This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Second, it enables efficient and effective correlation and comparison of data between various sources. Semconv for HTTP Spans quite possibly the most important signal have been declared stable, and HTTP Metrics will hopefully soon follow. At the same time, having aligned telemetry data is crucial for adopting OpenTelemetry at scale.
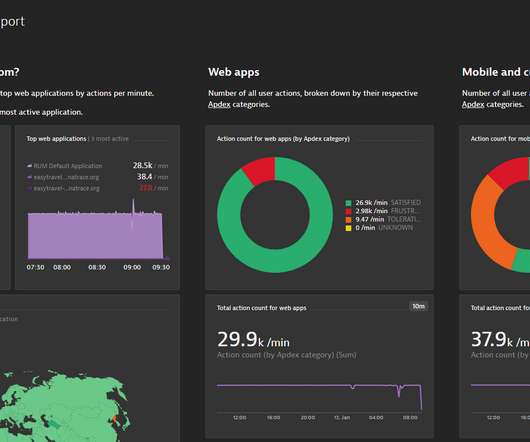
Select any execution you’re interested in to display its details, for example, the content response body, its headers, and related metrics. With the new Dynatrace Synthetic application, you can select any two executions for comparison. Details of requests sent during each monitor execution are also available.
All metrics, traces, and real user data are also surfaced in the context of specific events. With Dynatrace, you can create custom metrics based on user-defined log events. Comparison of Kubernetes log ingestion via Fluentd and Dynatrace OneAgent. So, let’s compare the two approaches for ingesting logs.
The second phase involves migrating the traffic over to the new systems in a manner that mitigates the risk of incidents while continually monitoring and confirming that we are meeting crucial metrics tracked at multiple levels. The batch job creates a high-level summary that captures some key comparisonmetrics.
This article takes a plunge into the comparative analysis of these two cult technologies, highlights the critical performance metrics concerning scalability considerations, and, through real-world use cases, gives you the clarity to confidently make an informed decision. However, the question arises of choosing the best one.
By implementing service-level objectives, teams can avoid collecting and checking a huge amount of metrics for each service. The performance SLO needs a custom SLI metric, which you can configure as follows. Once you define the SLI metric, you can create an SLO based on the number of requests with proper response time.
By collecting and analyzing key performance metrics of the service over time, we can assess the impact of the new changes and determine if they meet the availability, latency, and performance requirements. The results are then evaluated using specific metrics to determine whether the hypothesis is valid.
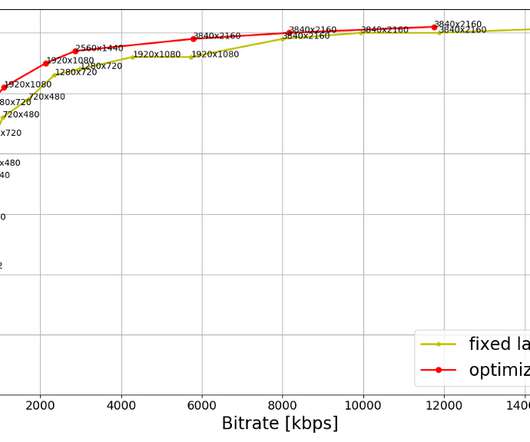
VMAF is a video quality metric that Netflix jointly developed with a number of university collaborators and open-sourced on Github. One aspect that differentiates VMAF from other traditional metrics such as PSNR or SSIM, is that VMAF is able to predict more consistently across spatial resolutions, across shots, and across genres (for example.
Consequently, this blog post highlights the new capability of the Site Reliability Guardian to define auto-adaptive thresholds that tackle the challenge of configuring static thresholds and protect your quality and security investments with relative comparisons to previous validations.
In Dynatrace, tagging also allows you to control access rights (via Management Zones), filter data on dashboards or via the API as well as allowing you to control calculation of custom service metrics or extraction of request attributes. This allows us to analyze metrics (SLIs) for each individual endpoint URL.
framework , the SNMP extensions are a bundle of everything that’s needed (DataSource configuration, a dashboard template, a unified analysis page template, topology definition, entity extraction rules, relevant metric definitions and more) to get going with monitoring. As with other extensions based on the new Dynatrace Extensions 2.0
Security vulnerabilities are checked throughout the lifecycle, including comparisons against previous releases. To enrich a release validation with security, simply add one of the out-of-the-box Dynatrace security metrics to your release validation dashboard.
