This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Second, it enables efficient and effective correlation and comparison of data between various sources. Receiving data from multiple sources, cleaning it up, and sending it to the desired backend systems reliably and efficiently is no small feat. Thats where the OpenTelemetry Collector can help. milestone.
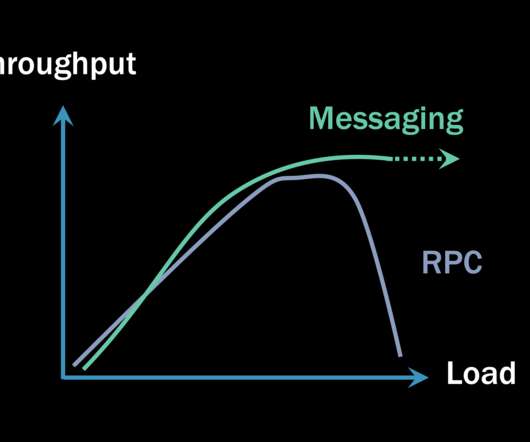
Kafka scales efficiently for large data workloads, while RabbitMQ provides strong message durability and precise control over message delivery. Message brokers handle validation, routing, storage, and delivery, ensuring efficient and reliable communication. What is RabbitMQ?
JSONB supports indexing the JSON data, and is very efficient at parsing and querying the JSON data. JSONB storage has some drawbacks vs. traditional columns: PostreSQL does not store column statistics for JSONB columns. JSONB storage results in a larger storage footprint. It is a decomposed binary format to store JSON.
MongoDB offers several storage engines that cater to various use cases. The default storage engine in earlier versions was MMAPv1, which utilized memory-mapped files and document-level locking. The newer, pluggable storage engine, WiredTiger, addresses this by using prefix compression, collection-level locking, and row-based storage.
Figure 1: A Simplified Video Processing Pipeline With this architecture, chunk encoding is very efficient and processed in distributed cloud computing instances. From chunk encoding to assembly and packaging, the result of each previous processing step must be uploaded to cloud storage and then downloaded by the next processing step.
We have been leveraging machine learning (ML) models to personalize artwork and to help our creatives create promotional content efficiently. Media Feature Storage: Amber Storage Media feature computation tends to be expensive and time-consuming. We accomplish this by paving the path to: Accessing and processing media data (e.g.
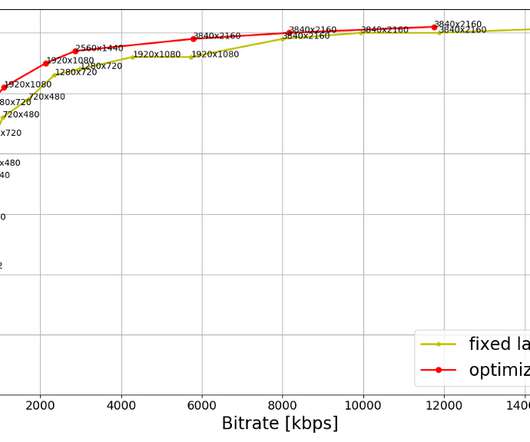
Bitrate versus quality comparison For a sample of titles from the 4K collection, the following plots show the rate-quality comparison of the fixed-bitrate ladder and the optimized ladder. Mbps, is for a 4K animation title episode which can be very efficiently encoded. The 8-bit stream profiles go up to 1080p resolution.
ScaleGrid provides 30% more storage on average vs. DigitalOcean for MySQL at the same affordable price. We are going to use a common, popular plan size using the below configurations for this performance benchmark: Comparison Overview. Compare Latency. Compare Pricing. MySQL DigitalOcean Performance Benchmark. DigitalOcean.
Davis AI efficiently identified the deployment change as the potential root cause for the malfunctioning of nginx. The framework outlined above provides a comprehensive view of the deployment process and facilitates comparisons across different releases. To illustrate this concept, consider the scenario below.
We can start by dialing traffic in a single data center to allow for an easier side-by-side comparison of key metrics across data centers, thereby making it easier to observe any deviations in the metrics. One can perform this comparison live on the request path or offline based on the latency requirements of the particular use case.
Bitrate versus quality comparison HDR-VMAF is designed to be format-agnostic — it measures the perceptual quality of HDR video signal regardless of its container format, for example, Dolby Vision or HDR10. This is achieved by more efficiently spacing the ladder points, especially in the high-bitrate region. The graphic below (Fig.
