This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In addition to service-level monitoring, certain services within the OpenTelemetry demo application expose process-level metrics, such as CPU and memory consumption, number of threads, or heap size for services written in different languages. This query confirms the suspicion that a particular product might be wrong.
Organizations choose data-driven approaches to maximize the value of their data, achieve better business outcomes, and realize cost savings by improving their products, services, and processes. Data is then dynamically routed into pipelines for further processing. Such transformations can reduce storage costs by 99%.
To help you navigate this and boost your efficiency, we’re excited to announce that Davis CoPilot Chat is now generally available (GA). This new feature provides information and guidance exactly when and where you need it, making your Dynatrace experience smoother and more efficient.
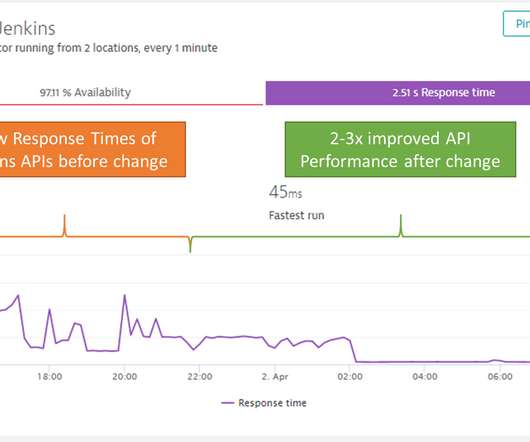
Besides a lot of memory being allocated by core Jenkins components, there was one allocation that stuck out; over the course of the analyzed 14 hours, 557 million KXmlParser objects got initialized (call to constructor) allocating 1.62TB (yes – that is Terabyte) of memory. Step #4 – JDK 11 thread leak.
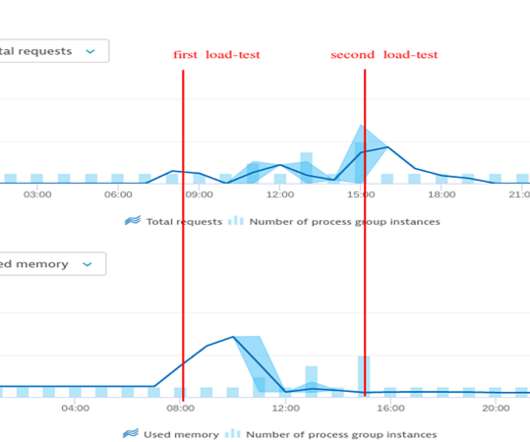
We were in the process of developing a new feature and wanted to make sure it could handle the expected load behavior. However, to be 100% sure we fixed the memory leak for good, we had to dig deeper and investigate the event broker process and its critical health metrics provided by the Dynatrace OneAgent. And of course: no more OOMs.
AI and DevOps, of course The C suite is also betting on certain technology trends to drive the next chapter of digital transformation: artificial intelligence and DevOps. According to IDC, AI technology will be inserted into the processes and products of at least 90% of new enterprise apps by 2025. And according to Statista , $2.4
Most approaches focus on improving Power Usage Effectiveness (PUE), a data center energy-efficiency measure. energy-efficient data centers—cloud providers—achieve values closer to 1.2. Of course, you need to balance these opportunities with the business goals of the applications served by these hosts. A PUE of 1.0
This massive migration is critical to organizations’ digital transformation , placing cloud technology front and center and elevating the need for greater visibility, efficiency, and scalability delivered by a unified observability and security platform. This creates a billing process that is simplified and straightforward.
Process Improvements (50%) The allocation for process improvements is devoted to automation and continuous improvement SREs help to ensure that systems are scalable, reliable, and efficient. Streamlining the CI/CD process to ensure optimal efficiency.
The aforementioned principles have, of course, a major impact on the overall architecture. As a result, we created Grail with three different building blocks, each serving a special duty: Ingest and process. Ingest and process with Grail. Work with different and independent data types. Grail architectural basics. Retain data.
Doing so will require increasing customer lifetime value (CLV) by expanding existing customers’ wallet share while optimizing efficiencies to reduce waste. Over the course of a lifetime relationship, this can mean thousands or hundreds of thousands of dollars’ worth of opportunities that would otherwise be lost.
One of the most significant shortcomings of the Key-Value model is a poor applicability to cases that require processing of key ranges. Relational databases are not very convenient for hierarchical or graph-like data modeling and processing. Using denormalization one can group all data that is needed to process a query in one place.
