This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
OpenTelemetry is enhancing GenAI observability : By defining semantic conventions for GenAI and implementing Python-based instrumentation for OpenAI, OpenTel is moving towards addressing GenAI monitoring and performance tuning needs. Second, it enables efficient and effective correlation and comparison of data between various sources.
Built and maintained by Oracle, it provides an all-in-one solution for database modeling, query execution, user administration, and performance monitoring. Its a solid choice if you want a full-featured MySQL development environment. MySQL Workbench is a strong starting point if you want something official and comprehensive.
Kafka scales efficiently for large data workloads, while RabbitMQ provides strong message durability and precise control over message delivery. Message brokers handle validation, routing, storage, and delivery, ensuring efficient and reliable communication. This allows Kafka clusters to handle high-throughput workloads efficiently.
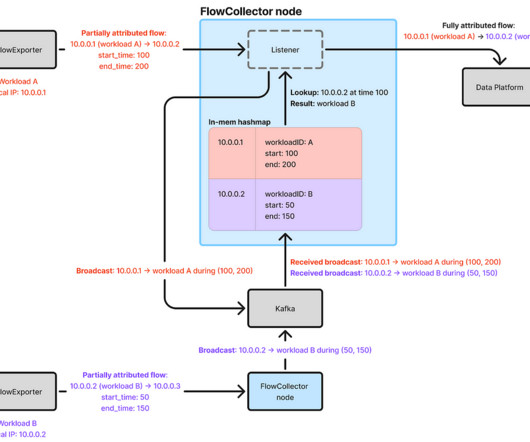
It uses eBPF and TCP tracepoints to monitor TCP socket state changes. Although more efficient broadcasting implementations exist, the Kafka-based approach is simple and has worked well forus. In this post, we delve deeper into how Netflix solved a core problem: accurately attributing flow IP addresses to workload identities.
The resulting vast increase in data volume highlights the need for more efficient data handling solutions. Consolidate log management tools into a unified observability platform As businesses increasingly shift toward software-centric models, the number of specialized IT monitoring tools to manage cloud environments has proliferated.
Most monitoring tools for migrations, development, and operations focus on collecting and aggregating the three pillars of observability— metrics, traces, and logs. Performance efficiency. Continuously monitor cost and optimize your capacity needs. Analyzing user experience to ensure uniform performance after migration.
A small percentage of production traffic is redirected to the two new clusters, allowing us to monitor the new version’s performance and compare it against the current version. At every step, relevant stakeholders are informed, and key metrics are monitored, including service, device, operational, and business metrics.
Having released this functionality in an Preview Release back in September 2019, we’re now happy to announce the General Availability of our Citrix monitoring extension. Citrix is a sophisticated, efficient, and highly scalable application delivery platform that is itself comprised of anywhere from hundreds to thousands of servers.
Model observability provides visibility into resource consumption and operation costs, aiding in optimization and ensuring the most efficient use of available resources. Managing regressions and model drift is crucial when deploying and monitoring machine learning models in operation, especially as new data comes in.
Communicating security insights efficiently across teams in your organization isn’t easy Security management is a complex and challenging task; effectively communicating security insights is even more so. Sample dashboard Next, you want to prepare an efficient plan for remediation.
The predefined set of files monitored for configuration alterations is maintained within ruxitagentproc.conf. Davis AI efficiently identified the deployment change as the potential root cause for the malfunctioning of nginx.
Part two added a few simple examples of how intellectual debt might accrue, highlighting the subtle but real drag on efficiency. Since we began the series pointing out parallels to technical debt, let’s revisit that comparison. The reasons we inadvertently accrue intellectual debt are similar to those that contribute to technical debt.
The impact of limited visibility in CI/CD pipelines The journey for Omnilogy started when a customer explained that they needed a way to monitor and improve the performance of their CI/CD pipelines with Dynatrace. Developers can automatically ensure enterprise security and governance requirement compliance by leveraging these components.
Broad-scale observability focused on using AI safely drives shorter release cycles, faster delivery, efficiency at scale, tighter collaboration, and higher service levels, resulting in seamless customer experiences. Automated release inventory and version comparison. is probably a developer’s “What version are you running?”
