This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
RabbitMQ can be deployed in distributed environments and includes monitoring tools through a built-in dashboard and CLI. Architecture Comparison RabbitMQ and Kafka have distinct architectural designs that influence their performance and suitability for different use cases. However, performance can decline under high traffic conditions.
This had the effect of dramatically speeding up its performance and reducing support costs. For example, this year I was doing comparisons of headphones to purchase. For example, this year I was doing comparisons of headphones to purchase. But having a page load more quickly is only part of ensuring a good user experience.
Consolidate log management tools into a unified observability platform As businesses increasingly shift toward software-centric models, the number of specialized IT monitoring tools to manage cloud environments has proliferated. The first best practice is to consolidate log management with application monitoring in a single platform.
Constantly monitoring infrastructure health state and making ongoing optimizations are essential for Ops teams, SREs (site-reliability engineers), and IT admins. Quick and easy network infrastructure monitoring. Tired of constantly switching between all your monitoring tools? Start monitoring in minutes. Pool nodes.
Today, the speed of software development has become a key business differentiator, but collaboration, continuous improvement, and automation are even more critical to providing unprecedented customer value. Automated release inventory and version comparison. Automated SLO validation and quality gates. What’s next.
Because it’s critical that operations teams ensure that all internal resources are available for their users, synthetic monitoring of those resources is important. So why not use the advantages of K8s to make synthetic deployment monitoring easier and more effective? Private locations are crucial in achieving this goal.
2021 Gartner Peer Insights Voice of the Customer: Application Performance Monitoring. Observability provides deeper technical insights into what’s happening within cloud environments, in comparison to APM and/or traditional monitoring methods. Observability isn’t simply a new name for application performance monitoring (APM).
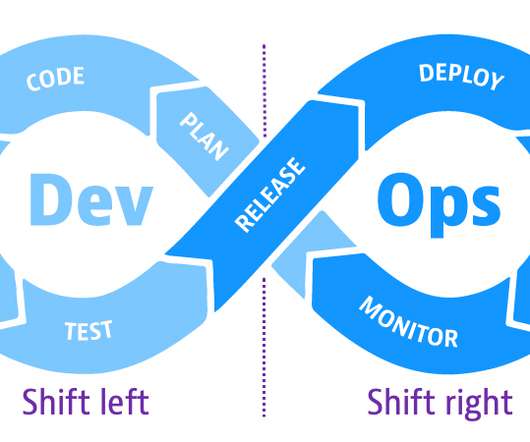
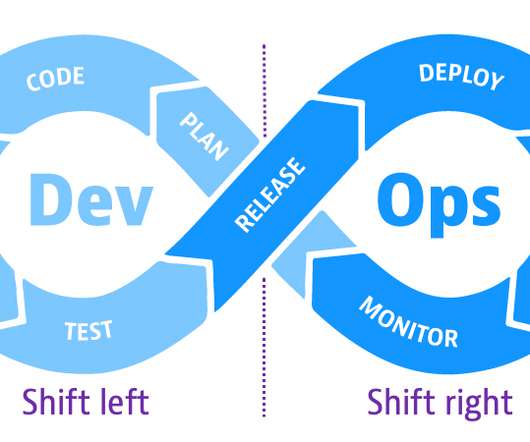
The DevOps approach to developing software aims to speed applications into production by releasing small builds frequently as code evolves. Shift-left speeds up development efficiency and reduces costs by detecting and addressing software defects earlier in the development cycle before they get to production. Synthetic monitoring.
The DevOps approach to developing software aims to speed applications into production by releasing small builds frequently as code evolves. Shift-left speeds up development efficiency and reduces costs by detecting and addressing software defects earlier in the development cycle before they get to production. Synthetic monitoring.
Most monitoring tools for migrations, development, and operations focus on collecting and aggregating the three pillars of observability— metrics, traces, and logs. Continuously monitor cost and optimize your capacity needs. Continuously monitor the application and the underlying infrastructure.
