This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Kafka scales efficiently for large data workloads, while RabbitMQ provides strong message durability and precise control over message delivery. Message brokers handle validation, routing, storage, and delivery, ensuring efficient and reliable communication. This allows Kafka clusters to handle high-throughput workloads efficiently.
Timestone: Netflix’s High-Throughput, Low-Latency Priority Queueing System with Built-in Support for Non-Parallelizable Workloads by Kostas Christidis Introduction Timestone is a high-throughput, low-latency priority queueing system we built in-house to support the needs of Cosmos , our media encoding platform. In comparison, we see 1.2K
Compare Latency. On average, ScaleGrid achieves almost 30% lower latency over DigitalOcean for the same deployment configurations. We are going to use a common, popular plan size using the below configurations for this performance benchmark: Comparison Overview. Read-Intensive Latency Benchmark. Compare Pricing.
Citrix is a sophisticated, efficient, and highly scalable application delivery platform that is itself comprised of anywhere from hundreds to thousands of servers. Dynatrace automation and AI-powered monitoring of your entire IT landscape help you to engage your Citrix management tools where they are most efficient. Citrix VDA.
In this scenario, it is also crucial to be efficient in resource utilization and scaling with frugality. Let us take a look also the latency: Here the situation starts to be a little bit more complicated. MySQL Router is the one that has the higher latency no matter what. That allows it to go a bit further. and ProxySQL 6.6k.
By collecting and analyzing key performance metrics of the service over time, we can assess the impact of the new changes and determine if they meet the availability, latency, and performance requirements. One can perform this comparison live on the request path or offline based on the latency requirements of the particular use case.
These developments gradually highlight a system of relevant database building blocks with proven practical efficiency. Historically, NoSQL paid a lot of attention to tradeoffs between consistency, fault-tolerance and performance to serve geographically distributed systems, low-latency or highly available applications. Data Placement.
Figure 1: A Simplified Video Processing Pipeline With this architecture, chunk encoding is very efficient and processed in distributed cloud computing instances. Uploading and downloading data always come with a penalty, namely latency. In order to do that, the storage cloud object is modeled as a number of fixed size parts.
Model observability provides visibility into resource consumption and operation costs, aiding in optimization and ensuring the most efficient use of available resources. To observe model drift and accuracy, companies can use holdout evaluation sets for comparison to model data.
Using a connection pool in each module is hardly efficient: Even with a relatively small number of modules, and a small pool size in each, you end up with a lot of server processes. The architecture of a generic connection-pool. However, modern web applications are rarely monolithic, and often use multiple languages and technologies.
Citrix is a sophisticated, efficient, and highly scalable application delivery platform that is itself comprised of anywhere from hundreds to thousands of servers. Dynatrace automation and AI-powered monitoring of your entire IT landscape help you to engage your Citrix management tools where they are most efficient. Dynatrace news.
In this comparison of Redis vs Memcached, we strip away the complexity, focusing on each in-memory data store’s performance, scalability, and unique features. Snapshots provide point-in-time captures of the dataset, which are efficient for recovery on startup.
The teams have been working closely on SVT-AV1 development, discussing architectural decisions, implementing new tools, and improving compression efficiency. The SVT-AV1 encoder supports all AV1 tools which contribute to compression efficiency.
The results will help database administrators and decision-makers choose the right platform for their performance, scalability, and cost-efficiency needs. Test Environment Setup Instance Types : We used similar cloud instances for AWS RDS and ScaleGrid to ensure a fair comparison. You can access the benchmark here: [link].
Perceptual quality measurements are used to drive video encoding optimizations , perform video codec comparisons , carry out A/B testing and optimize streaming QoE decisions to mention a few. This enables us to use our scale to increase throughput and reduce latencies. VQS is called using the measureQuality endpoint.
As the amount of data grows, the need for efficient data compression becomes increasingly important to save storage space, reduce I/O overhead, and improve query performance. Snappy compression is designed to be fast and efficient regarding memory usage, making it a good fit for MongoDB workloads. provides higher compression rates.
This separation aims to streamline transaction write logging, improving efficiency and consistency. DLVs are particularly advantageous for databases with large allocated storage, high I/O per second (IOPS) requirements, or latency-sensitive workloads. Who can benefit from DLV?
By conducting routine tasks on machinery and infrastructure, organizations can avoid costly breakdowns and maintain operational efficiency. As industries adopt these technologies, preventive maintenance is evolving to support smarter, data-driven decision-making, ultimately boosting efficiency, safety, and cost savings.
Edge servers are the middle ground – more compute power than a mobile device, but with latency of just a few ms. The client MWW combines these estimates with an estimate of the input/output transmission time (latency) to find the worker with the minimum overall execution latency. for the wasm-version.
This approach often leads to heavyweight high-latency analytical processes and poor applicability to realtime use cases. This approach can be very efficient because of the tiny memory footprint of the Loglog counter, even for millions of unique visitors. bits per unique value. Frequency Estimation: Count-Min Sketch.
Improving the efficiency with which we can coordinate work across a collection of units (see the Universal Scalability Law ). This makes the whole system latency sensitive. The baseline for comparison is Snort 3.0 , “the most powerful IPS in the world” according to the Snort website.
In-Memory Storage Engine, as the name suggests, stores data in memory for faster performance and lower latencies. Feature Comparison: MMAPV1 vs WiredTiger MMAPV1 provides document-level locking that allows for independent updates on different documents in a single collection. released in December 2015.
To do this, we have teams of experts that develop more efficient video and audio encodes , refine the adaptive streaming algorithm , and optimize content placement on the distributed servers that host the shows and movies that you watch. The goal is to bring you joy by delivering the content you love quickly and reliably every time you watch.