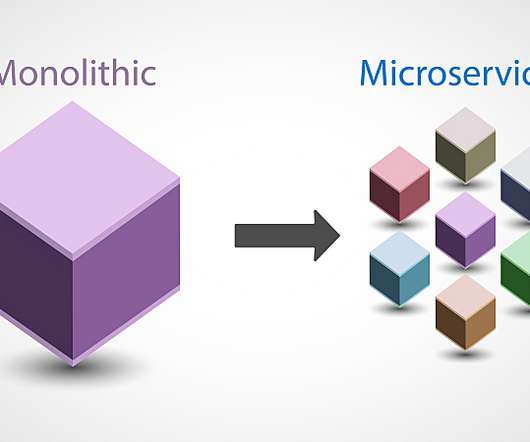
Application modernization centers on bringing monolithic, on-premises applications — which IT teams usually update and maintain with waterfall development processes — into cloud architecture and release patterns. Improved efficiency. With improved application efficiency, teams can service clients better and access cloud-native tools.
A distinct, NN-based, video processing block can evolve independently, be used beyond video downscaling and be combined with different codecs. Of course, we believe in the transformative potential of NN throughout video applications, beyond video downscaling. How do we apply neural networks at scale efficiently?
The implications of software performance issues and outages have a significantly broader impact than in the past—with the potential to negatively impact revenue, customer experiences, patient outcomes, and, of course, brand reputation. Ideally, resiliency plans would lead to complete prevention.
Inevitably, this leads to one very important question addressing the efficiency of ML: can such an AI ever keep up with frequent changes and deployments? The second major concern I want to discuss is around the data processing chain. The four stages of data processing. Four stages of data processing with a costly tool switch.
Of course, development teams need to understand how their code behaves in production and whether any issues need to be fixed. The app scans all incoming logs for various patterns and uses DQL (Dynatrace Query Language) to collect context like hosts, other processes, and traces for each potential problem.
Getting the problem status of all environments has to be efficient. Websockets allows efficient data push via multicast to browsers and D3.js Stay tuned for my next part of this series where I will cover another visualization and how it helped me optimize the Dynatrace Anomaly Detection settings and our operations processes!
Although Dynatrace can’t help with the manual remediation process itself , end-to-end observability, AI-driven analytics, and key Dynatrace features proved crucial for many of our customers’ remediation efforts. For example, a good course of action is knowing which impacted servers run mission-critical services and remediating those first.
Of course, the most important aspect of activating Dynatrace on Kubernetes is the incalculable level of value the platform unlocks. Of course, everything is deployed using standard kubectl commands. This solution offers both maximum efficiency and adherence for the toughest privacy or compliance demands.
In our Big Shift world, we confront the imperative of institutional innovation – shifting from institutional models built on scalable efficiency to institutional models built on scalable learning. I’ve written and spoken about this a lot over the years and one of the most common pushbacks I get is – “so, are you against efficiency?”
Not every situation lends itself to AIOps—for example, think about data that either can’t be monitored cost efficiently (where real-time processing wouldn’t benefit you) or when creating ad hoc reports to check long-term trends and make tactical/strategic business decisions in a timely fashion.
The consistency in request rates, request patterns, response time and allocation rates we see in many of our services certainly help ZGC, but we’ve found it’s equally capable of handling less consistent workloads (with exceptions of course; more on that below). Reference processing is also only performed in major collections with ZGC.
Not only will they get much more out of the tools they use daily, but they’ll also be able to deliver superior functionality, efficiency, and performance to your customers. In addition, 45% of them have gone on to implement efficiencies in their roles, and 43% reported they were able to do their job more quickly after getting certified.
This is required for understanding how I intend to improve the efficiency of (manual) alert ticket handling. If during the ticket handling another alert is raised this process repeats – but maybe with a different set of people who are working in parallel. With R (or RStudio) you can efficiently perform analysis on large data sets.
CloudOps includes processes such as incident management and event management. AIOps reduces the time needed to resolve an incident by automating key steps in the incident response process. The four stages of data processing. There are four stages of data processing: Collect raw data. Aggregate it for alerts.
Statoscope: A Course Of Intensive Therapy For Your Bundle. Statoscope: A Course Of Intensive Therapy For Your Bundle. It might not be completely efficient if we use modules in raw form, as they are in the file system: there might be some doubles, some modules could be combined, and others are only partially used. Sergey Melukov.
IT modernization improves public health services at state human services agencies For many organizations, the pandemic was a crash course in IT modernization as agencies scrambled to meet the community’s needs as details unfolded. The costs and challenges of technical debt Retaining older systems brings both direct and indirect costs.