Better monitoring of WAL archiving. This wait event monitoring can tell us what the amount of time spent on specific actions is. Segments on a timeline * with a smaller ID will be older than all segments on a timeline with a * larger ID; the net result being that past timelines are given higher * priority for archiving. RestoreCommand.
Running A Page Speed Test: Monitoring vs. Measuring Running A Page Speed Test: Monitoring vs. Measuring Geoff Graham 2023-08-10T08:00:00+00:00 2023-08-10T12:35:05+00:00 This article is sponsored by DebugBear There is no shortage of ways to measure the speed of a webpage. Lighthouse results.
Now, while we’ve been pushing these concepts in Keptn we haven’t explained well enough how to level-up your existing load testing scripts for better SLI monitoring and how to integrate them with Dynatrace in order to reap all the benefits of SLI-based Performance Analysis. A key concept in monitoring is proper tagging.
Modern observability has evolved from simple metric telemetry monitoring to encompass a wide range of data, including logs, traces, events, alerts, and resource attributes. The native multi-select feature lets users open a filtered group of problems simultaneously, facilitating quick comparisons and detailed analysis.
In comparison, the AIOps approach discussed within this article, is built upon a radically different deterministic AI engine – at Dynatrace known as Davis – that yields precise, actionable results in real-time. Data sources typically include common infrastructure monitoring tools and second-generation APM solutions as well as other solutions.
Data observability involves monitoring and managing the internal state of data systems to gain insight into the data pipeline, understand how data evolves, and identify any issues that could compromise data integrity or reliability. Solution : Like the freshness example, Dynatrace can monitor the record count over time.
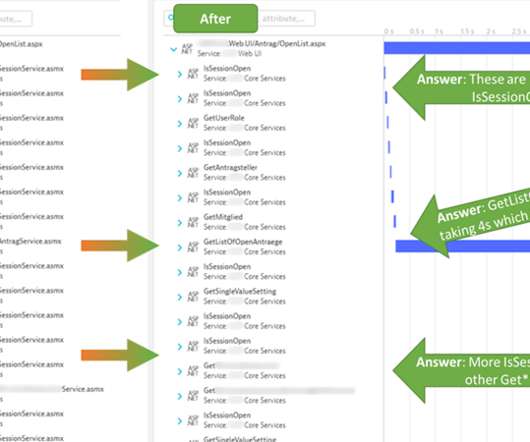
The challenge with ASP.NET Web Service Observability, Diagnostics and Performance Optimization is that most monitoring & diagnostic tools only provide global Service Level Indicators metrics (SLIs) such as response time, failure rate, and throughput, but not metrics for each individual service endpoint. Dynatrace news.
If you’re reading this, you likely already know the magnitude of operational tasks associated with maintaining a production deployment, but for a quick recap, there’s provisioning, deprovisioning, master-slave configurations, backups, scaling, upgrades, log rotations, OS patching, and monitoring to name a few. High Availability Deployment.
Conventional (not built for cloud) monitoring tools are not much help. To start, let’s look at the illustration below to see how these two operate in comparison: Also to note on traditional machine learning: by its very nature of operation it is slow and less agile.
Assuming encode/decode speeds meet your needs. Encode/Decode Speed. Degree of compression, image quality, and decoding speed are key factors to be considered when comparing image performance for the web. A tl;dr of recommendations can be found below. A complex decoding process can slow down the rendering of images.
Benefits of snappy compression in MongoDB: Fast compression and decompression speeds Low CPU usage A streamable format that allows for quick processing Minimal impact on query performance Zstandard Compression or zstd , another newer block compression method provided by MongoDB starting for v4.2, provides higher compression rates.
However, with our rapid product innovation speed, the whole approach experienced significant challenges: Business Complexity: The existing SKU management solution was designed years ago when the engagement rules were simple? Self Service : SKU changes need to be flexibly configurable, validated comprehensively, and released rapidly.