Custom charts allow you to visualize metric performance over time, and USQL tiles allow you to dig deep into user session monitoring data. Aggregation metrics over a set of entities (global aggregation). Metriccomparisons over previous timeframes. Dynatrace dashboards support a variety of chart visualizations and tiles.
As for HDR, our team is currently developing an HDR extension to VMAF, Netflix’s video quality metric , which will then be used to optimize the HDR streams. ¹ This in turn allows us to compare error rates as well as various metrics related to quality of experience (QoE). The 8-bit stream profiles go up to 1080p resolution.
Architecture Comparison RabbitMQ and Kafka have distinct architectural designs that influence their performance and suitability for different use cases. Performance and Benchmark Comparison When comparing RabbitMQ and Kafka, performance factors such as throughput, latency, and scalability play a critical role.
With the release of Dynatrace 1.177, you can now do exactly this—our most recent dashboarding update provides a powerful comparison feature for all available dashboard tiles. Compare metrics and KPIs over time. Comparisons over time are necessary for analyzing trends. Other improvements.
Service-level indicators (SLIs) are checked against your SLOs early in the lifecycle, including comparison against previous builds. Automated comparison of different timeframes based on SLIs and SLOs. By identifying degradation in quality early in the lifecycle, remediation actions can be triggered automatically.
Most monitoring tools for migrations, development, and operations focus on collecting and aggregating the three pillars of observability— metrics, traces, and logs. Using a data-driven approach to size Azure resources, Dynatrace OneAgent captures host metrics out-of-the-box to assess CPU, memory, and network utilization on a VM host.
All metrics, traces, and real user data are also surfaced in the context of specific events. With Dynatrace, you can create custom metrics based on user-defined log events. Comparison of Kubernetes log ingestion via Fluentd and Dynatrace OneAgent. So, let’s compare the two approaches for ingesting logs.
Automated release inventory and version comparison , which allows teams to easily evaluate the performance of individual release versions, and as needed, roll back to a previous version. Automated release inventory and version comparison. ” – Wim Verhaeghe, KBI-Connect DevOps team lead at Inetum-Realdolmen.
Example NAM TCP test configuration The reporting also looks similar; easy-to-understand charts indicate the availability and performance of the whole network availability monitor, and metrics provide an overall summary and links to currently open problems. Overview and detailed requests comparison.
You’ll learn how to create production SLOs, to continuously improve the performance of services, and I’ll guide you on how to become a champion of your sport by: Creating calculated metrics with the help of multidimensional analysis. Metric 2: number of requests in error. Let’s start by creating a dashboard to follow our metrics.
Symptoms : No data is provided for affected metrics on dashboards, alerts, and custom device pages populated by the affected extension metrics. Select a specific queue or topic to display details about its connected producer and consumer services, as well as technology-specific metrics. Extension logs display errors.
It’s true that what might be considered the “most important” or “best” web performance metrics can vary by industry. These six metrics were not chosen at random – they work together to give you a snapshot of your site’s performance and overall user experience so you can set a baseline and improve speed and usability. Speed Index.
The comparison to an iceberg is appropriate in this case. You only need to flip a few settings toggles to activate critical Kubernetes alerts —there’s no need to research which essential metrics you need to alert on, learn a complex query language, figure out which metrics to use, or learn how to capture metrics.
As a part of the Citrix monitoring extension for Dynatrace, we deliver a OneAgent plugin that adds several Citrix-specific WMI counters to the set of metrics reported by OneAgent. These metrics help you understand whether your Citrix landscape is sized correctly for its load.
Organizations that have transitioned to agile software development strategies (including the adoption of a DevOps culture and continuous delivery automation) enforce automated solutions for such decision making—or at the very least, use automation in the gathering of a release-quality metrics.
In a unified strategy, logs are not limited to applications but encompass infrastructure, business events, and custom metrics. A prime example is when a business analyst requests information about how many units of a product were sold within the last month or wants to perform a year-to-year comparison. Set up processing rules.