Of course, if d is not a power of two, 2 N / d cannot be represented as an integer. In some instances, libdivide can even be more efficient than compilers because it uses an approach introduced by Robison (2005) where we not only use multiplications and shifts, but also an addition to avoid arithmetic overflows. if ( ( i % 3 ) = = 0 ).
The end goal, of course, is to optimize the availability of organizations’ software. Dynatrace AI increases efficiency by magnitudes and prevents alert storms. This approach eliminates the need for learning from past outages and enables a highly automated software delivery process, maximizing resilience.
Commonly applied to development processes, technical debt accrues overtime when we choose an inefficient path of least resistance. Our good intentions promise that we’ll revisit the shortcomings later—but of course “later” rarely arrives. We’ll also present the case that efficiency alone isn’t the best approach to judging value.
Both development and security teams require information that spans the software development lifecycle to work efficiently on closing gaps and blindspots in security coverage that could lead to a container reaching production unscanned, or with production vulnerabilities in the form of increased cyber-attack risk.
T o get performance insights into applications and efficiently troubleshoot and optimize them, you need precise and actionable analytics across the entire software life cycle. Of course, all the ingested metrics are available to Davis AI and support auto-adaptive baselining or threshold-based alerting.
Of course, we have opinions on all of these, but we think those arent the most useful questions to ask right now. Weve taught this SDLC in a live course with engineers from companies like Netflix, Meta, and the US Air Force and recently distilled it into a free 10-email course to help teams apply it in practice.
Each of those services runs in its own process and communicates with lightweight mechanisms. Therefore, DevOps teams can better control application performance, so applications can start faster and run more efficiently. Of course, there will be use cases to work with microservices from the start. Teams want efficiency.
Gartner defines AIOps as the combination of “big data and machine learning to automate IT operations processes, including event correlation, anomaly detection, and causality determination.” Humans simply cannot manually review and analyze the massive amount of data that a modern observability solution can process automatically.
Of course, much like the grapes, no two organizations are the same; how they adapted; how they took the challenge head-on; and how they changed their focus. Fermentation process: Steve Amos, IT Experience Manager at Vitality spoke about how the health and life insurance market is now busier than ever.
However, with today’s highly connected digital world, monitoring use cases expand to the services, processes, hosts, logs, networks, and of course, end-users that access these applications – including your customers and employees. Websites, mobile apps, and business applications are typical use cases for monitoring.
It’s important to focus on having good hygiene, having a good patching regimen, having a good security policy over the course of time, and finally, good governance.” Once developers can understand the security considerations in their own language, it can streamline the development process, the panelists indicated.
So many false starts, tedious workflows, and a complete lack of efficiency really made it difficult for me to find momentum. Of course, it’s a little more complex than that, but for this exercise it’s an incredibly reliable proxy. A couple of years ago, my first few days on a new web performance project were always slow going.
million per year just “keeping the lights on,” with 63% of CIOs surveyed across five continents calling out complexity as their biggest barrier to controlling costs and improving efficiency. Of course, it’s one thing to recognize business IT blind spots; it’s another to effectively address these issues at scale.
Although it can hardly be said that NoSQL movement brought fundamentally new techniques into distributed data processing, it triggered an avalanche of practical studies and real-life trials of different combinations of protocols and algorithms. Read/Write requests are processes with a minimal latency. System Coordination.
It’s much better to build your process around quality checks than retrofit these checks into the existent process. NIST did classic research to show that catching bugs at the beginning of the development process could be more than ten times cheaper than if a bug reaches production. A side note.
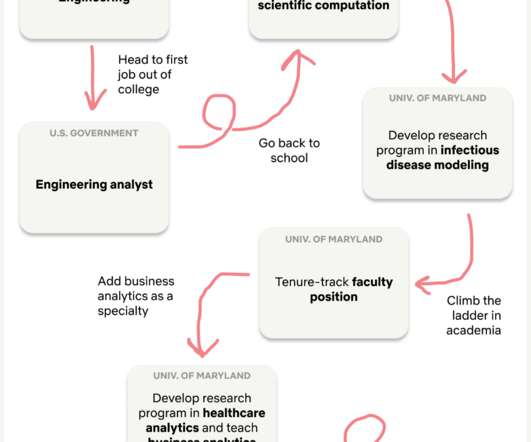
Like any rational person, I set out on a course to pursue a career that would either put me in space or help to put others up there. This is also the key period when most of my data science growth occurred, as I was developing my healthcare analytics research program and teaching analytics courses to MS and undergraduate students.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content