This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The improved UI of the new Synthetic app makes managing your synthetic tests and analyzing their results easier and more effective. Exploratory analytics now cover more bespoke scenarios, allowing you to access any element of test results stored in the Dynatrace Grail data lakehouse.
Second, it enables efficient and effective correlation and comparison of data between various sources. Semconv for HTTP Spans quite possibly the most important signal have been declared stable, and HTTP Metrics will hopefully soon follow. At the same time, having aligned telemetry data is crucial for adopting OpenTelemetry at scale.
The second phase involves migrating the traffic over to the new systems in a manner that mitigates the risk of incidents while continually monitoring and confirming that we are meeting crucial metrics tracked at multiple levels. Replay Solution The replay traffic testing solution comprises two essential components.
Our previous blog post presented replay traffic testing — a crucial instrument in our toolkit that allows us to implement these transformations with precision and reliability. By tracking metrics only at the level of service being updated, we might miss capturing deviations in broader end-to-end system functionality.
After a new build gets deployed and automated tests executed, SLIs are evaluated against their SLOs and, depending on that result, a build is considered good (promoted) or bad (rolled back). “ The app description and supporting files such as load testing scripts are on the Keptn Example GitHub. This is what this blog is all about.
By implementing service-level objectives, teams can avoid collecting and checking a huge amount of metrics for each service. Stable, well-calibrated SLOs pave the way for teams to automate additional processes and testing throughout the software delivery lifecycle. SLOs promote automation. SLOs minimize downtime. Availability.
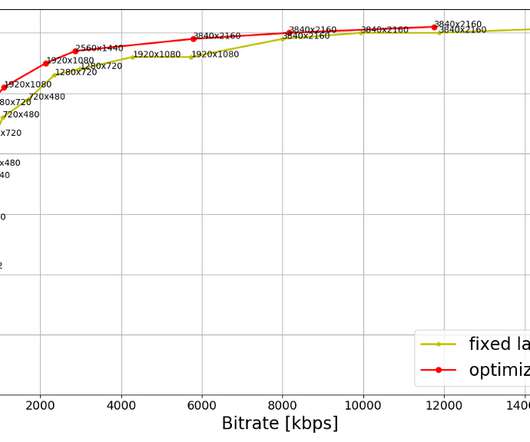
As for HDR, our team is currently developing an HDR extension to VMAF, Netflix’s video quality metric , which will then be used to optimize the HDR streams. ¹ Benefits to members At Netflix we perform A/B testing of encoding optimizations to detect any playback issues on client devices as well as gauge the benefits experienced by our members.
As HTTP and browser monitors cover the application level of the ISO /OSI model , successful executions of synthetic tests indicate that availability and performance meet the expected thresholds of your entire technological stack. into NAM test definitions. Our script, available on GitHub , provides details.
VMAF is a video quality metric that Netflix jointly developed with a number of university collaborators and open-sourced on Github. One aspect that differentiates VMAF from other traditional metrics such as PSNR or SSIM, is that VMAF is able to predict more consistently across spatial resolutions, across shots, and across genres (for example.
Design and Randomization We face various business problems where we cannot run individual level A/B tests but can benefit from quasi experiments. We typically have a small number of geographic units due to test limitations and also use broader or distant groups of units to minimize geographic spillovers. which is now confounded.
Consequently, this blog post highlights the new capability of the Site Reliability Guardian to define auto-adaptive thresholds that tackle the challenge of configuring static thresholds and protect your quality and security investments with relative comparisons to previous validations.
Most monitoring tools for migrations, development, and operations focus on collecting and aggregating the three pillars of observability— metrics, traces, and logs. Using a data-driven approach to size Azure resources, Dynatrace OneAgent captures host metrics out-of-the-box to assess CPU, memory, and network utilization on a VM host.
Automated release inventory and version comparison , which allows teams to easily evaluate the performance of individual release versions, and as needed, roll back to a previous version. Automated release inventory and version comparison. ” – Wim Verhaeghe, KBI-Connect DevOps team lead at Inetum-Realdolmen.
As organizations aim for faster delivery of value to their customers, the frequency of releases inevitably increases, which introduces risks and uncertainty into production systems—unless automated tests and quality gates can be leveraged to provide confidence. Automated comparison of different timeframes based on SLIs and SLOs.
Martin Tingley with Wenjing Zheng , Simon Ejdemyr , Stephanie Lane , Michael Lindon , and Colin McFarland This is the fifth post in a multi-part series on how Netflix uses A/B tests to inform decisions and continuously innovate on our products. Have a look at Part 1 (Decision Making at Netflix), Part 2 (What is an A/B Test?),
Technically, “performance” metrics are those relating to the responsiveness or latency of the app, including start up time. At Netflix the term “performance” usually encompasses both performance metrics (in the strict meaning) and memory metrics, and that’s how we’re using the term here. What are the Performance Tests?
