This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Both Redis and Memcached are: NoSQL in-memory data structures Written in C Open source Used to speed up applications Support sub-millisecond latency In 2014, Salvatore wrote an excellent StackOverflow post on […]. Memcached, on the other hand, was created in 2003 by Brad Fitzpatrick.
Architecture Comparison RabbitMQ and Kafka have distinct architectural designs that influence their performance and suitability for different use cases. Its partitioned log architecture supports both queuing and publish-subscribe models, allowing it to handle large-scale event processing with minimal latency.
Timestone: Netflix’s High-Throughput, Low-Latency Priority Queueing System with Built-in Support for Non-Parallelizable Workloads by Kostas Christidis Introduction Timestone is a high-throughput, low-latency priority queueing system we built in-house to support the needs of Cosmos , our media encoding platform. In comparison, we see 1.2K
It provides a good read on the availability and latency ranges under different production conditions. The upstream service calls the existing and new replacement services concurrently to minimize any latency increase on the production path. The batch job creates a high-level summary that captures some key comparison metrics.
ScaleGrid MySQL on Azure so you can see which provider offers the best throughput and latency performance. We measure latency in ms 95th percentile latency. During Read-Intensive Workloads, ScaleGrid manages to achieve up to 3 times higher throughput and averages 66% better latency compared to Azure Database.
Compare Latency. lower latency compared to DigitalOcean for PostgreSQL. Now, let’s take a look at the throughput and latency performance of our comparison. Next, we are going to test and compare the latency performance between ScaleGrid and DigitalOcean for PostgreSQL. PostgreSQL DigitalOcean Latency Averages (ms).
Here are the configurations for this comparison: Plan. Does it affect latency? Yes, you can see an increase in latency. So, if you’re hosting your application in AWS or Azure and move your database to DigitalOcean, you will see an increase in latency. Dedicated Hosting. MongoDB® Database. Replication Strategy.
We compare throughput, operations per second, and latency under different loads, namely the P90 and P99 percentiles. This level of comparison detail will assist decision-makers with the information they would need to make a more appropriate choice of an in-memory data store for their needs.
According to Google’s SRE handbook , best practices, there are “ Four Golden Signals ” we can convert into four SLOs for services: reliability, latency, availability, and saturation. Latency is the time that it takes a request to be served. Define SLOs for each service. Reliability.
Compare Latency. On average, ScaleGrid achieves almost 30% lower latency over DigitalOcean for the same deployment configurations. We are going to use a common, popular plan size using the below configurations for this performance benchmark: Comparison Overview. Read-Intensive Latency Benchmark. Compare Pricing.
Plotted on the same horizontal axis of 1.6s, the waterfalls speak for themselves: 201ms of cumulative latency; 109ms of cumulative download. 4,362ms of cumulative latency; 240ms of cumulative download. When we talk about downloading files, we—generally speaking—have two things to consider: latency and bandwidth. It gets worse.
Let us take a look also the latency: Here the situation starts to be a little bit more complicated. MySQL Router is the one that has the higher latency no matter what. Looking at the latency, we can see that HAProxy gradually increased as expected, while ProxySQL and MySQL Router just went up from the 256 threads on.
Citrix platform performance—optimize your Citrix landscape with insights into user load and screen latency per server. Comparison of these metrics between VDAs characterizes load balancing efficiency. Citrix latency represents the end-to-end “screen lag” experienced by a server’s users. Citrix VDA. SAP server. Citrix VDA.
SREs use Service-Level Indicators (SLI) to see the complete picture of service availability, latency, performance, and capacity across various systems, especially revenue-critical systems. Davis will also assist Site Reliability Guardian in recommending relevant objectives and baselines for comparison.
By collecting and analyzing key performance metrics of the service over time, we can assess the impact of the new changes and determine if they meet the availability, latency, and performance requirements. One can perform this comparison live on the request path or offline based on the latency requirements of the particular use case.
