This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The second phase involves migrating the traffic over to the new systems in a manner that mitigates the risk of incidents while continually monitoring and confirming that we are meeting crucial metrics tracked at multiple levels. It provides a good read on the availability and latency ranges under different production conditions.
Architecture Comparison RabbitMQ and Kafka have distinct architectural designs that influence their performance and suitability for different use cases. Its partitioned log architecture supports both queuing and publish-subscribe models, allowing it to handle large-scale event processing with minimal latency.
By implementing service-level objectives, teams can avoid collecting and checking a huge amount of metrics for each service. According to Google’s SRE handbook , best practices, there are “ Four Golden Signals ” we can convert into four SLOs for services: reliability, latency, availability, and saturation.
This article takes a plunge into the comparative analysis of these two cult technologies, highlights the critical performance metrics concerning scalability considerations, and, through real-world use cases, gives you the clarity to confidently make an informed decision. However, the question arises of choosing the best one.
Citrix platform performance—optimize your Citrix landscape with insights into user load and screen latency per server. As a part of the Citrix monitoring extension for Dynatrace, we deliver a OneAgent plugin that adds several Citrix-specific WMI counters to the set of metrics reported by OneAgent.
Plotted on the same horizontal axis of 1.6s, the waterfalls speak for themselves: 201ms of cumulative latency; 109ms of cumulative download. 4,362ms of cumulative latency; 240ms of cumulative download. When we talk about downloading files, we—generally speaking—have two things to consider: latency and bandwidth. It gets worse.
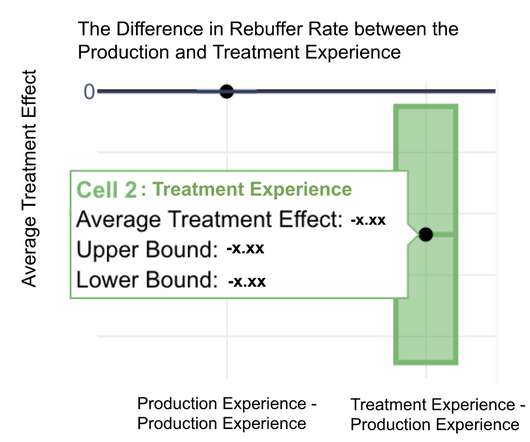
By collecting and analyzing key performance metrics of the service over time, we can assess the impact of the new changes and determine if they meet the availability, latency, and performance requirements. The results are then evaluated using specific metrics to determine whether the hypothesis is valid.
SREs use Service-Level Indicators (SLI) to see the complete picture of service availability, latency, performance, and capacity across various systems, especially revenue-critical systems. Additionally, you can easily use any previously defined metrics and SLOs from your environments.
Today we are excited to announce latency heatmaps and improved container support for our on-host monitoring solution?—?Vector?—?to Remotely view real-time process scheduler latency and tcp throughput with Vector and eBPF What is Vector? to the broader community. Vector is open source and in use by multiple companies.
Bringing together metrics, logs, traces, problem analytics, and root-cause information in dashboards and notebooks, Dynatrace offers an end-to-end unified operational view of cloud applications. To observe model drift and accuracy, companies can use holdout evaluation sets for comparison to model data.
Citrix platform performance—optimize your Citrix landscape with insights into user load and screen latency per server. As a part of the Citrix monitoring extension for Dynatrace, we deliver a OneAgent plugin that adds several Citrix-specific WMI counters to the set of metrics reported by OneAgent.
Historically, NoSQL paid a lot of attention to tradeoffs between consistency, fault-tolerance and performance to serve geographically distributed systems, low-latency or highly available applications. Read/Write latency. Read/Write requests are processes with a minimal latency. Data Placement. Read/Write scalability.
This freshness measurement can then be used by out-of-the-box Dynatrace anomaly detection to actively alert on abnormal changes within the data ingest latency to ensure the expected freshness of all the data records. Scenario : For many B2B SaaS companies, the number of reported customers is an important metric.
Perceptual quality measurements are used to drive video encoding optimizations , perform video codec comparisons , carry out A/B testing and optimize streaming QoE decisions to mention a few. In particular, the VMAF metric lies at the core of improving the Netflix member’s streaming video quality. Assembly for two of the metrics (e.g.
We use Sysbench to benchmark key performance metrics under different workloads and thread configurations, including Transactions Per Second (TPS) and Queries Per Second (QPS). Key metrics include TPS and QPS. Test Environment Setup Instance Types : We used similar cloud instances for AWS RDS and ScaleGrid to ensure a fair comparison.
