This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It now fully supports not only Network Availability Monitors but also HTTP synthetic monitors. Select any execution you’re interested in to display its details, for example, the content response body, its headers, and related metrics. With the new Dynatrace Synthetic application, you can select any two executions for comparison.
Quick and easy network infrastructure monitoring. Begin network monitoring by simply deploying an extension with just a few clicks. The topology model for network devices covers simple to complex use cases from visualizing the interfaces of a router to mapping an F5 Big-IP LTM load balancer. Start monitoring in minutes.
Why browser and HTTP monitors might not be sufficient In modern IT environments, which are complex and dynamically changing, you often need deeper insights into the Transport or Network layers. Is it a bug in the codebase, a malfunctioning backend service, an overloaded hosting infrastructure, or perhaps a misconfigured network?
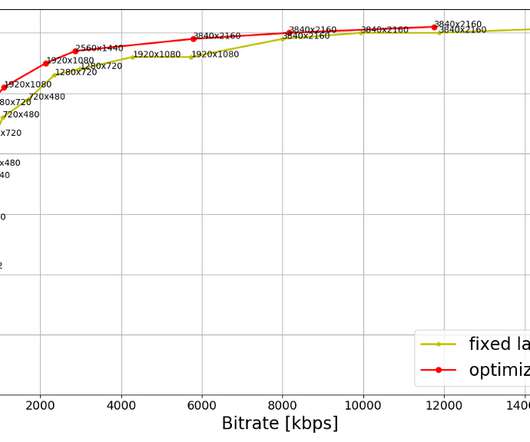
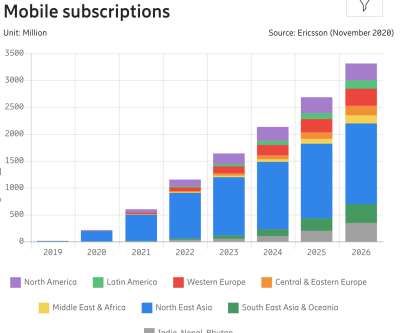
As the number of 4K titles in our catalog continues to grow and more devices support the premium features, we expect these video streams to have an increasing impact on our members and the network. The fixed-bitrate ladder starts at 560 kbps which may be too high for some cellular networks. shot-optimized encoding and 4K VMAF model ?—?and
Therefore, it requires multidimensional and multidisciplinary monitoring: Infrastructure health —automatically monitor the compute, storage, and network resources available to the Citrix system to ensure a stable platform. These metrics help you understand whether your Citrix landscape is sized correctly for its load.
Custom charts allow you to visualize metric performance over time, and USQL tiles allow you to dig deep into user session monitoring data. To access a dashboard report link or to unsubscribe from a scheduled report, you need to have network access to the respective Dynatrace environment. Metriccomparisons over previous timeframes.
ESG metrics are increasingly important to investors as they evaluate risk; in turn, these metrics are increasingly important to organizations because they measure and disclose their performance. The app translates utilization metrics, including CPU, memory, disk, and network I/O, into their CO2 equivalent (CO2e).
Most monitoring tools for migrations, development, and operations focus on collecting and aggregating the three pillars of observability— metrics, traces, and logs. Using a data-driven approach to size Azure resources, Dynatrace OneAgent captures host metrics out-of-the-box to assess CPU, memory, and network utilization on a VM host.
Architecture Comparison RabbitMQ and Kafka have distinct architectural designs that influence their performance and suitability for different use cases. Several factors impact RabbitMQs responsiveness, including hardware specifications, network speed, available memory, and queue configurations.
Compressing them over the network: Which compression algorithm, if any, will we use? In our specific examples above, the one-big-file pattern incurred 201ms of latency, whereas the many-files approach accumulated 4,362ms by comparison. Connection One thing we haven’t looked at is the impact of network speeds on these outcomes.
Observability provides deeper technical insights into what’s happening within cloud environments, in comparison to APM and/or traditional monitoring methods. And for observability to be successful, it requires much more than just logs, metrics, and traces. Traditional approaches and tooling simply don’t work in the new cloud world.
Application performance monitoring involves tracking key software application performance metrics using monitoring software and telemetry data. Application performance monitoring has a strong focus on specific metrics and measurements. Application performance management.
The increasing vastness and diversity of what our members are watching make answering these questions particularly challenging using conventional methods, which draw on a limited set of comparable titles and their respective performance metrics (e.g., box office, Nielsen ratings). This challenge is also an opportunity.
