This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Second, it enables efficient and effective correlation and comparison of data between various sources. Receiving data from multiple sources, cleaning it up, and sending it to the desired backend systems reliably and efficiently is no small feat. OpenTelemetry Collector 1.0 Thats where the OpenTelemetry Collector can help.
Its a solid choice if you want a full-featured MySQL development environment. MySQL Workbench is a strong starting point if you want something official and comprehensive.
Kafka scales efficiently for large data workloads, while RabbitMQ provides strong message durability and precise control over message delivery. Message brokers handle validation, routing, storage, and delivery, ensuring efficient and reliable communication. This allows Kafka clusters to handle high-throughput workloads efficiently.
In this scenario, it is also crucial to be efficient in resource utilization and scaling with frugality. This is due to the multiplexing and the very efficient way ProxySQL uses to deal with high load. HAProxy always stays below 50% CPU, no matter the increasing number of threads/connections, scaling the load very efficiently.
Automation testing has numerous benefits in comparison to manual testing. It further removes chances of repetitive mistakes/tasks by testers, reduces human error, and provides instant feedback for quick resolution of issues, which improves overall efficiency in all activities.
The resulting vast increase in data volume highlights the need for more efficient data handling solutions. Moreover, by applying causal AI and topological mapping , a unified observability platform includes all the necessary data in context, making troubleshooting significantly more efficient and effective.
This begins not only in designing the algorithm or coming out with efficient and robust architecture but right onto the choice of programming language. There were languages I briefly read about, including other performance comparisons on the internet. These include Python, PHP, Perl, and Ruby.
Communicating security insights efficiently across teams in your organization isn’t easy Security management is a complex and challenging task; effectively communicating security insights is even more so. Sample dashboard Next, you want to prepare an efficient plan for remediation.
We can start by dialing traffic in a single data center to allow for an easier side-by-side comparison of key metrics across data centers, thereby making it easier to observe any deviations in the metrics. One can perform this comparison live on the request path or offline based on the latency requirements of the particular use case.
Part two added a few simple examples of how intellectual debt might accrue, highlighting the subtle but real drag on efficiency. Since we began the series pointing out parallels to technical debt, let’s revisit that comparison. Ready for more? Dynatrace Autonomous Cloud Enablement.
In fact, its enduring relevance is a testament to its robustness and efficiency. This blog dives into the intricate world of batch processing for data integration, elucidating its mechanics, advantages, considerations, and standing in comparison to other methodologies.
Performance efficiency. In comparison, the Dynatrace platform reliably takes that burden off human operators by utilizing its causation-based AI engine, Davis. Performance Efficiency. Design efficient use of your computing resources as demand changes and technologies evolves. Operational excellence. Reliability.
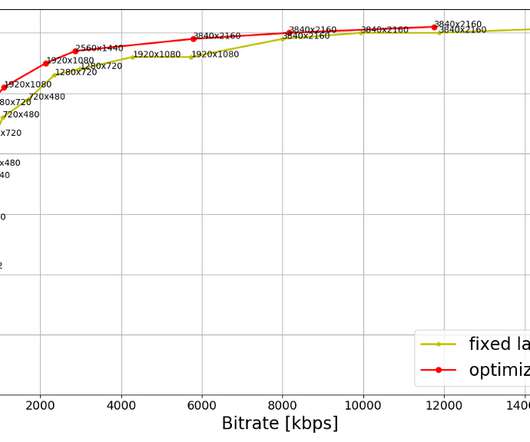
Bitrate versus quality comparison For a sample of titles from the 4K collection, the following plots show the rate-quality comparison of the fixed-bitrate ladder and the optimized ladder. Mbps, is for a 4K animation title episode which can be very efficiently encoded. The 8-bit stream profiles go up to 1080p resolution.
Davis AI efficiently identified the deployment change as the potential root cause for the malfunctioning of nginx. The framework outlined above provides a comprehensive view of the deployment process and facilitates comparisons across different releases.
In some instances, libdivide can even be more efficient than compilers because it uses an approach introduced by Robison (2005) where we not only use multiplications and shifts, but also an addition to avoid arithmetic overflows. What if d is a constant, but not known to the compiler? Then you can use a library like libdivide.
We are going to use a common, popular plan size using the below configurations for this performance benchmark: Comparison Overview. In this benchmark, we measure MySQL throughput in terms of queries per second (QPS) to measure our query efficiency. DigitalOcean. Instance Type. Medium: 4 vCPUs. Medium: 4 vCPUs. MySQL Version.