Citrix is a sophisticated, efficient, and highly scalable application delivery platform that is itself comprised of anywhere from hundreds to thousands of servers. Dynatrace automation and AI-powered monitoring of your entire IT landscape help you to engage your Citrix management tools where they are most efficient.
In this comparison of Redis vs Memcached, we strip away the complexity, focusing on each in-memory data store’s performance, scalability, and unique features. This article will explore how they handle data storage and scalability, perform in different scenarios, and, most importantly, how these factors influence your choice.
In this article I provide a short comparison of NoSQL system families from the data modeling point of view and digest several common modeling techniques. And this was where a new evolution of data models began: Key-Value storage is a very simplistic, but very powerful model. 10) Inverted Search – Direct Aggregation.
These developments gradually highlight a system of relevant database building blocks with proven practical efficiency. In comparison with pure anti-entropy, this greatly improves consistency with a relatively small performance penalty. System Coordination. It can be considered as a kind of targeted anti-entropy.
Compression in any database is necessary as it has many advantages, like storage reduction, data transmission time, etc. Storage reduction alone results in significant cost savings, and we can save more data in the same space. By default, MongoDB provides a snappy block compression method for storage and network communication.
Continuous improvement of services is the most efficient process for all teams that are looking to improve the performance of their applications by considering all layers of their architecture. Similar to an athlete, the objective here is to have teams always push the limits to become faster and stronger.
The results will help database administrators and decision-makers choose the right platform for their performance, scalability, and cost-efficiency needs. Test Environment Setup Instance Types : We used similar cloud instances for AWS RDS and ScaleGrid to ensure a fair comparison. Storage I/O : Both ScaleGrid and RDS use GP3.
A Dedicated Log Volume (DLV) is a specialized storage volume designed to house database transaction logs separately from the volume containing the database tables. This separation aims to streamline transaction write logging, improving efficiency and consistency. Who can benefit from DLV? and later v10 versions MySQL: 8.0.28
Overall, 53% of IT leaders say t he number of tools needed to monitor the end-to-end technology stack makes it difficult to operate efficiently. When issues arise, teams can’t depend on these tools for quick resolutions, because data comparisons are difficult and contribute to delays.
Real-world examples like Spotify’s multi-cloud strategy for cost reduction and performance, and Netflix’s hybrid cloud setup for efficient content streaming and creation, illustrate the practical applications of each model. Thus making it an ideal choice for businesses seeking a successful implementation of their multi-cloud strategy.
Citrix is a sophisticated, efficient, and highly scalable application delivery platform that is itself comprised of anywhere from hundreds to thousands of servers. Dynatrace automation and AI-powered monitoring of your entire IT landscape help you to engage your Citrix management tools where they are most efficient. Dynatrace news.
Perceptual quality measurements are used to drive video encoding optimizations , perform video codec comparisons , carry out A/B testing and optimize streaming QoE decisions to mention a few. Video quality has matured in Cosmos and we are invested in making VQS more flexible and efficient.
On the other hand, when one is interested only in simple additive metrics like total page views or average price of conversion, it is obvious that raw data can be efficiently summarized, for example, on a daily basis or using simple in-stream counters. bits per unique value. Frequency Estimation: Count-Min Sketch.
An apples to apples comparison of the costs associated with running various usage patterns on-premises and with AWS requires more than a simple comparison of hardware expense versus always-on utility pricing for compute and storage. Massive economies of scale and efficiency improvements allow AWS to continually lower prices.
Categories can contain thousands of products and user cannot efficiently search though this array without powerful tools. The rationale behind these methods is that frontend should be able to fetch transient information very efficiently and separately from fetching of heavy-weight domain entities because this information cannot be cached.
Below you will find a short FAQ about the new operator and a comparison to version 1.x. Whether you’re deploying PostgreSQL for the first time or looking for a more efficient way to manage your existing environment, Percona Operator for PostgreSQL has everything you need to get the job done. In version 1.x,
In this blog post, we will review key topics to consider for managing large datasets more efficiently in MySQL. Redundant indexes: It is known that accessing rows by fetching an index is more efficient than through a table scan in most cases. It can help us to save costs on storage and backup times.
Further, open source databases can be modified in infinite ways, enabling institutions to meet their specific needs for data storage, retrieval, and processing. Non-relational databases: Instead of tables, non-relational (NoSQL) databases use document-based data storage, column-oriented storage, and graph databases.