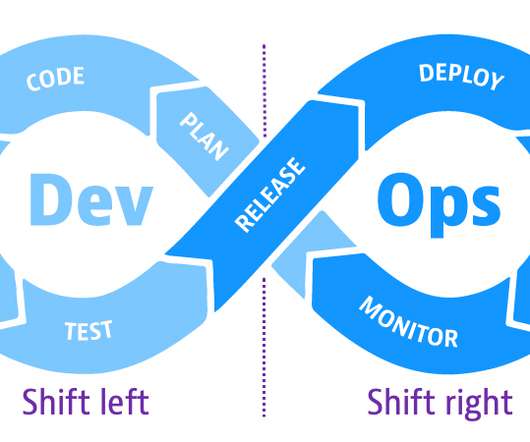
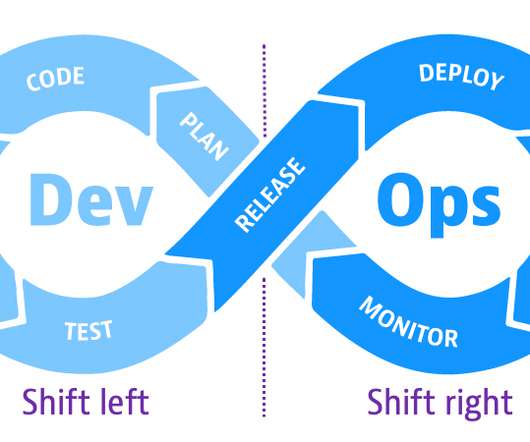
Shift-left speeds up development efficiency and reduces costs by detecting and addressing software defects earlier in the development cycle before they get to production. Organizations can also apply shift-right testing to code that gets configured or is monitored in the field. Synthetic monitoring.
Shift-left speeds up development efficiency and reduces costs by detecting and addressing software defects earlier in the development cycle before they get to production. Organizations can also apply shift-right testing to code that gets configured or is monitored in the field. Synthetic monitoring.
These developments gradually highlight a system of relevant database building blocks with proven practical efficiency. In comparison with pure anti-entropy, this greatly improves consistency with a relatively small performance penalty. System Coordination. It can be considered as a kind of targeted anti-entropy.
In comparison, the AIOps approach discussed within this article, is built upon a radically different deterministic AI engine – at Dynatrace known as Davis – that yields precise, actionable results in real-time. Data sources typically include common infrastructure monitoring tools and second-generation APM solutions as well as other solutions.
Modern observability has evolved from simple metric telemetry monitoring to encompass a wide range of data, including logs, traces, events, alerts, and resource attributes. Unlike generic DIY query frontends, the Dynatrace Problems app is a tailor-made solution for efficiently supporting operations use cases.
Introducing Carbon Impact The Carbon Impact app from Dynatrace measures and reports the carbon footprint of all Dynatrace-monitored hosts across your entire hybrid and multicloud environment, in a single interface. You’ll need to shift from intent to action, from passive reporting to active reduction initiatives.
Conventional (not built for cloud) monitoring tools are not much help. To start, let’s look at the illustration below to see how these two operate in comparison: Also to note on traditional machine learning: by its very nature of operation it is slow and less agile.
Citrix is a sophisticated, efficient, and highly scalable application delivery platform that is itself comprised of anywhere from hundreds to thousands of servers. Synthetic monitoring: Citrix login availability and performance. OneAgent: Citrix StoreFront services discovered and monitored by Dynatrace. Dynatrace news.
By conducting routine tasks on machinery and infrastructure, organizations can avoid costly breakdowns and maintain operational efficiency. IIoT devices and sensors allow for real-time monitoring, giving maintenance teams the ability to track equipment health and schedule maintenance activities before issues arise.
Continuous improvement of services is the most efficient process for all teams that are looking to improve the performance of their applications by considering all layers of their architecture. Similarly, we must also monitor our IT systems so closely that we know when the smallest thing isn’t working as normal.
This shift makes it harder to monitor, observe, and analyze data across a distributed technology stack. . On average, IT, development, and security teams in the sector rely on nine different monitoring tools to maintain visibility into performance and availability.
Operational Efficiency: The majority of the changes require metadata configuration files and library code changes, usually taking days of testing and service release to adopt the updates. In comparison, the API interface for consumer services should be consistent and static regardless of the business requirement iteration. What’s Next?
On the other hand, when one is interested only in simple additive metrics like total page views or average price of conversion, it is obvious that raw data can be efficiently summarized, for example, on a daily basis or using simple in-stream counters. bits per unique value. Case Study. Case Study. Frequency Estimation: Count-Min Sketch.
As the amount of data grows, the need for efficient data compression becomes increasingly important to save storage space, reduce I/O overhead, and improve query performance. Snappy compression is designed to be fast and efficient regarding memory usage, making it a good fit for MongoDB workloads. provides higher compression rates.
