This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For detailed prerequisites, hardware requirements, and installation guidelines, see our help page for browser monitors in private locations. A: Yes, of course. Q: Do I need a special network configuration, opening non-standard ports and/or whitelisting some addresses? A: It all depends on your internal network architecture.
Snap: a microkernel approach to host networking Marty et al., This paper describes the networking stack, Snap , that has been running in production at Google for the last three years+. Upgrades are also rolled out progressively across the cluster of course. SOSP’19. It reminds me of ZeroMQ. All aboard the Pony Express.
Other distributions like Debian and Fedora are available as well, in addition to other software like VMware, NGINX, Docker, and, of course, Java. This is especially the case with microservices and applications created around multiple tiers, where cheaper hardware alternatives play a significant role in the infrastructure footprint.
Sometimes, you need to check the availability of internal resources that aren’t accessible from outside your network. A private Synthetic location is a location in your private network infrastructure where you install a Synthetic-enabled ActiveGate. Of course, you can still configure private locations per environment.
The short answers are, of course ‘all the time’ and ‘everyone’, but this mutual disownership is a common reason why performance often gets overlooked. Of course, it is impossible to fix (or even find) every performance issue during the development phase. The reason I refer to this as Proactive testing is becasue we generally do.
Each cloud-native evolution is about using the hardware more efficiently. Network effects are not the same as monopoly control. Cloud providers incur huge fixed costs for creating and maintaining a network of datacenters spread throughout the word. And even that list is not invulnerable. Neither are clouds.
In all these cases, prior to being delivered through our content delivery network Open Connect , our award-winning TV shows, movies and documentaries like The Crown need to be packaged to enable crucial features for our members. Decryption modules need to be initialized with the appropriate scheme and initialization vector.
Options 1 and 2 are of course the ‘scale out’ options, whereas option 3 is ‘scale up’. An IDS/IPS monitors network flows and matches incoming packets (or more strictly, Protocol Data Units, PDUs) against a set of rules. The FPGA hardware really wants to operate in a highly parallel mode using fixed size data structures.
DeepMind’s Gato is an AI model that can be taught to carry out many different kinds of tasks based on a single transformer neural network. The claim is that AGI is now simply a matter of improving performance, both in hardware and software, and making models bigger, using more data and more kinds of data across more modes.
Key Takeaways Distributed storage systems benefit organizations by enhancing data availability, fault tolerance, and system scalability, leading to cost savings from reduced hardware needs, energy consumption, and personnel. They maintain fault tolerance and redundancy by replicating this information throughout various nodes in the system.
Defining high availability In general terms, high availability refers to the continuous operation of a system with little to no interruption to end users in the event of hardware or software failures, power outages, or other disruptions. Without enough infrastructure (physical or virtualized servers, networking, etc.),
Krste Asanovic from UC Berkeley kicked off the main program sharing his experience on “ Rejuvenating Computer Architecture Research with Open-Source Hardware ”. He ended the keynote with a call to action for open hardware and tools to start the next wave of computing innovation. This year’s MICRO had three inspiring keynote talks.
From tax preparation to safe social networks, Amazon RDS brings new and innovative applications to the cloud. Intelligent Social network - Facilitate topical Q&A conversations among employees, customers and our most valued super contributors. Teachers can interact with their colleagues in professional learning networks.
" Running end-user compute inside the datastore is not without its challenges of course. Entry/exit in/out of V8 contexts is less expensive than hardware-based isolation mechanisms, keeping request processing latency low and throughput high. Depending on the use case, CSA increases server throughput by up to 3.5x.
Mobile phones are rapidly becoming touchscreens and touchscreen phones are increasingly all-touch, with the largest possible display area and fewer and fewer hardware buttons. The hardware matters, but the underlying OS is the same , and pretty much all apps will run on any device of the same age. DRM-free, of course.