It is well known and fairly obvious that in geographically distributed systems or other environments with probable network partitions or delays it is not generally possible to maintain high availability without sacrificing consistency because isolated parts of the database have to operate independently in case of network partition.
Having the right metrics available on demand and at a high resolution is key to understanding how a system behaves and helps to quickly troubleshoot performance issues. This makes it much easier for engineers to get the graphs they want arranged in a manner for comparisons and to focus in the required areas. is more clearly visible.
To simulate those users’ journeys, multiple synthetic locations deployed within various sections of internal networks are required. Global corporations with offices in multiple countries need to ensure that their internal systems are accessible to all employees, regardless of their location.
They collect metrics and raise alerts, but they provide few answers as to what went wrong in the first place. To start, let’s look at the illustration below to see how these two operate in comparison: Also to note on traditional machine learning: by its very nature of operation it is slow and less agile.
Therefore, it requires multidimensional and multidisciplinary monitoring: Infrastructure health —automatically monitor the compute, storage, and network resources available to the Citrix system to ensure a stable platform. These metrics help you understand whether your Citrix landscape is sized correctly for its load.
We use Sysbench to benchmark key performance metrics under different workloads and thread configurations, including Transactions Per Second (TPS) and Queries Per Second (QPS). Key metrics include TPS and QPS. Test Environment Setup Instance Types : We used similar cloud instances for AWS RDS and ScaleGrid to ensure a fair comparison.
Technically, “performance” metrics are those relating to the responsiveness or latency of the app, including start up time. At Netflix the term “performance” usually encompasses both performance metrics (in the strict meaning) and memory metrics, and that’s how we’re using the term here. What do we mean by Performance?
Details pertaining to HDR-VMAF exceed the scope of this article and will be covered in a future blog post; for now, suffice it to say that the first version of HDR-VMAF landed internally in 2021 and we have been improving the metric ever since. The arrival of HDR-VMAF allowed us to create HDR streams with DO applied, i.e., HDR-DO encodes.
Training Performance Media model training poses multiple system challenges in storage, network, and GPUs. For instance, matching across a series with 10 episodes with an average of 2K shots per episode translates into 200M comparisons. Match Cutting across titles Step 4 entails a computation that is quadratic in the number of shots.
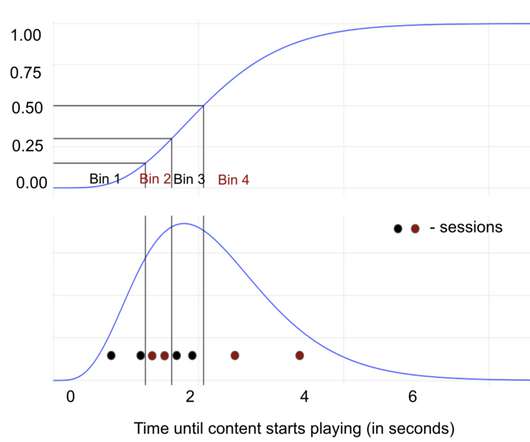
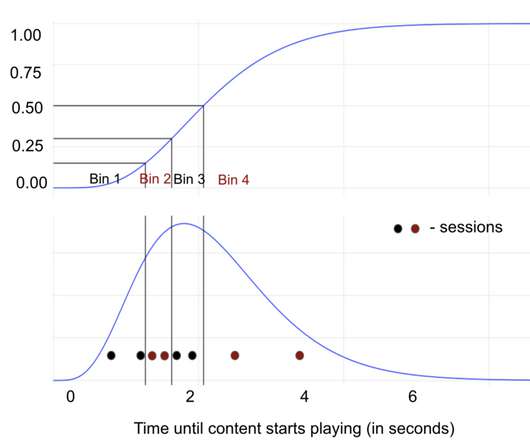
QoE is measured with a compilation of metrics that describe everything about the user’s experience from the time they press play until the time they finish watching. Examples of such metrics include how quickly the content starts playing and the number of times the video froze during playback (number of rebuffers).
QoE is measured with a compilation of metrics that describe everything about the user’s experience from the time they press play until the time they finish watching. Examples of such metrics include how quickly the content starts playing and the number of times the video froze during playback (number of rebuffers).
