This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. Understanding distributed storage is imperative as data volumes and the need for robust storage solutions rise.
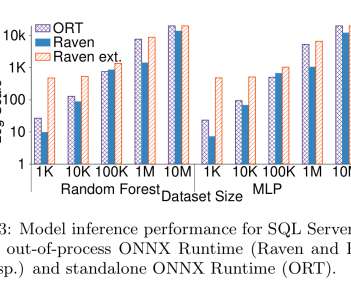
Building an elastic query engine on disaggregated storage , Vuppalapati, NSDI’20. This paper presents Snowflake design and implementation along with a discussion on how recent changes in cloud infrastructure (emerging hardware, fine-grained billing, etc.) But the ephemeral storage service for intermediate data is not based on S3.
Narrowing the gap between serverless and its state with storage functions , Zhang et al., Shredder is " a low-latency multi-tenant cloud store that allows small units of computation to be performed directly within storage nodes. " " Running end-user compute inside the datastore is not without its challenges of course.
A decade ago, while working for a large hosting provider, I led a team that was thrown into turmoil over the purchasing of server and storagehardware in preparation for a multi-million dollar super-bowl ad campaign. The data had to be painstakingly stitched together over the course of a few weeks, across each layer of our stack.
These guidelines work well for a wide range of applications, though the optimal settings, of course, depend on the workload. Hardware Memory The amount of RAM to be provisioned for database servers can vary greatly depending on the size of the database and the specific requirements of the company. Setting oom_score_adj to -800.
Each cloud-native evolution is about using the hardware more efficiently. Of course not, but let's ignore that very few organizations in the world have the technological know-how to create such managed services, especially without low level control of the entire system. That's easy to do, right? So why bother innovating?
Krste Asanovic from UC Berkeley kicked off the main program sharing his experience on “ Rejuvenating Computer Architecture Research with Open-Source Hardware ”. He ended the keynote with a call to action for open hardware and tools to start the next wave of computing innovation. This year’s MICRO had three inspiring keynote talks.
Defining high availability In general terms, high availability refers to the continuous operation of a system with little to no interruption to end users in the event of hardware or software failures, power outages, or other disruptions. If a primary server fails, a backup server can take over and continue to serve requests.
MySQL, PostgreSQL, MongoDB, MariaDB, and others each have unique strengths and weaknesses and should be evaluated based on factors such as scalability, compatibility, performance, security, data types, community support, licensing rules, compliance, and, of course, the all-important learning curve if your choice is new to you.
We help Supercell to quickly develop, deploy, and scale their games to cope with varying numbers of gamers accessing the system throughout the course of the day. If the solution works as envisioned, Telenor Connexion can easily deploy it to production and scale as needed without an investment in hardware.
Given that I am originally from the Netherlands I have, of course, a special interest in how Dutch companies are using our cloud services. . Europe is a continent with much diversity and for each country there are great AWS customer examples to tell.
Of course, with as much textual data as we have we are leveraging Lucene/SOLR (a NoSQL solution) for Search and Semantic processing. Why did you choose a SQL approach to build your social community app? Troy: The initial architecture was based on MySQL– weve continued with use of SQL but are now leveraging RDS.
These use their regression models to estimate processing time (which will depend on the hardware available, current load, etc.). This could of course be a local worker on the mobile device. The location selection algorithm is run periodically to see if better options are now available.
Also, in general terms, a high availability PostgreSQL solution must cover four key areas: Infrastructure: This is the physical or virtual hardware database systems rely on to run. Can you afford the necessary hardware, software, and operational costs of maintaining a PostgreSQL HA solution? there cannot be high availability.
… based on interactions with enterprise customers, we expect that storage and inference of ML models will be subject to the same scrutiny and performance requirements of sensitive/mission-critical operational data. There are limitations to this model of course. It can’t handle loops for example (an analysis of 4.6M
Byte-addressable non-volatile memory,) NVM will fundamentally change the way hardware interacts, the way operating systems are designed, and the way applications operate on data. Traditional pointers address a memory location (often virtual of course). At least, the nature of pointers that we want to make persistent.
As we saw with the SOAP paper last time out, even with a fixed model variant and hardware there are a lot of different ways to map a training workload over the available hardware. First off there still is a model of course (but then there are servers hiding behind a serverless abstraction too!). autoscaling).
Last week we saw the benefits of rethinking memory and pointer models at the hardware level when it came to object storage and compression ( Zippads ). The protections are hardware implemented and cannot be forged in software. At hardware reset the boot code is granted maximally permissive architectural capabilities.
Websites are now more than just the storage and retrieval of information to present content to users. They now allow users to interact more with the company in the form of online forms, shopping carts, Content Management Systems (CMS), online courses, etc. Hardware resources. Hardware Resources. The list goes on and on.
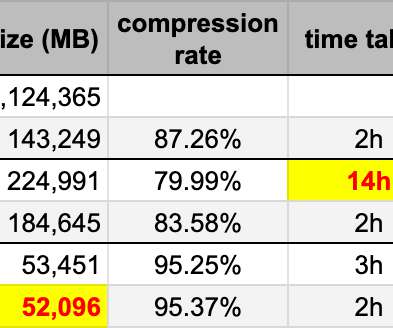
Of course we can always throw more disk at a table, but I wanted to see if we could scale this more efficiently than the current linear trend. Note that I am not focusing on reporting workload or other read query performance at this time – I merely want to see what impact I can have on storage (and memory) footprint of this data.