Today we are excited to announce latency heatmaps and improved container support for our on-host monitoring solution?—?Vector?—?to Remotely view real-time process scheduler latency and tcp throughput with Vector and eBPF What is Vector? to the broader community. Vector is open source and in use by multiple companies.
Historically, NoSQL paid a lot of attention to tradeoffs between consistency, fault-tolerance and performance to serve geographically distributed systems, low-latency or highly available applications. Read/Write latency. Read/Write requests are processes with a minimal latency. Data Placement. Read/Write scalability.
While there is plenty of well-documented benefits to using a connection pooler, there are some arguments to be made against using one: Introducing a middleware in the communication inevitably introduces some latency. A middleware becomes a single point of failure.
Uploading and downloading data always come with a penalty, namely latency. Figure 3: Video Processing with Index and Virtual Assembly Using virtual assembly greatly improves the latency performance of the ProRes 422 HQ proxy generation by removing one round trip of cloud downloading and cloud uploading by the physical assembler.
For production models, this provides observability of service-level agreement (SLA) performance metrics, such as token consumption, latency, availability, response time, and error count. To observe model drift and accuracy, companies can use holdout evaluation sets for comparison to model data.
Citrix platform performance—optimize your Citrix landscape with insights into user load and screen latency per server. Comparison of these metrics between VDAs characterizes load balancing efficiency. Citrix latency represents the end-to-end “screen lag” experienced by a server’s users. Citrix VDA. SAP server. Citrix VDA.
Although this response has a 0B filesize, we will always take the latency hit on every single page view (and this response is basically 100% latency). com , which introduces yet more latency for the connection setup. If you’re interested in seeing a real-world example of this, consider the following filmstrip comparison.
In this comparison of Redis vs Memcached, we strip away the complexity, focusing on each in-memory data store’s performance, scalability, and unique features. Performance Comparison: Redis vs Memcached Although Redis and Memcached are high-performance in-memory data stores, their performance characteristics are distinct.
Perceptual quality measurements are used to drive video encoding optimizations , perform video codec comparisons , carry out A/B testing and optimize streaming QoE decisions to mention a few. This enables us to use our scale to increase throughput and reduce latencies. VQS is called using the measureQuality endpoint.
For a more detailed comparison of performance features between different versions, refer to: [link] Benchmarking Methodology Sysbench Overview Sysbench is a versatile, open-source benchmarking tool ideal for testing OLTP (Online Transaction Processing) database workloads. It also enhanced the management of large tables and indexes.
This freshness measurement can then be used by out-of-the-box Dynatrace anomaly detection to actively alert on abnormal changes within the data ingest latency to ensure the expected freshness of all the data records. Solution : Like the freshness example, Dynatrace can monitor the record count over time.
The chief effect of the architectural difference is to shift the distribution of latency within the loop. Herein lies the source of our collective anxiety about front-end architectures: traversing networks is always fraught, but the costs to deliver client-side logic to cushion users from variable network latency remain stubbornly high.
Snappy Data size: 14.95GB Data size after compression: 10.75GB Avg latency: 12.22ms Avg cpu usage: 34% Avg insert ops rate: 16K/s Time taken to import 120000000 document: 7292 seconds Zstd (with default compression level 6) Data size: 14.95GB Data size after compression: 7.69GB Avg latency: 12.52ms Avg cpu usage: 31.72% Avg insert ops rate: 14.8K/s
Using a fast DNS hosting provider ensures there is less latency between the DNS lookup and TTFB. Visit website DNS hosting providers comparison How do the free DNS providers stack up against the premium DNS services? DNS speed comparison report Who offers the best free DNS? Speed Speed also plays a role with DNS.
Edge servers are the middle ground – more compute power than a mobile device, but with latency of just a few ms. The client MWW combines these estimates with an estimate of the input/output transmission time (latency) to find the worker with the minimum overall execution latency. for the wasm-version.
Quick summary : Node vs React Comparison is not correct because both technologies are entirely different things. Node JS vs. React JS Comparison. with its low latency I/O operations, gives the benefit of ‘No buffering’ to developers. Now, let us make a comparison between React and Node.js. Node JS vs. React JS Comparison.