Technically, “performance” metrics are those relating to the responsiveness or latency of the app, including start up time. While test metrics and metrics collected during real use do not lend themselves to direct comparison, measuring the relative change in metrics in pre-production builds can help us to anticipate regressions in production.
To do this, we have teams of experts that develop more efficient video and audio encodes , refine the adaptive streaming algorithm , and optimize content placement on the distributed servers that host the shows and movies that you watch. The goal is to bring you joy by delivering the content you love quickly and reliably every time you watch.
This means reports are now much more efficiently organized and won’t override each other no matter how many reports are saved. In addition, Lighthouse also collects other metrics that aren’t listed in this part of the report but are still in an appropriate format to be included in the comparison. Comparing Lighthouse reports.
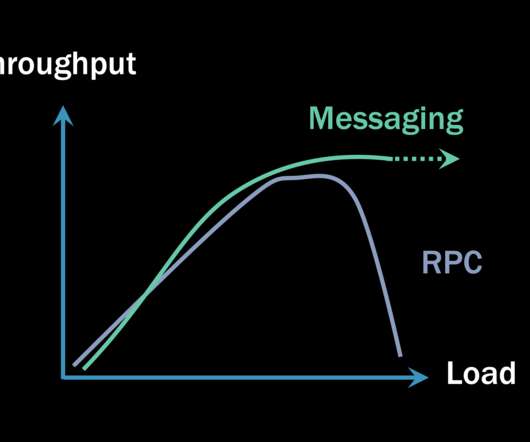
Some will claim that any type of RPC communication ends up being faster (meaning it has lower latency) than any equivalent invocation using asynchronous messaging. It’s less of an apples-to-oranges comparison and more like apples-to-orange-sherbet. There are more steps, so the increased latency is easily explained.
To do this, we have teams of experts that develop more efficient video and audio encodes , refine the adaptive streaming algorithm , and optimize content placement on the distributed servers that host the shows and movies that you watch. The goal is to bring you joy by delivering the content you love quickly and reliably every time you watch.
There are three generations of GPUs that are relevant to this comparison. The Hopper H100 was announced in 2022 and is the current volume product that people are using, so that is used as the baseline for comparison. The HGX H100 8-GPU system is the baseline for comparison, and its datasheet performance is shownbelow.
Here’s some predictions I’m making: Jack Dongarra’s efforts to highlight the low efficiency of the HPCG benchmark as an issue will influence the next generation of supercomputer architectures to optimize for sparse matrix computations. Jack Dongarra talked about the scores, and pointed out the low efficiency on some important workloads.
The resulting system can integrate seamlessly into a scikit-learn based development process, and dramatically reduces the total energy usage required for classification with very low latency. One efficient way of doing that in analog hardware is the use of current-starved inverters. Introducing race logic. Performance evaluation.
Individual samplers need to be built to be high throughput and memory efficient. The paper presents results on TCP-H (which looks a bit like a toy compared to the real production queries, but is useful for comparison), as well as from some production-like queries. Implementation. Of the other 14 all but one improve. What next?
Efficiently enables new styles of drawing content on the web , removing many hard tradeoffs between visual richness , accessibility, and performance. For heavily latency-sensitive use-cases like WebXR, this is a critical component in delivering a good experience. Form-associated Web Components. CSS Custom Paint. Trusted Types.
They need to deliver impeccable performance without breaking the bank.According to recent industry statistics, global streaming has seen an uptick of 30% in the past year, underscoring the importance of efficient CDN architecture strategies. This is where a well-architected Content Delivery Network (CDN) shines. Only overflow will await you.Â
They need to deliver impeccable performance without breaking the bank.According to recent industry statistics, global streaming has seen an uptick of 30% in the past year, underscoring the importance of efficient CDN architecture strategies. This is where a well-architected Content Delivery Network (CDN) shines.
Each of the two vector units can issue one FMA instruction per cycle, assuming that there are enough independent accumulators to tolerate the 6-cycle dependent-operation latency. Using the minimum number of accumulator registers needed to tolerate the pipeline latency (12), the assembly code for the inner loop is: B1.8: 8.056 0.056 75.0%
Each of the two vector units can issue one FMA instruction per cycle, assuming that there are enough independent accumulators to tolerate the 6-cycle dependent-operation latency. Using the minimum number of accumulator registers needed to tolerate the pipeline latency (12), the assembly code for the inner loop is: B1.8: 8.056 0.056 75.0%
You’ve probably heard things like: “HTTP/3 is much faster than HTTP/2 when there is packet loss”, or “HTTP/3 connections have less latency and take less time to set up”, and probably “HTTP/3 can send data more quickly and can send more resources in parallel”. HTTP/2 versus HTTP/3 protocol stack comparison ( Large preview ).
Test how user-friendly an application is: Google search engine gives high priority to websites in comparison to desktop apps. Testing helps in finding latency time of an application: Users prefer to use mobile phones over desktop when they are looking for any query, booking flight/movie ticket.
For example, the IMDG must be able to efficiently create millions of objects in each server to make use of its huge storage capacity. Likewise, object access paths must be heavily multi-threaded and avoid lock contention to minimize access latency and maximize throughput. Testing Scale-Up Performance.
. - **eBPF**: tracing features completed in 2016, this provides efficient programmatic tracing to existing kernel frameworks. Here's some output from my zfsdist tool, in bcc/BPF, which measures ZFS latency as a histogram on Linux: # zfsdist. Tracing ZFS operation latency. Hit Ctrl-C to end. ^C
iOS's security track record, patch velocity, and update latency for its required-use engine is not best-in-class. In addition to being self-defeating regarding engine choice, this fear also seems to ignore the best available comparison points. Apple's right to worry about engine security.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content