Among its many capabilities, a Citus cluster can: Create distributed tables that are sharded across a cluster of PostgreSQL nodes to combine their CPU, memory, storage, and I/O capacity. Columnar storage of tables can compress data, speeding up scans and supporting fast projections, both on regular and distributed tables.
Chrome has missed several APIs for 3+ years: Storage Access API. is access to hardware devices. This allows customisation and use of specialised features without custom, proprietary software for niche hardware. Some commenters appear to confuse unlike hardware for differences in software. Where Chrome Has Lagged.
It takes you through the thinking processes and engineering practices behind the design of a key part of the control plane for AWS Elastic Block Storage (EBS): the Physalia database that stores configuration information. And, of course, it is designed to minimise the blast radius of any failures that do occur. Physalia in the large.
The CITUS columnar extension feature set includes: Highly compressed tables: Reduces storage requirements. The complete CITUS feature set which, except for the Columnar storage component, is not covered in this blog, includes: Distributed tables. Columnar storage. Of course, there’s always more that can be said.
The goal is to produce a low-energy hardware classifier for embedded applications doing local processing of sensor data. Of course analog signalling comes with a whole bunch of challenges of its own, which is one of the reasons we tend to convert to digital. One such possible representation is pure analog signalling.
Pre-publication gates were valuable when better answers weren't available, but commentators should update their priors to account for hardware and software progress of the past 13 years. Fast forward a decade, and both the software and hardware situations have changed dramatically. Don't like the consequences?
Acknowledging the benefits, businesses across the globe are shifting to cloud-based automation testing to streamline their operations but of course, it comes with more benefits. It’s cost-effective and offers a flexible testing environment. Photo Credit: [link]. 6 Signs You Need To Invest In A Cloud-Based Test Automation Tool.
Key areas include: Configuration parameter tuning : This tuning involves altering variables such as memory allocation, disk I/O settings, and concurrent connections based on specific hardware and requirements. This not only results in cost savings by minimizing hardware requirements but also has the potential to decrease cloud expenses.
This, in turn, drives the single most important trend in setting the global web performance budget hardware baseline: the next billion users will largely come online when they can afford to. Time required to read bytes from disk (it’s not zero, even on flash-based storage!). Time to execute and run our code.
In addition to hardware and software expenses, costs also include the infrastructure needed to support these systems — like sensors, IoT devices, upgraded network capabilities, and robust cybersecurity measures.
Here, native apps are doing work related to their core function; storage and tracking of user data are squarely within the four corners of the app's natural responsibilities. Hardware access APIs, notably: Geolocation. Fixing mobile won't be sufficient to unwind desktop's increasingly negative dark patterns, of course.
Linux has been adding tracing technologies over the years: kprobes (kernel dynamic tracing), uprobes (user-level dynamic tracing), tracepoints (static tracing), and perf_events (profiling and hardware counters). Appliance manufacturers hire kernel engineers to develop custom features, including storage appliances.
Humans can of course work in teams, with a structure resembling that of the system itself , so I’m not saying everything must fit in a single mind, but each of the pieces that need to be understood as a whole do need to. But do A and C share the same storage, compute, or network resources for example? Go overdrawn (i.e.,
A database should accommodate itself to different data distributions, cluster topologies and hardware configurations. Network partitions of course can lead to violation of this guarantee. (G, In this article, we, of course, consider only a couple of applied techniques. Data Placement. Davies, and T. Lakshman, P.Malik.
In general terms, here are potential trouble spots: Hardware failure: Manufacturing defects, wear and tear, physical damage, and other factors can cause hardware to fail. heat) can damage hardware components and prompt data loss. Human mistakes: Incorrect configuration is an all-too-common cause of hardware and software failure.
A then-representative $200USD device had 4-8 slow (in-order, low-cache) cores, ~2GiB of RAM, and relatively slow MLC NAND flash storage. Not as much as we'd like, of course, but the worldwide baseline has changed enormously. Hardware Past As Performance Prologue. There are differences, of course, but not where it counts.
If you want to listen to the track—of course you do, it’s stunning—then you’ll have to make do with the YouTube version. If I go down this path, I’ll need to start considering many other things such as storage, backups, compatible media players, and maybe even dedicated hardware. Technics OTTAVA™ f SC-C70 – £799.
how much data does the browser have to download to display your website) and resource usage of the hardware serving and receiving the website. An obvious metric here is CPU usage, but memory usage and other forms of data storage also play their part. These include data transfer (i.e.
I became the Sun UK local specialist in performance and hardware, and as Sun transitioned from a desktop workstation company to sell high end multiprocessor servers I was helping customers find and fix scalability problems. We had specializations in hardware, operating systems, databases, graphics, etc.
This might be very different for your company, of course, but that’s a close enough approximation of a majority of customers out there. On the other hand, we have hardware constraints on memory and CPU due to JavaScript parsing and execution times (we’ll talk about them in detail later).
This might be very different for your company, of course, but that’s a close enough approximation of a majority of customers out there. On the other hand, we have hardware constraints on memory and CPU due to JavaScript parsing times (we’ll talk about them in detail later). Both of them are great introductions for diving into Webpack.
On the other hand, we have hardware constraints on memory and CPU due to JavaScript parsing times (we’ll talk about them in detail later). Of course, your data might show that your customers are not on these devices, but perhaps they simply don’t show up in your analytics because your service is inaccessible to them due to slow performance.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content