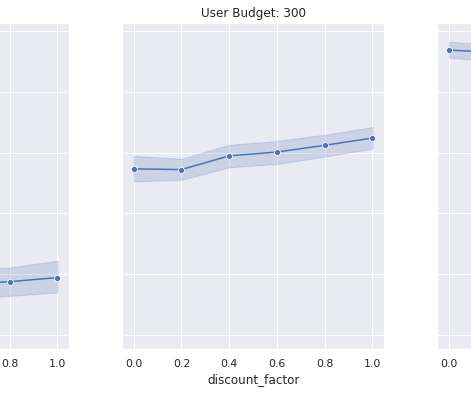
Metric A slate recommendation algorithm generates slates and then the user model is used to predict the success/failure of each slate. We compare the change in this metric for different user budget distributions. Paired comparison between RL and Contextual bandit. This is known as the SARSA algorithm.
In comparison, the AIOps approach discussed within this article, is built upon a radically different deterministic AI engine – at Dynatrace known as Davis – that yields precise, actionable results in real-time. metrics) but it’s just adding another dataset and not solving the problem of cause-and-effect certainty.
You’ll typically want to find a way to make a connection between a performance metric (such as First Meaningful Paint ) and a business metric (Conversion Rate). We’ve made your life easier by starting the comparison for you. The Simpsons Family = Web Performance Metrics. webperf #perfmatters Click To Tweet. Ned Flanders.
Observability provides deeper technical insights into what’s happening within cloud environments, in comparison to APM and/or traditional monitoring methods. And for observability to be successful, it requires much more than just logs, metrics, and traces. Traditional approaches and tooling simply don’t work in the new cloud world.
Application performance monitoring involves tracking key software application performance metrics using monitoring software and telemetry data. Application performance monitoring has a strong focus on specific metrics and measurements. Application performance management.
SREs face ever more challenging situations as environment complexity increases, applications scale up, and organizations grow: Growing dependency graphs result in blind spots and the inability to correlate performance metrics with user experience. Additionally, you can easily use any previously defined metrics and SLOs from your environments.
Bringing together metrics, logs, traces, problem analytics, and root-cause information in dashboards and notebooks, Dynatrace offers an end-to-end unified operational view of cloud applications. To observe model drift and accuracy, companies can use holdout evaluation sets for comparison to model data.
Since we began the series pointing out parallels to technical debt, let’s revisit that comparison. Examine large data sets, applying statistical correlation to uncover patterns in observable behaviors, including metrics, events, logs, and alerts. We make sub-optimal or under-informed choices under pressure. Machine learning systems.
In comparison, on-premises clusters have more and larger nodes: on average, 9 nodes with 32 to 64 GB of memory. In general, metrics collectors and providers are most common, followed by log and tracing projects. Kubernetes infrastructure models differ between cloud and on-premises.
There were languages I briefly read about, including other performance comparisons on the internet. According to other comparisons [Google for 'Performance of Programming Languages'] spread over the net, they clearly outshine others in all speed benchmarks. These include Python, PHP, Perl, and Ruby.
Modern observability has evolved from simple metric telemetry monitoring to encompass a wide range of data, including logs, traces, events, alerts, and resource attributes. The native multi-select feature lets users open a filtered group of problems simultaneously, facilitating quick comparisons and detailed analysis.
Scenario : For many B2B SaaS companies, the number of reported customers is an important metric. In this scenario, a manually triggered run of a production pipeline had the unintended consequence of duplicating the reported customer metric.
Having the right metrics available on demand and at a high resolution is key to understanding how a system behaves and helps to quickly troubleshoot performance issues. This makes it much easier for engineers to get the graphs they want arranged in a manner for comparisons and to focus in the required areas. is more clearly visible.
This is the Multiple Comparisons Problem , and there are a number of approaches to controlling the overall false positive rate that we’ll not cover here. Does the metric story hang together? even if, in truth, the null hypothesis is true in each case and there is no actual effect. In Part 2 (What is an A/B Test?),
The goal was to develop a custom solution that enables DevOps and engineering teams to analyze and improve pipeline performance issues and alert on health metrics across CI/CD platforms. Standardized reporting across all CI/CD vendors for easy comparison, including jobs/Errors/Duration charts for Pipelines/Stages/Steps.
The increasing vastness and diversity of what our members are watching make answering these questions particularly challenging using conventional methods, which draw on a limited set of comparable titles and their respective performance metrics (e.g., box office, Nielsen ratings). This challenge is also an opportunity.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content