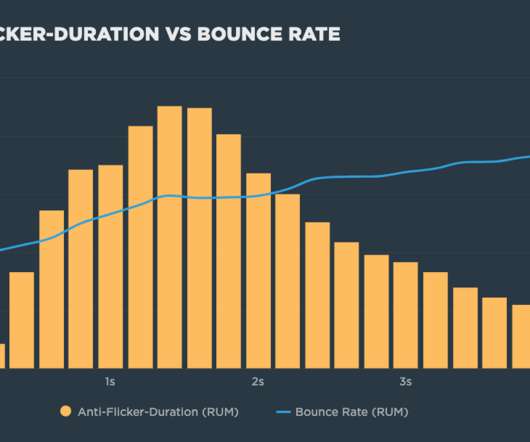
But as you can see in these filmstrips of Wiggle, a UK cycling retailer, hiding the page can have a dramatic impact on a visitor's experience: Comparison of a site loading with (top) and without (bottom) the anti-flicker snippet enabled. To summarize: On one hand, anti-flicker snippets make metrics such as FCP (and possibly LCP) worse.
QoE is measured with a compilation of metrics that describe everything about the user’s experience from the time they press play until the time they finish watching. Examples of such metrics include how quickly the content starts playing and the number of times the video froze during playback (number of rebuffers).
While mobile devices have come a long way in terms of network and CPU speed, many of them are still significantly underpowered when compared to desktops, especially in countries where mobile connectivity is still poor. Better tooling and metrics standardization. In other words, the field lacked standardization.
On the other hand, when one is interested only in simple additive metrics like total page views or average price of conversion, it is obvious that raw data can be efficiently summarized, for example, on a daily basis or using simple in-stream counters. A group of several such sketches can be used to process range query.
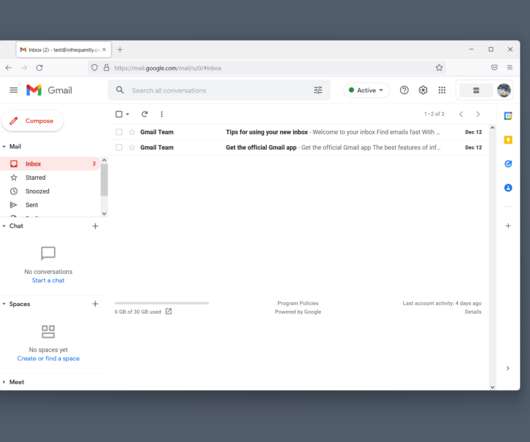
The metrics that we report against implicitly cleave these into different "camps", leaving us thinking about pre- and post-load as distinct universes. Despite fully reloading the page, the HTML version of Gmail consumes fewer network resources (~70KiB) and takes less overall time to return to interaction.
Load averages are an industry-critical metric – my company spends millions auto-scaling cloud instances based on them and other metrics – but on Linux there's some mystery around them. But to understand them in more detail is difficult without the aid of other metrics. Network I/O? x 1.15 + 0.38 x 1.25 = 1.18.
This header can be set on the response of any network resource, such as XHR, fetch, images, HTML, stylesheets, etc. The header is constructed via a name with an optional description and/or metric value. These subtypes are currently the only subtypes related to network requests and thus exposing the Server-Timing information.
In fact, there’s great tooling right under the hood of most browsers in DevTools that can do many things that a tried-and-true service like WebPageTest offers, complete with recommendations for improving specific metrics. Certain tools are designed for certain metrics with certain assumptions that produce certain results.
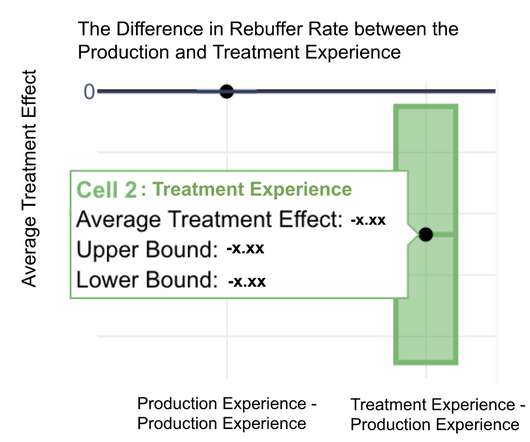
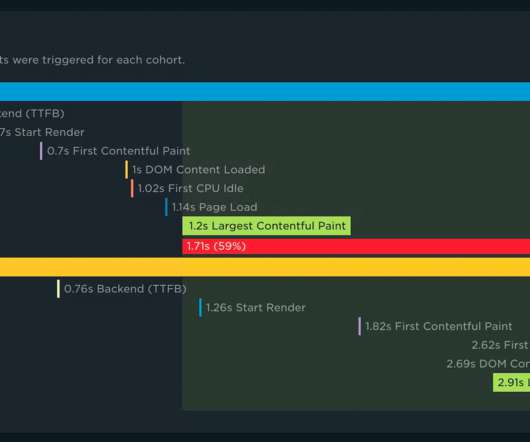
With your RUM Compare dashboard, you can easily generate side-by-side comparisons for any two cohorts of data. Triage a performance regression related to the latest change or deployment to your site by looking at a before/after comparison. To use, simply select the metric along with the upper and lower bounds for each cohort.