So far, it’s been a painless shift in power, which as Eric Matthes, author of Python Crash Course , argues, should come as no surprise, since “Guido has carried himself, and his role in the community, with such poise for so long.” ” Java. It’s mostly good news on the Java front.
We launched Edge Network locations in Denmark, Finland, Norway, and Sweden. We help Supercell to quickly develop, deploy, and scale their games to cope with varying numbers of gamers accessing the system throughout the course of the day. Our AWS Europe (Stockholm) Region is open for business now.
Given that I am originally from the Netherlands I have, of course, a special interest in how Dutch companies are using our cloud services. . Europe is a continent with much diversity and for each country there are great AWS customer examples to tell.
These use their regression models to estimate processing time (which will depend on the hardware available, current load, etc.). This could of course be a local worker on the mobile device. The location selection algorithm is run periodically to see if better options are now available. The opencv app has the largest state (4.6
This paper presents Snowflake design and implementation along with a discussion on how recent changes in cloud infrastructure (emerging hardware, fine-grained billing, etc.) Of course, this has to be done whilst retaining strong isolation properties. From shared-nothing to disaggregation.
Physalia is designed to offer consistency and high-availability, even under network partitions. And, of course, it is designed to minimise the blast radius of any failures that do occur. Studies across three decades have found that software, operations, and scale drive downtime in systems designed to tolerate hardware faults.
They now allow users to interact more with the company in the form of online forms, shopping carts, Content Management Systems (CMS), online courses, etc. Network or connection error. Network latency. Hardware resources. Network Latency. Network latency can be affected due to. Hardware Resources.
Being an ICLR paper of course, you won’t be surprised to learn that the solution involves neural networks. Instead of learning from scratch, we draw inspiration from the few-shot leaning advances obtained by meta-learning memory-augmented neural networks. But Rae et al.
Lazy-load offscreen images (reduce network contention for key resources). For low impact to First Input Delay : Avoid images causing network contention with other critical resources like CSS and JS. You can of course also do this manually just using the <img> element directly. We’ll cover this later. Large preview ).
MySQL, PostgreSQL, MongoDB, MariaDB, and others each have unique strengths and weaknesses and should be evaluated based on factors such as scalability, compatibility, performance, security, data types, community support, licensing rules, compliance, and, of course, the all-important learning curve if your choice is new to you.
Although at graduate-level, architecture classes cover interesting cutting-edge research, materials taught to undergrads in computer architecture courses, pedagogically are detached from cutting-edge research (eg. This is arguably a fundamentally hard problem for computer architecture, but efforts towards open source hardware (eg.
Real-time network protocols for enabling videoconferencing, desktop sharing, and game streaming applications. Modern, asynchronous network APIs that dramatically improve performance in some situations. A tool for reliably sending data — for example, chat and email messages — in the face of intermittent network connections.
At some later point a SQL query is issued which SELECT s a model and then uses the PREDICT function to generate a prediction from the model given some input data (which is itself of course the result of a query). There are limitations to this model of course. It can’t handle loops for example (an analysis of 4.6M The last word.
” This contains updated and new material that reflects the latest C++ standards and compilers, with a focus to using modern C++11/14/17 effectively on modern hardware and memory architectures. On April 25-27, I’ll be in Stockholm (Kista) giving a three-day seminar on “High-Performance and Low-Latency C++.”
The thrust of the argument is that there’s a chain of inter-linked assumptions / dependencies from the hardware all the way to the programming model, and any time you step outside of the mainstream it’s sufficiently hard to get acceptable performance that researchers are discouraged from doing so. Challenges compiling non-standard kernels.
What interests me most about the web on a watch are the constraints that the hardware places. Of course, I haven’t seen anything yet about how the watch is going to treat all that JavaScript in the first place. This enables lower-powered hardware to serve web content without overtaxing itself. That’s roughly 1.7-2.4MB
Also, in general terms, a high availability PostgreSQL solution must cover four key areas: Infrastructure: This is the physical or virtual hardware database systems rely on to run. Without enough infrastructure (physical or virtualized servers, networking, etc.), there cannot be high availability. If so, what are the legal liabilities?