Compared to the most recent master version of libaom (AV1 reference software), SVT-AV1 is similar in compression efficiency and at the same time achieves significantly lower encoding latency on multi-core platforms when using its inherent parallelization capabilities.
With this in mind, the requirements of this compare functionality ought to be: If a previous report already exists for the same website when a Lighthouse audit is complete, automatically perform a comparison against it and show any changes to key performance metrics. If your latency is higher than 50ms, users may perceive your app as laggy.
In-Memory Storage Engine, as the name suggests, stores data in memory for faster performance and lower latencies. Feature Comparison: MMAPV1 vs WiredTiger MMAPV1 provides document-level locking that allows for independent updates on different documents in a single collection. released in December 2015.
This makes the whole system latency sensitive. So we need low latency, but we also need very high throughput: A recurring theme in IDS/IPS literature is the gap between the workloads they need to handle and the capabilities of existing hardware/software implementations.
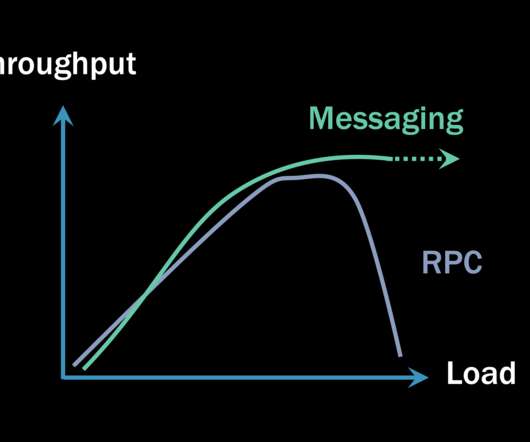
Some will claim that any type of RPC communication ends up being faster (meaning it has lower latency) than any equivalent invocation using asynchronous messaging. It’s less of an apples-to-oranges comparison and more like apples-to-orange-sherbet. There are more steps, so the increased latency is easily explained.
Technically, “performance” metrics are those relating to the responsiveness or latency of the app, including start up time. While test metrics and metrics collected during real use do not lend themselves to direct comparison, measuring the relative change in metrics in pre-production builds can help us to anticipate regressions in production.
DLVs are particularly advantageous for databases with large allocated storage, high I/O per second (IOPS) requirements, or latency-sensitive workloads. The DLV, of course, affects the WRITE operations the most, and hence, the write-only test should be given the most consideration for the comparison of the DLV configuration vs. standard RDS.
Some people have found values that seem to work for their systems and workloads: they know that when load goes over X, application latency is high and customers start complaining. Latency was acceptable and no one complained. Load averages measured in a modern tool. But there aren't really rules for this.
A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. As I'm interested in the relative comparison I can just compare the total runtimes (the "real" time) for the same result. I've shared many posts about superpower observability tools, but often humble hacking is just as effective.
To measure statistical significance, we use an efficient bootstrapping procedure to create confidence intervals and p-values for all quantiles (with adjustments to account for multiple comparisons). The encoding team then understands the improvement in perceptual video quality for members who experience the worst video quality.
This approach often leads to heavyweight high-latency analytical processes and poor applicability to realtime use cases. This process is shown in the figure below: It is clear that if sketch is large in comparison with the cardinality of the data set, almost each value will get an independent counter and estimation will precise.
Here’s how the same test performed when running Percona Distribution for PostgreSQL 14 on these same servers: Queries: reads Queries: writes Queries: other Queries: total Transactions Latency (95th) MySQL (A) 1584986 1645000 245322 3475308 122277 20137.61 MySQL (B) 2517529 2610323 389048 5516900 194140 11523.48
Here’s a quick comparison: Preventive maintenance: Planned in advance, cost-effective, reduces downtime, and improves reliability. Reactive Maintenance Preventive maintenance is a proactive strategy, while reactive maintenance is a reactive approach, addressing problems only after they arise.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content