HTTP/2 versus HTTP/3 protocol stack comparison ( Large preview ). It also, however, takes a full network round trip to complete before anything else can be done on a connection. and lower), this typically takes two network round trips. For this reason, TCP is one of the most widely used and deployed protocols on the Internet.
The gotcha here is that, if your mobile experience isn’t optimized for various devices and network conditions, these customers will never appear in your analytics — just because your website or app will be barely usable on their devices, and so they are unlikely to return. Driving Business Metrics. LT Browser in action.
Reduced network and device capacity correlate with other access challenges. Teams I've consulted are too often wrenched between celebration over "the big rewrite" launch and the morning-after realisation that the new stack is tanking business metrics. Accessibility: Performance is the foundation of access. Photo by Jay Heike.
Their free plan offers limited features, including connection, shell management, monitoring, data manipulation, and support, and you can compare them here on their plan comparison page. Just like the rest, NoSQL Manager offers a free commercial as well as paid subscription plans. NoSQL Manager paid plans are available for $98/version/user.
It’s “single-threaded,” which is how we get the one-way street comparison. Total Blocking Time One thing I know would be more helpful than a set of Core Web Vitals scores from Lighthouse is knowing the time it takes to go from the First Contentful Paint (FCP) to the Time to Interactive (TTI), a metric known as the Total Blocking Time (TBT).
Failing that, we are usually able to connect to home or public WiFi networks that are on fast broadband connections and have effectively unlimited data. For comparison, the same amount of data costs $6.66 The speed of mobile networks, too, varies considerably between countries. As for mobile network connection type, 84.7%
There are three generations of GPUs that are relevant to this comparison. The Hopper H100 was announced in 2022 and is the current volume product that people are using, so that is used as the baseline for comparison. The HGX H100 8-GPU system is the baseline for comparison, and its datasheet performance is shownbelow.
This is a brief post to highlight the metrics to use to do the comparison using a separate hardware platform for illustration purposes. Metrics Connected Started CPU Metrics for Intel(R) Xeon(R) Platinum 8280L CPU @ 2.70GHz:(112 CPUs) hammerdb>tcstart Transaction Counter Started hammerdb>0 MariaDB tpm CPU all usr%-0.00
Next, we’ll look at how to set up servers and clients (that’s the hard part unless you’re using a content delivery network (CDN)). Using just a few (but still more than one), however, could nicely balance congestion growth with better performance, especially on high-speed networks. Servers and Networks. Network Configuration.
Key Metrics to consider for Cross Browser Testing. Here are some of the essential factors (or metrics) that should be factored in the cross-browser testing activity: 1. Network Throttling – If your app is built for a global audience, it is important to test the app features in varied network conditions (e.g.
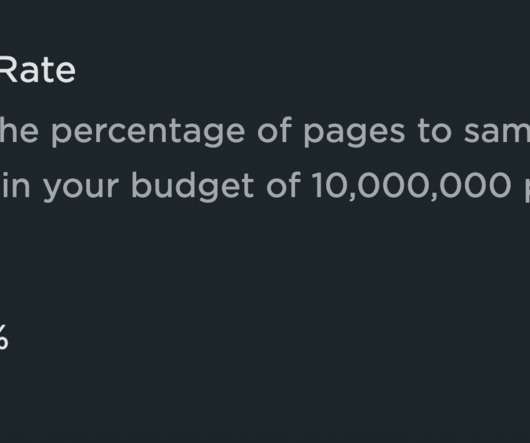
Not all metrics are created equal and I try to avoid picking favorites. This is true of many of the metrics we collect at SpeedCurve. To determine the smallest sample rate for each group, we looked at a combination of the aggregate numbers and a comparison of the histograms. This was a little tough. Increasing time windows.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content