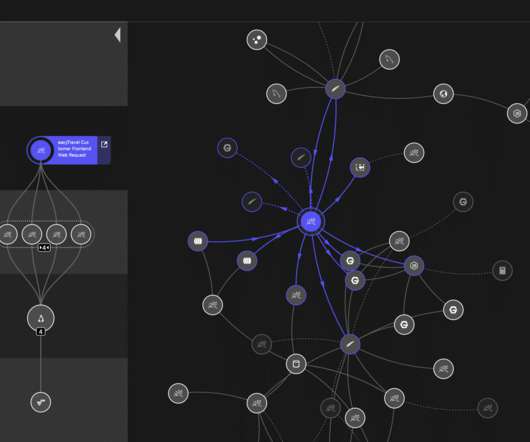
SREs face ever more challenging situations as environment complexity increases, applications scale up, and organizations grow: Growing dependency graphs result in blind spots and the inability to correlate performance metrics with user experience. Additionally, you can easily use any previously defined metrics and SLOs from your environments.
There were languages I briefly read about, including other performance comparisons on the internet. According to other comparisons [Google for 'Performance of Programming Languages'] spread over the net, they clearly outshine others in all speed benchmarks. Input The input will contain several test cases (not more than 10).
Not only do operations personnel now have an easier time deploying synthetic tests faster with fewer resources, it’s also no longer necessary to track utilization. Kubernetes takes care of keeping the necessary minimum number of nodes alive for executing all the tests assigned to a location.
Gone are the days for Christian manually looking at dashboards and metrics after a new build got deployed into a testing or acceptance environment: Integrating Keptn into your existing DevOps tools such as GitLab is just a matter of an API call. Comparison across builds. Heatmap and chart visualization in the Keptn Bridge.
Bringing together metrics, logs, traces, problem analytics, and root-cause information in dashboards and notebooks, Dynatrace offers an end-to-end unified operational view of cloud applications. To observe model drift and accuracy, companies can use holdout evaluation sets for comparison to model data.
In one test, I concatenated it all into one big file, and the other had the library split into 12 files. Read the complete test methodology. In our specific examples above, the one-big-file pattern incurred 201ms of latency, whereas the many-files approach accumulated 4,362ms by comparison. This will be referred to as css_time.
In comparison, on-premises clusters have more and larger nodes: on average, 9 nodes with 32 to 64 GB of memory. This trend shows that organizations are dedicating significantly more Kubernetes clusters to running software build, test, and deployment pipelines. Kubernetes infrastructure models differ between cloud and on-premises.
In a unified strategy, logs are not limited to applications but encompass infrastructure, business events, and custom metrics. Establish buckets for each cost center Establish buckets for each cost center or specific IT environment (production and staging vs. development and testing) within your organization. Set up processing rules.
A vital aspect of such development is subjective testing with HDR encodes in order to generate training data. The pandemic, however, posed unique challenges in conducting a conventional in-lab subjective test with HDR encodes. A/B testing also allows us to get a read on the improvement in quality of experience (QoE).
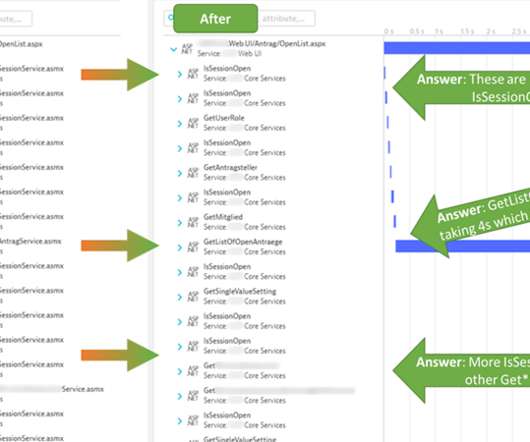
The challenge with ASP.NET Web Service Observability, Diagnostics and Performance Optimization is that most monitoring & diagnostic tools only provide global Service Level Indicators metrics (SLIs) such as response time, failure rate, and throughput, but not metrics for each individual service endpoint.
We use Sysbench to benchmark key performance metrics under different workloads and thread configurations, including Transactions Per Second (TPS) and Queries Per Second (QPS). Key metrics include TPS and QPS. It simulates high-concurrency environments, making it a go-to for performance testing of PostgreSQL across cloud platforms.
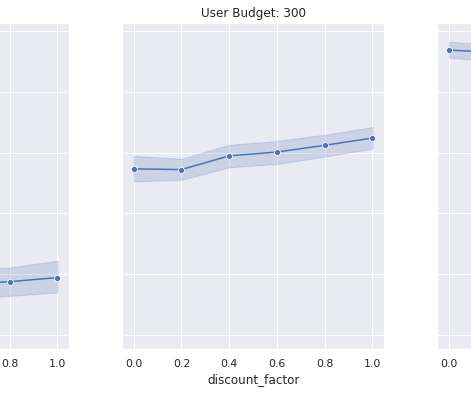
Metric A slate recommendation algorithm generates slates and then the user model is used to predict the success/failure of each slate. We compare the change in this metric for different user budget distributions. Paired comparison between RL and Contextual bandit. This is known as the SARSA algorithm.
