This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Speed and scalability are significant issues today, at least in the application landscape. This level of comparison detail will assist decision-makers with the information they would need to make a more appropriate choice of an in-memory data store for their needs. However, the question arises of choosing the best one.
VMAF is a video quality metric that Netflix jointly developed with a number of university collaborators and open-sourced on Github. One aspect that differentiates VMAF from other traditional metrics such as PSNR or SSIM, is that VMAF is able to predict more consistently across spatial resolutions, across shots, and across genres (for example.
Architecture Comparison RabbitMQ and Kafka have distinct architectural designs that influence their performance and suitability for different use cases. Kafkas proprietary protocol is optimized for high-speed data transfer, ensuring minimal latency and efficient message distribution.
framework , the SNMP extensions are a bundle of everything that’s needed (DataSource configuration, a dashboard template, a unified analysis page template, topology definition, entity extraction rules, relevant metric definitions and more) to get going with monitoring. As with other extensions based on the new Dynatrace Extensions 2.0
Establishing clear, consistent, and effective quality gates that are automatically validated at each phase of the delivery pipeline is essential for improving software quality and speeding up delivery. Service-level indicators (SLIs) are checked against your SLOs early in the lifecycle, including comparison against previous builds.
Today, the speed of software development has become a key business differentiator, but collaboration, continuous improvement, and automation are even more critical to providing unprecedented customer value. Automated release inventory and version comparison.
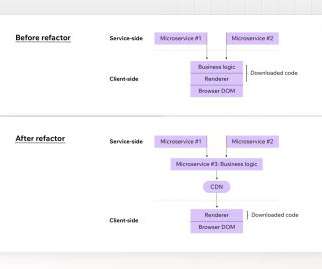
In our specific examples above, the one-big-file pattern incurred 201ms of latency, whereas the many-files approach accumulated 4,362ms by comparison. Connection One thing we haven’t looked at is the impact of network speeds on these outcomes. That’s almost 22× more! It’s a balancing act for sure. ? For example: vendor.js
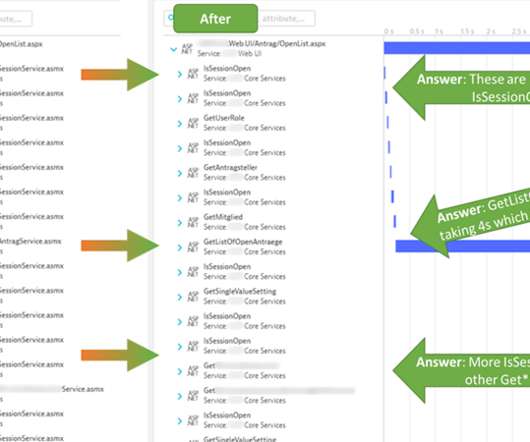
In Dynatrace, tagging also allows you to control access rights (via Management Zones), filter data on dashboards or via the API as well as allowing you to control calculation of custom service metrics or extraction of request attributes. This allows us to analyze metrics (SLIs) for each individual endpoint URL.
There were languages I briefly read about, including other performance comparisons on the internet. Considering all aspects and needs of current enterprise development, it is C++ and Java which outscore the other in terms of speed. These include Python, PHP, Perl, and Ruby.
SREs face ever more challenging situations as environment complexity increases, applications scale up, and organizations grow: Growing dependency graphs result in blind spots and the inability to correlate performance metrics with user experience. Additionally, you can easily use any previously defined metrics and SLOs from your environments.
Observability provides deeper technical insights into what’s happening within cloud environments, in comparison to APM and/or traditional monitoring methods. And for observability to be successful, it requires much more than just logs, metrics, and traces. Traditional approaches and tooling simply don’t work in the new cloud world.
This integrated approach represents significant time savings, drastically reducing MTTI and speeding mean time to resolution (MTTR). In a unified strategy, logs are not limited to applications but encompass infrastructure, business events, and custom metrics. In Grail, this data resides in business events historical logs.
Modern observability has evolved from simple metric telemetry monitoring to encompass a wide range of data, including logs, traces, events, alerts, and resource attributes. The native multi-select feature lets users open a filtered group of problems simultaneously, facilitating quick comparisons and detailed analysis.