The data above is from lab monitoring and doesn't fully represent real user experience. TTFB mobile speed distribution (CrUX, July 2019). FCP mobile speed distribution (CrUX, July 2019). FID mobile speed distribution (CrUX, July 2019). TTFB mobile speed distribution comparison between all web and CMS (CrUX, July 2019).
We deployed these enhancements gradually over time to ensure that our users didn’t experience any disruptions, but instead only a consistent improvement of their site speed. While some noticeable progress was made, it was challenging to implement significant changes just for the sake of speed. Creating A Performance Culture.
Whether you’re new to web performance or you’re an expert working with the business side of your organization to gain buy-in on performance culture, we suggest starting with six specific metrics: Time to Interactive , First Contentful Paint , Visually Complete , Speed Index , Time to First Byte , and Total Content Size. Speed Index.
I've been spending a lot of time looking at the performance of European sites lately, and have found that the consent management platforms (CMPs) are consistently creating a bit of a false reality for folks when trying to understand performance using synthetic monitoring.
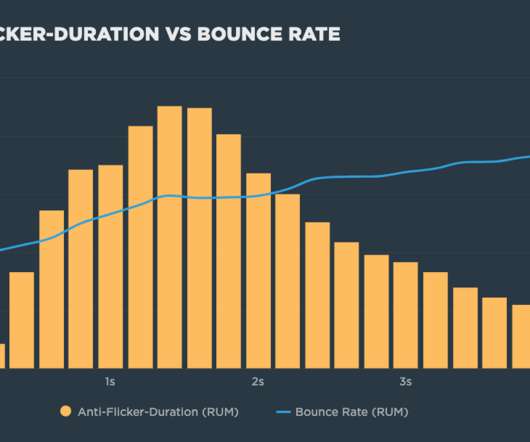
But as you can see in these filmstrips of Wiggle, a UK cycling retailer, hiding the page can have a dramatic impact on a visitor's experience: Comparison of a site loading with (top) and without (bottom) the anti-flicker snippet enabled. the speed of the network the device is connected to. Effects on other Web Vitals.
By adding automated visual testing , we can eliminate those flaky tests , leveling up our testing pipelines providing that coverage (and more) by taking advantage of smart image comparisons using screenshots of our website or app. Image Comparisons. Uptime Monitoring. How Does Visual Testing Work? Design/UX Collaboration.
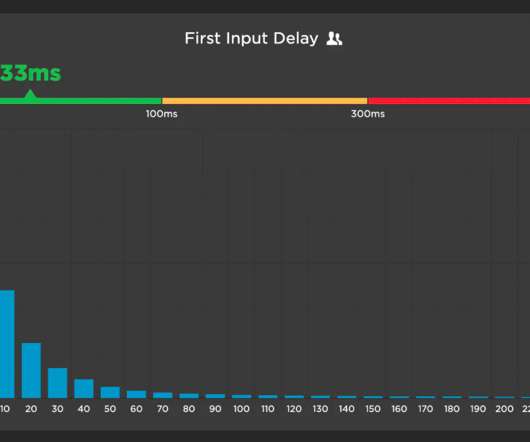
This metric is unique among the three Web Vitals in that it is can only be measured using real user monitoring (RUM), while the other two (Largest Contentful Paint and Cumulative Layout Shift) can be measured using both RUM and synthetic monitoring. FID is only measurable with real user monitoring (field data).