In the age of AI, data observability has become foundational and complementary to AI observability, data quality being essential for training and testing AI models. Scenario : For many B2B SaaS companies, the number of reported customers is an important metric.
The increasing vastness and diversity of what our members are watching make answering these questions particularly challenging using conventional methods, which draw on a limited set of comparable titles and their respective performance metrics (e.g., box office, Nielsen ratings). This challenge is also an opportunity.
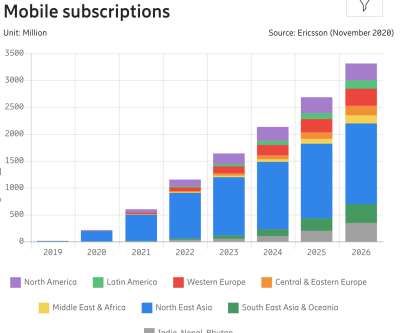
The State Of Mobile And Why Mobile Web Testing Matters. The State Of Mobile And Why Mobile Web Testing Matters. And to ensure the quality of a product, we always need to test — on a number of devices, and in a number of conditions. What’s a representative device to test on in 2021? Driving Business Metrics.
They collect metrics and raise alerts, but they provide few answers as to what went wrong in the first place. To start, let’s look at the illustration below to see how these two operate in comparison: Also to note on traditional machine learning: by its very nature of operation it is slow and less agile.
This can have an impact on most metrics – such as Start Render and Largest Contentful Paint – downstream. Masking third-party performance Assuming that you have visibility into your third-party performance is another pitfall when testing the first view of a site synthetically. How do I bypass the CMP? It's been said before.
A/B testing allows organizations to compare two versions of a web or app experience and then determine which one performs better. Metrics like the net promoter score (NPS) or customer satisfaction (CSAT) score encapsulate this kind of customer feedback into measurable analytics.
Within each of these areas, teams continuously run large-scale A/B experiments to test whether their ideas result in a more seamless experience for members. QoE is measured with a compilation of metrics that describe everything about the user’s experience from the time they press play until the time they finish watching.
In the plot, the Y-axis shows the additional bitrate in percent needed to achieve similar quality as libaom encoder according to three metrics. Reducing BD-rate between SVT-AV1 and libaom in 2-pass encoding mode The comparison results of the SVT-AV1 against libaom on objective-1-fast test set are presented in the table below.
Perceptual quality measurements are used to drive video encoding optimizations , perform video codec comparisons , carry out A/B testing and optimize streaming QoE decisions to mention a few. In particular, the VMAF metric lies at the core of improving the Netflix member’s streaming video quality. 4a & 4b. 4c & 5.
Within each of these areas, teams continuously run large-scale A/B experiments to test whether their ideas result in a more seamless experience for members. QoE is measured with a compilation of metrics that describe everything about the user’s experience from the time they press play until the time they finish watching.
Within each of these areas, teams continuously run large-scale A/B experiments to test whether their ideas result in a more seamless experience for members. QoE is measured with a compilation of metrics that describe everything about the user’s experience from the time they press play until the time they finish watching.
As a part of the Citrix monitoring extension for Dynatrace, we deliver a OneAgent plugin that adds several Citrix-specific WMI counters to the set of metrics reported by OneAgent. These metrics help you understand whether your Citrix landscape is sized correctly for its load.
But as you can see in these filmstrips of Wiggle, a UK cycling retailer, hiding the page can have a dramatic impact on a visitor's experience: Comparison of a site loading with (top) and without (bottom) the anti-flicker snippet enabled. The test in top row has the anti-flicker snippet in place. before the hero image. Using the data.
PMM2 uses VictoriaMetrics (VM) as its metrics storage engine. We have tested PMM version 2.33.0 Please note that the focus of these tests was around standard metrics gathering and display, we’ll use a future blog post to benchmark some of the more intensive query analytics (QAN) performance numbers.
On the other hand, when one is interested only in simple additive metrics like total page views or average price of conversion, it is obvious that raw data can be efficiently summarized, for example, on a daily basis or using simple in-stream counters. Counters on each position are incremented. Heavy Hitters: Stream-Summary.
Running A Page Speed Test: Monitoring vs. Measuring Running A Page Speed Test: Monitoring vs. Measuring Geoff Graham 2023-08-10T08:00:00+00:00 2023-08-10T12:35:05+00:00 This article is sponsored by DebugBear There is no shortage of ways to measure the speed of a webpage. Lighthouse results. And kept doing that over time.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content