It’s true that what might be considered the “most important” or “best” web performance metrics can vary by industry. These six metrics were not chosen at random – they work together to give you a snapshot of your site’s performance and overall user experience so you can set a baseline and improve speed and usability.
Most monitoring tools for migrations, development, and operations focus on collecting and aggregating the three pillars of observability— metrics, traces, and logs. Using a data-driven approach to size Azure resources, Dynatrace OneAgent captures host metrics out-of-the-box to assess CPU, memory, and network utilization on a VM host.
In comparison, the AIOps approach discussed within this article, is built upon a radically different deterministic AI engine – at Dynatrace known as Davis – that yields precise, actionable results in real-time. metrics) but it’s just adding another dataset and not solving the problem of cause-and-effect certainty.
This has been confirmed by the operations lead of a European organization catering to disabled people, “it significantly speeds deployment up and allows us to replicate the locations very quickly in a test environment.” This way the location is always big enough to effectively handle the load but does not consume more resources than needed.
Scenario : For many B2B SaaS companies, the number of reported customers is an important metric. In this scenario, a manually triggered run of a production pipeline had the unintended consequence of duplicating the reported customer metric.
It’s one of the most frequently asked questions I see asked, “I’ve tested my site speed, so now what do these metrics mean?” Here we’ll explain what each of the common web performance metrics mean, and how can you use that data to optimize your site and make it faster. Standard Website SpeedMetrics.
You’ll typically want to find a way to make a connection between a performance metric (such as First Meaningful Paint ) and a business metric (Conversion Rate). We’ve made your life easier by starting the comparison for you. The Simpsons Family = Web Performance Metrics. webperf #perfmatters Click To Tweet. Marge Simpson.
They collect metrics and raise alerts, but they provide few answers as to what went wrong in the first place. To start, let’s look at the illustration below to see how these two operate in comparison: Also to note on traditional machine learning: by its very nature of operation it is slow and less agile.
The challenge with ASP.NET Web Service Observability, Diagnostics and Performance Optimization is that most monitoring & diagnostic tools only provide global Service Level Indicators metrics (SLIs) such as response time, failure rate, and throughput, but not metrics for each individual service endpoint.
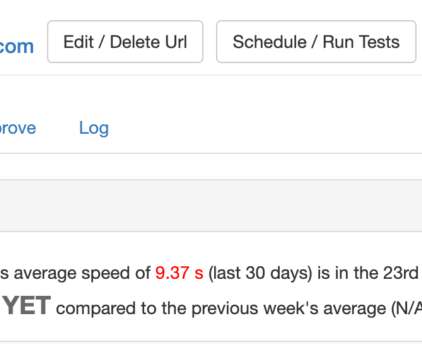
Running A Page Speed Test: Monitoring vs. Measuring Running A Page Speed Test: Monitoring vs. Measuring Geoff Graham 2023-08-10T08:00:00+00:00 2023-08-10T12:35:05+00:00 This article is sponsored by DebugBear There is no shortage of ways to measure the speed of a webpage. Lighthouse results.
Compression efficiency and performance Encoder performance SVT-AV1 reaches similar compression efficiency as libaom at the slowest speed settings. In the plot, the Y-axis shows the additional bitrate in percent needed to achieve similar quality as libaom encoder according to three metrics. A single-threaded compression mode is used.
Easily compare and view trends on multiple metrics with the new visualization. How does the customers’ browser version impact the speed of our website? Easily compare and view trends across multiple metrics. Charts reveal the highs and lows at a glance, so you can easily see how the different metrics affect each other.
We deployed these enhancements gradually over time to ensure that our users didn’t experience any disruptions, but instead only a consistent improvement of their site speed. While some noticeable progress was made, it was challenging to implement significant changes just for the sake of speed. Creating A Performance Culture.