to run Google Lighthouse audits via the command line, save the reports they generate in JSON format and then compare them so web performance can be monitored as the website grows and develops. How should the metric comparison be output to the console? In this tutorial, I’ll show you step by step how to create a simple tool in Node.js
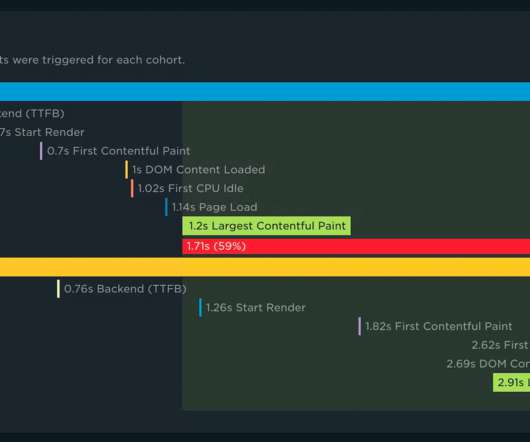
With your RUM Compare dashboard, you can easily generate side-by-side comparisons for any two cohorts of data. Triage a performance regression related to the latest change or deployment to your site by looking at a before/after comparison. This comparison highlights the comparison of key performance metrics between the cohorts.
It’s “single-threaded,” which is how we get the one-way street comparison. Monitoring The Main Thread If you’re like me, I immediately reach for DevTools and open the Lighthouse tab when I need to look into a site’s performance. Large preview ) That’s a nice big view and is a good illustration of TBT’s impact on page speed.
Fighting regressions should be the top priority of anyone who cares about the speed of their site. With SpeedCurve Synthetic , you can monitor any other website in the same way that you can monitor your own website. Fight regressions and stay fast It's easier to make a fast website than it is to keep a website fast.
Hint: If you're considering installing a big-screen performance monitor at your organization, this dashboard is a good candidate for that.). With your RUM Compare dashboard , you can easily generate side-by-side comparisons for any two cohorts of real user data. Expanded Industry Speed Benchmarks. Synthetic Site dashboard.
MariaDB uses storage engines that give it a speed boost and enable users to implement distributed storage and distributed transactions. Comparison of open source databases This section provides one-on-one comparisons of popular open source database software. With health and lives at stake, such access cannot be compromised.
Because INP measures actual user interactions, it can only be monitored using a real user monitoring (RUM) tool. The following is a comparison of FID and INP at the 75th percentile for Mobile and Desktop for RUM data collected from SpeedCurve. Most importantly, INP includes more than just input delay.
Comparison of page size and assets types across different responsive widths. Comparison of full loaded time for new Guardian responsive site (Guardian NGW) vs current Guardian site and the New York Times. There are great tools available to monitor the actual in browser speed and benchmark your site against others.
After you've added conversion data, you're all ready to create lots of compelling visualizations to get your organization to care about site speed. Now you can create your own filmstrip visuals in your Favorites to illustrate comparisons or show the impact of changes to the critical rendering path for your site. Learn more here.
Over the last few years the web performance monitoring toolset has expanded dramatically with the introduction of many new services and products. There are two main types of web performance monitoring, uptime monitoring and real user monitoring. Uptime Monitoring. Real User Monitoring.
Teams looking to grow past Level 1 develop (or uncover they already had) Real User Monitoring (" RUM data") infrastructure in previous cycles. Treating data as a distribution fundamentally enables comparison and experimentation because it creates a language for describing non-binary shifts. Management Attributes #.
We've also given you the ability to monitor individual third parties over time and create performance budgets for them. There's also a first party comparison you can toggle on/off to see what proportion of your requests come from first party vs third party. Our third party metrics and dashboard have had an exciting revamp. Contribute.
Eye-tracking provides information on how people navigate on a page and how attracted they are to visual elements on the screen, like in this study conducted by Nielsen Norman Group which shows the pattern that people use to scan comparison tables. Eye-tracking heatmaps are a visual representation of aggregate eye movements from the users.
Pairing these aggressive numbers alongside the conservative targets derived from comparison gives you an acceptable range to target for your site (handy to get you started with a performance budget ). A step up is to measure the Speed Index of a page instead. Speed Index doesn’t really bother with what happens at on load.
If you want to understand how people actually experience your site, you need to monitor real users. The data we get from real user monitoring (RUM) is extremely useful when trying to get a grasp on performance. Whatever the change may be, the comparison to the previous period can be found in several areas of the dashboard.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content