It progressed from “raw compute and storage” to “reimplementing key services in push-button fashion” to “becoming the backbone of AI work”—all under the umbrella of “renting time and storage on someone else’s computers.” ” (It will be easier to fit in the overhead storage.)
The challenging thing of course, is efficiently maintaining all of these parallel universes. If we do that naively though, we’re going to end up with a lot of universes to store and maintain and the storage requirements alone will be prohibitive. These ideas make an efficient multiverse database possible.
It’s less of an apples-to-oranges comparison and more like apples-to-orange-sherbet. Meanwhile, the garbage collector (or whatever manages memory in your runtime environment) is trying to make things efficient by cleaning up memory that’s not used anymore. But the answer isn’t that simple. Let’s take a look at the bigger picture. ??
tl;dr: I don’t want C++ to limit what I can express efficiently. Efficiency. The rules that are not efficient enough to implement in the compiler will always be relegated to optional standalone tools. That’s pretty easy to statically guarantee, except for some cases of the unused parts of lazily constructed array/vector storage.
For comparison, the server bar also shows performance when the full application runs on the server. Future work includes delving into more realistic use cases and addressing other challenges related to mobile computing such as energy efficiency. In the physics app edge processing yields 1.6x for the wasm-version.
Character encoding refers to the method used to represent characters as binary data for storage and transmission. The choice of character set and encoding impacts not only efficiency but also how the data appears to users. This difference in storage size can lead to variations in the size of index entries, which can impact efficiency.
Hash keys are used effectively and efficiently in cases where ranges are not applicable, like employee number, product ID, etc. What if the data is out of range or list? For this purpose, we use default partitions on range and list partitioned tables. Further details will be explained in upcoming blogs.
Teaching rigorous distributed systems with efficient model checking Michael et al., During the ten week course, students implement four different assignments: an exactly-once RPC protocol; a primary-backup system; Paxos; and a scalable, transactional key-value storage system. EuroSys’19.
This table uses columnstore for its primary storage to produce batch mode execution later on. Here is the new SUM plan for comparison with the one from the first test: All 102,400 rows (in 114 batches) are emitted by the Columnstore Index Scan , processed by the Compute Scalar , and sent to the Hash Aggregate. c1 = @Start + N.
On the other hand, one can implement this system with encryption/decryption units between the compute and the storage. This allows the same database to be implemented while removing storage and connections from the trust boundary. These two techniques serve complementary purposes: Probabilistic encryption hides data stored at rest.
Bloom filters present a space- and time-efficient alternative when a simple bitmap is infeasible due to space requirements. This is much less efficient than segment elimination or filtering during the columnstore scan, but it is still better than filtering at the hash join itself. LTGT for a less than/greater than comparison).
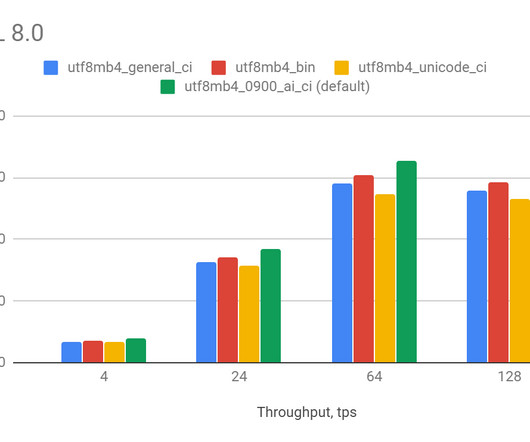
In this blog, we’ll provide a comparison between MariaDB vs. MySQL (including Percona Server for MySQL ). MariaDB retains compatibility with MySQL, offers support for different programming languages, including Python, PHP, Java, and Perl, and works with all major open source storage engines such as MyRocks, Aria, and InnoDB.
It consists of a combination of right practices and tools which help QA to test the software more effectively and efficiently. Building an efficient testing automation framework takes time but it is worth the efforts considering the long-term benefits. How to Build a Test Automation Framework from Scratch.
Because structured bindings behave like references, constexpr structured bindings are subject to similar restrictions as constexpr references, and supporting this feature required relaxing the previous rule that a constexpr reference must bind to a variable with static storage duration. Ive already implemented this in cppfront.)
One efficient way of doing that in analog hardware is the use of current-starved inverters. The evaluation is performed using the MNIST dataset, since that has the most results available in the literature for comparison. One such possible representation is pure analog signalling. Performance evaluation.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content