Technically, “performance” metrics are those relating to the responsiveness or latency of the app, including start up time. At Netflix the term “performance” usually encompasses both performance metrics (in the strict meaning) and memory metrics, and that’s how we’re using the term here. What do we mean by Performance?
Compared to the most recent master version of libaom (AV1 reference software), SVT-AV1 is similar in compression efficiency and at the same time achieves significantly lower encoding latency on multi-core platforms when using its inherent parallelization capabilities. The plot shows the results of the 2-pass encoding mode in both codecs.
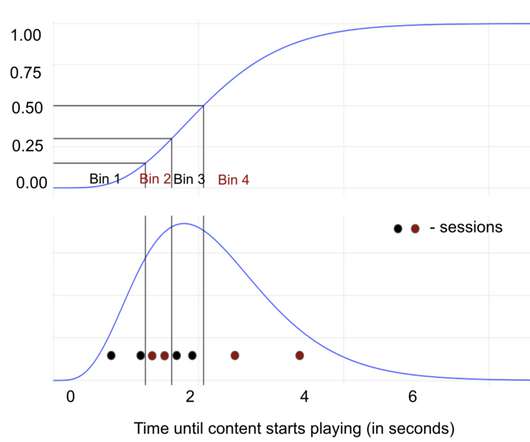
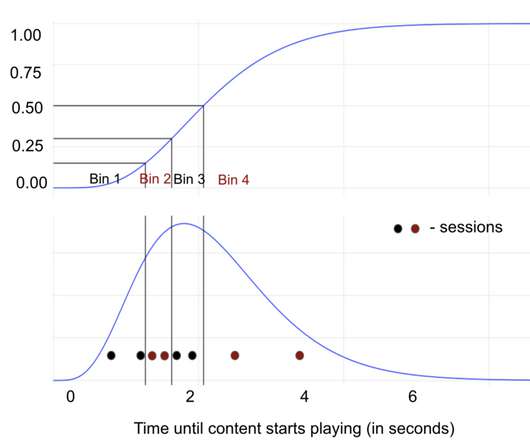
QoE is measured with a compilation of metrics that describe everything about the user’s experience from the time they press play until the time they finish watching. Examples of such metrics include how quickly the content starts playing and the number of times the video froze during playback (number of rebuffers).
QoE is measured with a compilation of metrics that describe everything about the user’s experience from the time they press play until the time they finish watching. Examples of such metrics include how quickly the content starts playing and the number of times the video froze during playback (number of rebuffers).
The metrics that we report against implicitly cleave these into different "camps", leaving us thinking about pre- and post-load as distinct universes. The chief effect of the architectural difference is to shift the distribution of latency within the loop. Improving latency for one scenario can degrade it in another.
Load averages are an industry-critical metric – my company spends millions auto-scaling cloud instances based on them and other metrics – but on Linux there's some mystery around them. But to understand them in more detail is difficult without the aid of other metrics. Latency was acceptable and no one complained.
Along with other general diagnostics and web performance metrics, a really useful feature of the report is that each of the key areas is aggregated into color-coded scores between 0-100. These are the numerical key performance metrics collected as part of any Lighthouse report. How should the metriccomparison be output to the console?
QoE is measured with a compilation of metrics that describe everything about the user’s experience from the time they press play until the time they finish watching. Examples of such metrics include how quickly the content starts playing and the number of times the video froze during playback (number of rebuffers).
This approach often leads to heavyweight high-latency analytical processes and poor applicability to realtime use cases. Computation of more advanced metrics like a number of unique visitor or most frequent items is more challenging and requires a lot of resources if implemented straightforwardly. Heavy Hitters: Stream-Summary.
In-Memory Storage Engine, as the name suggests, stores data in memory for faster performance and lower latencies. Feature Comparison: MMAPV1 vs WiredTiger MMAPV1 provides document-level locking that allows for independent updates on different documents in a single collection. released in December 2015.
Rather than waiting for equipment to fail, preventive maintenance, via things like real-time decisioning , schedules tasks based on time intervals or usage metrics, enhancing productivity and cost-effectiveness and preventing costly downtime. This approach works well for equipment with variable usage.
This is a complex topic, but to borrow from a recent post , web performance expands access to information and services by reducing latency and variance across interactions in a session, with a particular focus on the tail of the distribution (P75+). Consistent performance matters just as much as low average latency.