OpsWorks allows you to manage the complete application lifecycle, including resource provisioning, configuration management, application deployment, software updates, monitoring, and access control. For a comparison of the different Application Management services visit this overview page. Automated â?? Operational Control â??
Real-world examples like Spotify’s multi-cloud strategy for cost reduction and performance, and Netflix’s hybrid cloud setup for efficient content streaming and creation, illustrate the practical applications of each model. Thus making it an ideal choice for businesses seeking a successful implementation of their multi-cloud strategy.
This feature is perfect for someone who is not as familiar or efficient in using MongoDB syntax. Their free plan offers limited features, including connection, shell management, monitoring, data manipulation, and support, and you can compare them here on their plan comparison page.
The queues component of our methodology comes from Performance Monitor counters, which provide a view of system performance from a resource standpoint.". Waits data is surfaced by many SQL Server performance monitoring solutions, and I've been an advocate of tuning using this methodology since the beginning.
By adding automated visual testing , we can eliminate those flaky tests , leveling up our testing pipelines providing that coverage (and more) by taking advantage of smart image comparisons using screenshots of our website or app. Image Comparisons. Uptime Monitoring. Leveraging The Different Types Of Testing.
Additionally, Percona Operator for PostgreSQL version 2 includes expanded options for customizing backup and restore operations, improved monitoring and alerting capabilities, and support for PostgreSQL 15. Below you will find a short FAQ about the new operator and a comparison to version 1.x.
While test metrics and metrics collected during real use do not lend themselves to direct comparison, measuring the relative change in metrics in pre-production builds can help us to anticipate regressions in production. For example, we are considering using these techniques to monitor the reliability of non-performance-based test suites?—?in
Improving the efficiency with which we can coordinate work across a collection of units (see the Universal Scalability Law ). An IDS/IPS monitors network flows and matches incoming packets (or more strictly, Protocol Data Units, PDUs) against a set of rules. Increasing the amount of work we can do on a single unit.
In this blog post, we will review key topics to consider for managing large datasets more efficiently in MySQL. Redundant indexes: It is known that accessing rows by fetching an index is more efficient than through a table scan in most cases. It can help us to save costs on storage and backup times.
In order to create change across our entire organization, we needed to get all the relevant employees, partners, and even customers up to speed about performance quickly and efficiently. Measuring And Monitoring. This required a lot of planning and forethought, and quite a bit of trial and error. Creating A Performance Culture.
to run Google Lighthouse audits via the command line, save the reports they generate in JSON format and then compare them so web performance can be monitored as the website grows and develops. This means reports are now much more efficiently organized and won’t override each other no matter how many reports are saved.
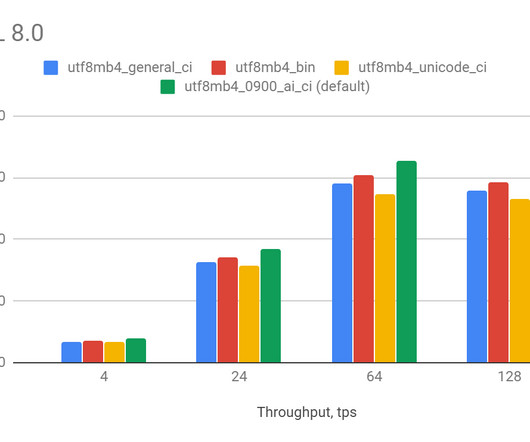
The choice of character set and encoding impacts not only efficiency but also how the data appears to users. Incompatibilities between character sets and collations can lead to unexpected sorting and comparison outcomes, which could lead to issues in database operations and application functionality. Watch the recorded webinar.
Oddly, about 3% of non-adopters cited cost as a primary reason not to move workloads to cloud; cost-efficiency is usually touted as one of cloud’s most attractive features. A comparison of respondent organization size and share of applications hosted in the cloud. We discovered obvious examples of correlation (i.e.,
Bloom filters present a space- and time-efficient alternative when a simple bitmap is infeasible due to space requirements. This is much less efficient than segment elimination or filtering during the columnstore scan, but it is still better than filtering at the hash join itself. LTGT for a less than/greater than comparison).
we also: Launched a series of new and improved dashboards to help you identify and fix your performance issues more quickly and efficiently (More on those below.). Hint: If you're considering installing a big-screen performance monitor at your organization, this dashboard is a good candidate for that.). Synthetic Site dashboard.
It’s “single-threaded,” which is how we get the one-way street comparison. Monitoring The Main Thread If you’re like me, I immediately reach for DevTools and open the Lighthouse tab when I need to look into a site’s performance. Credit: Brandon Nelson on Unsplash. JavaScript operates in much the same way.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content