As we saw with the SOAP paper last time out, even with a fixed model variant and hardware there are a lot of different ways to map a training workload over the available hardware. First off there still is a model of course (but then there are servers hiding behind a serverless abstraction too!). autoscaling).
To secure consumer data, organizations need to make sure that their networks are updated and protected against any malicious activity. Penetration testing is comprehensively performed over a fully-functional system’s software and hardware. There are many tools available which detect the presence of a firewall such as WAFWOOF.
We constrain ourselves to a real-world baseline device + network configuration to measure progress. Budgets are scaled to a benchmark network & device. JavaScript is the single most expensive part of any page in ways that are a function of both network capacity and device speed. The median user is on a slow network.
And of course, companies that don’t use AI don’t need an AI use policy. That pricing won’t be sustainable, particularly as hardware shortages drive up the cost of building infrastructure. The same thing happened to networking 20 or 25 years ago: wiring an office or a house for ethernet used to be a big deal. from education.
It's time once again to update our priors regarding the global device and network situation. HTML, CSS, images, and fonts can all be parsed and run at near wire speeds on low-end hardware, but JavaScript is at least three times more expensive, byte-for-byte. What's changed since last year? and 75KiB of JavaScript.
When even a bit of React can be a problem on devices slow and fast alike, using it is an intentional choice that effectively excludes people with low-end hardware. Server rendering is also cool—even if that’s just how we say “send HTML over the network” these days. It makes organizing code easier. I think JSX is great. Startup time.
The goal is to produce a low-energy hardware classifier for embedded applications doing local processing of sensor data. Of course analog signalling comes with a whole bunch of challenges of its own, which is one of the reasons we tend to convert to digital. So decision trees are essentially networks of threshold functions.
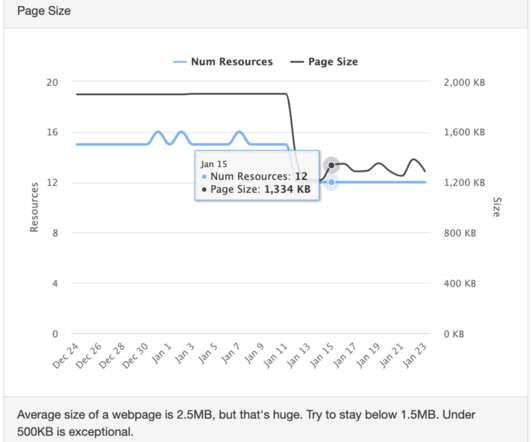
We wanted to have control of the hardware that runs our tests and deliver consistent results. Of course, you still won’t see the same loading time every test , so let’s look at some of the reasons why. Below you’ll see an image showing a graph of a website’s test results over the course of a month.
As a result, IT teams picked hardware somewhat blindly but with a strong bias towards oversizing for the sake of expanding the budget, leading to systems running at 10-15% of maximum capacity. Prototypes, experiments, and tests Development and testing historically involved end-of-life or ‘spare’ hardware. When is the cloud a bad idea?
As a trend, it’s not performing well on Google; it shows little long-term growth, if any, and gets nowhere near as many searches as terms like “Observability” and “Generative Adversarial Networks.” Our current set of AI algorithms are good enough, as is our hardware; the hard problems are all about data.
Byte-addressable non-volatile memory,) NVM will fundamentally change the way hardware interacts, the way operating systems are designed, and the way applications operate on data. Traditionally one of the major costs when moving data in and out of memory (be it to persistent media or over the network) is serialisation.
In a recent project comparing systems for MariaDB performance, a user had originally been using a tool called sysbench-tpcc to compare hardware platforms before migrating to HammerDB. This is a brief post to highlight the metrics to use to do the comparison using a separate hardware platform for illustration purposes. sys%-11.44
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content