This can have an impact on most metrics – such as Start Render and Largest Contentful Paint – downstream. If you were just looking at metrics, the event timeline comparison below may be a bit of a head-scratcher. It's common to see the consent scripts blocking by design. Debugging Interaction to Next Paint
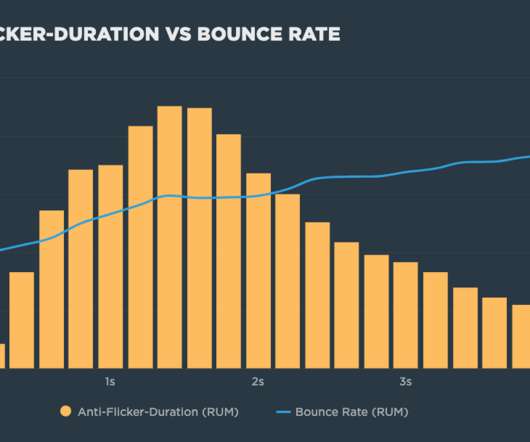
But as you can see in these filmstrips of Wiggle, a UK cycling retailer, hiding the page can have a dramatic impact on a visitor's experience: Comparison of a site loading with (top) and without (bottom) the anti-flicker snippet enabled. To summarize: On one hand, anti-flicker snippets make metrics such as FCP (and possibly LCP) worse.
You’ll typically want to find a way to make a connection between a performance metric (such as First Meaningful Paint) and a business metric (Conversion Rate). We’ve made your life easier by starting the comparison for you. The Simpsons Family = Performance Metrics. Time to First Byte – Maggie. The poor Professor.
People say JAMstack sites are fast — let’s find out why by looking at real performance metrics! We’ll cover common metrics, like Time to First Byte ( TTFB ) among others, then compare data across a wide section of sites to see how different ways to slice those sites up compare. TTFB mobile speed distribution (CrUX, July 2019).
Along with other general diagnostics and web performance metrics, a really useful feature of the report is that each of the key areas is aggregated into color-coded scores between 0-100. These are the numerical key performance metrics collected as part of any Lighthouse report. How should the metriccomparison be output to the console?
We love the idea of having a lean, shared set of metrics that we can all rally around – not to mention having a broader conversation about web performance that includes teams throughout an organization. We’ve had some time to evaluate and explore these metrics, and we're committed to transparently discussing their pros and cons.
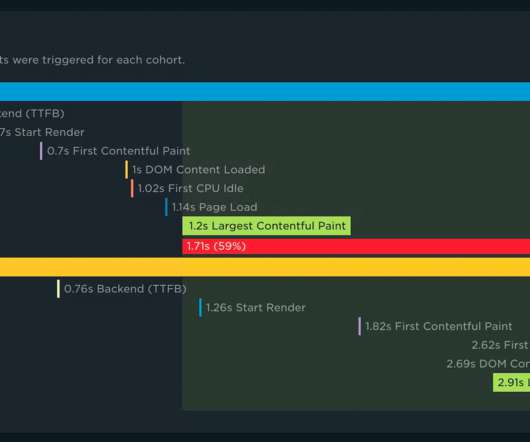
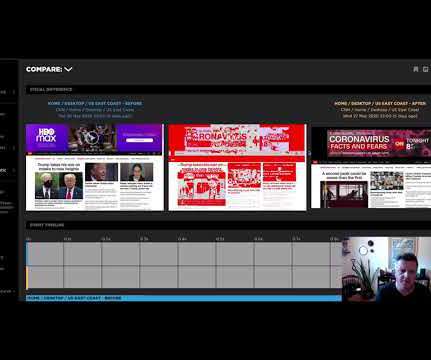
With your RUM Compare dashboard, you can easily generate side-by-side comparisons for any two cohorts of data. Triage a performance regression related to the latest change or deployment to your site by looking at a before/after comparison. To use, simply select the metric along with the upper and lower bounds for each cohort.