The header is constructed via a name with an optional description and/or metric value. Web browsers expose a global Performance Timeline API to inspect details about specific metrics/events that have happened during the page lifecycle. Any server or proxy can add this header to the request to provide inspectable data.
Here’s how the same test performed when running Percona Distribution for PostgreSQL 14 on these same servers: Queries: reads Queries: writes Queries: other Queries: total Transactions Latency (95th) MySQL (A) 1584986 1645000 245322 3475308 122277 20137.61 MySQL (B) 2517529 2610323 389048 5516900 194140 11523.48
This is a brief post to highlight the metrics to use to do the comparison using a separate hardware platform for illustration purposes. Metrics Connected Started CPU Metrics for Intel(R) Xeon(R) Platinum 8280L CPU @ 2.70GHz:(112 CPUs) hammerdb>tcstart Transaction Counter Started hammerdb>0 MariaDB tpm CPU all usr%-0.00
There are three generations of GPUs that are relevant to this comparison. The Hopper H100 was announced in 2022 and is the current volume product that people are using, so that is used as the baseline for comparison. The HGX H100 8-GPU system is the baseline for comparison, and its datasheet performance is shownbelow.
In fact, there’s great tooling right under the hood of most browsers in DevTools that can do many things that a tried-and-true service like WebPageTest offers, complete with recommendations for improving specific metrics. Certain tools are designed for certain metrics with certain assumptions that produce certain results.
People say JAMstack sites are fast — let’s find out why by looking at real performance metrics! We’ll cover common metrics, like Time to First Byte ( TTFB ) among others, then compare data across a wide section of sites to see how different ways to slice those sites up compare. seconds to see primary content. Time To First Byte.
So it’s interesting to see a paper using nano-Joules per prediction as an evaluation metric. The resulting system can integrate seamlessly into a scikit-learn based development process, and dramatically reduces the total energy usage required for classification with very low latency. Introducing race logic. Performance evaluation.
But of bigger concern is the latency between the time when requirements are captured and the time they're available as working code in an environment. By comparison, Agile maintains a steady pace of progress by having all of functional efforts simultaneously focused on achieving the same result.
Another window into this question is provided by the Web Confluence Metrics project. For heavily latency-sensitive use-cases like WebXR, this is a critical component in delivering a good experience. Thankfully, the advent of M1 Macs makes it possible to remove hardware differences from comparisons. Converging Views.
You’ve probably heard things like: “HTTP/3 is much faster than HTTP/2 when there is packet loss”, or “HTTP/3 connections have less latency and take less time to set up”, and probably “HTTP/3 can send data more quickly and can send more resources in parallel”. HTTP/2 versus HTTP/3 protocol stack comparison ( Large preview ).
Stored Procedures and Client SQL comparison To test the stored procedures and client implementations, we ran both workloads against a system equipped with Intel Xeon 8280L. Use the performance metrics available in the database first before looking at data further down in the stack. On MySQL, we saw a 1.5X performance advantage.
This reduces friction and commensurately increases "engagement" metrics. [6]. Many have adroitly covered the perspective and ethical distortions within social media firms caused by the relentless pursuit of "north star" metrics. There's little new I can add. Apple's right to worry about engine security.
Finally, not inlining resources has an added latency cost because the file needs to be requested. If you do any comparison of this sort yourself (or if you read articles that do), make 100% sure that you’ve checked what’s actually going on. In our own early tests , I found seriously diminishing returns at about 40 files.
For each test, I captured the following metrics: First Paint (FP): To what extent is the critical path affected? I’m happy to say, for the metrics that matter the most, we are 700–1,200ms faster. Visually complete was 200ms faster , but any first- metrics were untouched. On a high-latency connection, this spells bad news.
Key user-centric metrics often depend on the size, number, layout, and loading priority of images on the page. Smaller file size directly impacts the Largest contentful Paint (LCP) metric for the page as image resources needed by the page get loaded faster. See the Pen [Image format comparison 2]([link] by Addy Osmani.
Because we are dealing with network protocols here, we will mainly look at network aspects, of which two are most important: latency and bandwidth. Latency can be roughly defined as the time it takes to send a packet from point A (say, the client) to point B (the server). Two-way latency is often called round-trip time (RTT).
LogRocket tracks key metrics, incl. Getting Ready: Planning And Metrics Performance culture, Core Web Vitals, performance profiles, CrUX, Lighthouse, FID, TTI, CLS, devices. Getting Ready: Planning And Metrics. DOM complete, time to first byte, first input delay, client CPU and memory usage. Get a free trial of LogRocket today.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content