optimized AMD EPYC 7371 processor. Memory (GiB).
For a company with 100 employees, multiply that over the course of the year, and you’re looking at upwards of 60,000 hours wasted. Typically, this involves using software and data virtualization tools to aggregate data from different databases, applications, and storage repositories.
For applications like communication between AVs, latency–how long it takes to get a response–is more likely to be a bigger limitation than raw bandwidth, and is subject to limits imposed by physics. There are impressive estimates for latency for 5G, but reality has a tendency to be harsh on such predictions.
It simulates a link with a 400ms RTT and 400-600Kbps of throughput (plus latency variability and simulated packet loss). Simulated packet loss and variable latency, however, can make benchmarking extremely difficult and slow. Our baseline, then, should probably trade lower throughput/higher-latency for packet loss.
Of course analog signalling comes with a whole bunch of challenges of its own, which is one of the reasons we tend to convert to digital. The resulting system can integrate seamlessly into a scikit-learn based development process, and dramatically reduces the total energy usage required for classification with very low latency.
This entails high-speed networks, real-time data platforms, scalable storage solutions, edge computing infrastructure, IoT devices, and advanced data processing capabilities. Both of these tactics can take a lot of time and require a lot of resources, which can pose a barrier to rapid intelligent manufacturing adoption.
Here, native apps are doing work related to their core function; storage and tracking of user data are squarely within the four corners of the app's natural responsibilities. Fixing mobile won't be sufficient to unwind desktop's increasingly negative dark patterns, of course. But that's no reason to delay.
Instead of producing large returns, of course, investment banking can produce large losses. This includes things like data storage, servers, e-mail, office productivity applications, virus protection, security and so forth. Of course, these complex properties don't make them "high value added" services. They're still utilities.
Chrome has missed several APIs for 3+ years: Storage Access API. For heavily latency-sensitive use-cases like WebXR, this is a critical component in delivering a good experience. It of course is personally frustrating to not be able to deliver these improvement for developers who wish to reach iOS users — which is all developers.
Here's some output from my zfsdist tool, in bcc/BPF, which measures ZFS latency as a histogram on Linux: # zfsdist. Tracing ZFS operation latency. Appliance manufacturers hire kernel engineers to develop custom features, including storage appliances. Hit Ctrl-C to end. ^C
Historically, NoSQL paid a lot of attention to tradeoffs between consistency, fault-tolerance and performance to serve geographically distributed systems, low-latency or highly available applications. Read/Write latency. Read/Write requests are processes with a minimal latency. Data Placement. Read/Write scalability.
A typical example of modern "microservices-inspired" Java application would function along these lines: Netflix : We observed during experimentation that RAM random read latencies were rarely higher than 1 microsecond whereas typical SSD random read speeds are between 100–500 microseconds.
A then-representative $200USD device had 4-8 slow (in-order, low-cache) cores, ~2GiB of RAM, and relatively slow MLC NAND flash storage. Not as much as we'd like, of course, but the worldwide baseline has changed enormously. There are differences, of course, but not where it counts. The Moto G4 , for example.
This might be very different for your company, of course, but that’s a close enough approximation of a majority of customers out there. Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms. Thanks to Tim Kadlec, Henri Helvetica and Alex Russel for the pointers! Large preview ).
This might be very different for your company, of course, but that’s a close enough approximation of a majority of customers out there. Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms. Thanks to Tim Kadlec, Henri Helvetica and Alex Russel for the pointers!
Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms. Of course, your data might show that your customers are not on these devices, but perhaps they simply don’t show up in your analytics because your service is inaccessible to them due to slow performance.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















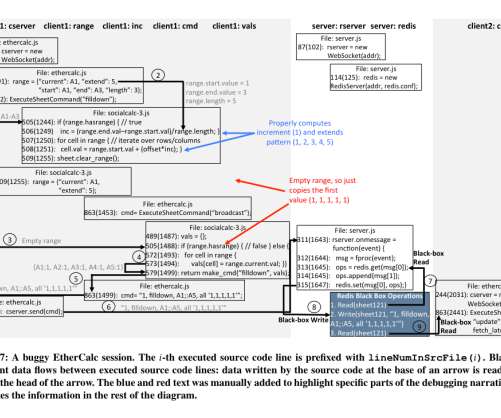
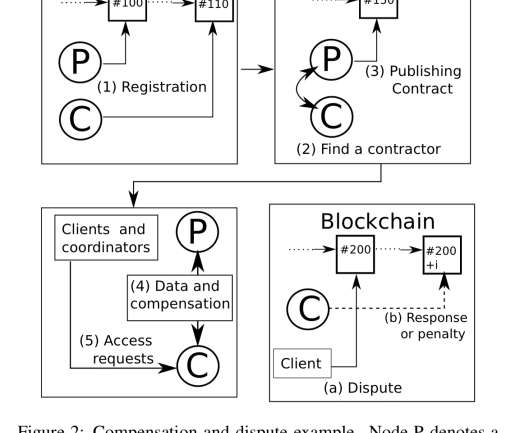
























Let's personalize your content