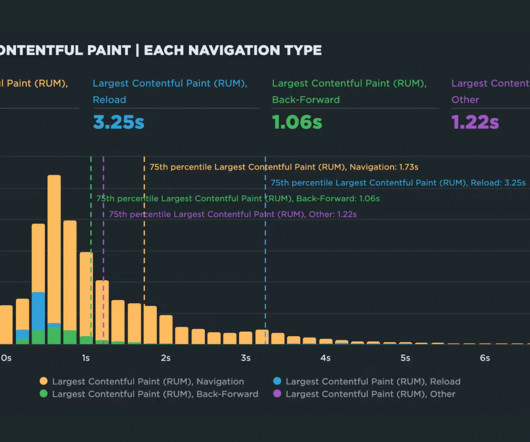
In this post, I'll demonstrate how you can use SpeedCurve RUM to identify all types of navigations, their performance impact, and potential opportunities for delivering lightning-fast page speed to your users. For example, in SpeedCurve, prerendered pages will have a value of '0' for most metrics.
And this is shocking since we all know that page load speed is directly correlated to site revenue (you’re aware that faster websites lead to increased conversion and sales, right?). Let’s add in some metrics ( click here if you need a refresher on these ): Time to First Byte (TTFB): 0.47s First Contentful Paint: 0.7s
This gives us a relatively unique opportunity to analyse and aggregate performance metrics to gain some interesting insights. In this post, I'm going to analyse some browser-based paint timing metrics: First Paint & First Contentful Paint (defined in the Paint Timing spec and implemented in Chromium). What are paint timing metrics?
However, there are quite a few high-profile case studies exploring the impact of mobile optimization on key business metrics. Driving Business Metrics. You can check the mobile view of your website in a side by side comparison view with mirrored interactions and touch support. Large preview ). Improving Accessibility.
Fighting regressions should be the top priority of anyone who cares about the speed of their site. The best way to fight regressions is to create performance budgets on key metrics, and get alerted when they go out of bounds. Make sure you're tracking the right metrics There are a lot of performance metrics out there!
It’s “single-threaded,” which is how we get the one-way street comparison. Total Blocking Time One thing I know would be more helpful than a set of Core Web Vitals scores from Lighthouse is knowing the time it takes to go from the First Contentful Paint (FCP) to the Time to Interactive (TTI), a metric known as the Total Blocking Time (TBT).
Here is a rundown of what's changed in this update: Chrome Moving from Chrome 126 to 133 shouldn't have a huge impact on your metrics. Firefox There was no identified impact to metrics between versions 128-135. release notes Change log comparison between 12.3.0 See full release history here. and 10.4.0 What should I do next?
One of the huge benefits of tracking web performance over time is the ability to see trends and compare metrics. With the new 'Compare' feature, you can now generate side-by-side comparisons that let you not only spot regressions, but easily identify what caused them: Compare the same page at different points in time. Test case: CNN.
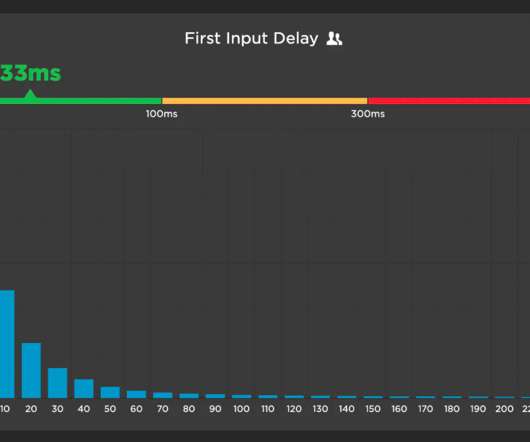
Today at Google I/O 2023, it was announced that Interaction to Next Paint (INP) is no longer an experimental metric. It's been hugely helpful to have a simple set of three metrics – focused on loading, interactivity, and responsiveness – that everyone can understand and focus on. How does INP compare to FID? have occurred.
Load averages are an industry-critical metric – my company spends millions auto-scaling cloud instances based on them and other metrics – but on Linux there's some mystery around them. But to understand them in more detail is difficult without the aid of other metrics. I've never seen an explanation. x 1.15 + 0.38
You can see at a glance: Key metrics like Core Web Vitals and your User Happiness score. Here you can still find time series charts that show how performance is trending over time across a number of key metrics, including Core Web Vitals. Fixing high-traffic but poor-performing areas of your site will help lift your overall metrics.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content