Broad-scale observability focused on using AI safely drives shorter release cycles, faster delivery, efficiency at scale, tighter collaboration, and higher service levels, resulting in seamless customer experiences. Automated release inventory and version comparison. is probably a developer’s “What version are you running?”
Unlike generic DIY query frontends, the Dynatrace Problems app is a tailor-made solution for efficiently supporting operations use cases. The native multi-select feature lets users open a filtered group of problems simultaneously, facilitating quick comparisons and detailed analysis.
Here’s a quick graphical comparison of the Pivotal Dev-to-Ops ratio, that of the Dynatrace elite category, and the average ratio identified by the survey. As an industry best practice, we like to refer to Pivotal, the developers of Cloud Foundry. Where do you want to spend your time and money?
Overview page of the Pipeline Observability app Thanks to the open and composable platform architecture and the provided toolset, building a custom app that runs natively within Dynatrace was straightforward and efficient. Same DQL semantics across all CI/CD vendors’ data.
These developments gradually highlight a system of relevant database building blocks with proven practical efficiency. In comparison with pure anti-entropy, this greatly improves consistency with a relatively small performance penalty. System Coordination. It can be considered as a kind of targeted anti-entropy.
After all, the primary purpose of computers is to execute tasks efficiently and swiftly. When you consider the fundamentals of computing, it seems almost magical — at its core, it involves simple arithmetic and logical operations, such as addition and comparison of binary numbers. I enjoy improving application performance.
Citrix is a sophisticated, efficient, and highly scalable application delivery platform that is itself comprised of anywhere from hundreds to thousands of servers. Dynatrace automation and AI-powered monitoring of your entire IT landscape help you to engage your Citrix management tools where they are most efficient.
Model observability provides visibility into resource consumption and operation costs, aiding in optimization and ensuring the most efficient use of available resources. To observe model drift and accuracy, companies can use holdout evaluation sets for comparison to model data.
Before settling down to choose one, you have to understand every comparison between the frameworks to ensure that the mobile app developed will have the best quality, efficiency, and fast performance at an affordable or reasonable investment cost.
This makes it possible for SVT-AV1 to decrease encoding time while still maintaining compression efficiency. Since that time, Intel’s and Netflix’s teams closely collaborated on SVT-AV1 development, discussing architectural decisions, implementing new tools, and improving the compression efficiency.
To start, let’s look at the illustration below to see how these two operate in comparison: Also to note on traditional machine learning: by its very nature of operation it is slow and less agile. It needs to collect a substantial amount of data at the beginning to build a training dataset that an algorithm can begin to learn from.
In this comparison of Redis vs Memcached, we strip away the complexity, focusing on each in-memory data store’s performance, scalability, and unique features. Snapshots provide point-in-time captures of the dataset, which are efficient for recovery on startup.
Figure 1: A Simplified Video Processing Pipeline With this architecture, chunk encoding is very efficient and processed in distributed cloud computing instances. Since not all projects are terabytes projects, allocating the largest cloud storage to all packager instances is not an efficient use of cloud resources.
The results will help database administrators and decision-makers choose the right platform for their performance, scalability, and cost-efficiency needs. Test Environment Setup Instance Types : We used similar cloud instances for AWS RDS and ScaleGrid to ensure a fair comparison. You can access the benchmark here: [link].
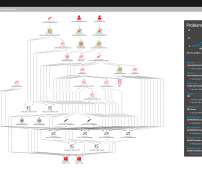
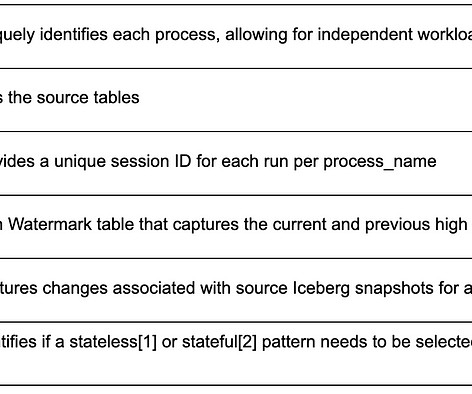
This helps in pinpointing changes and applying blocking audits efficiently. Audits like source-to-target count comparison and checking for no missing events in the target Iceberg snapshot ensure data integrity and completeness. Leveraging Psyberg metadata, we can identify the cohort of data involved as part of the job run.
Using a connection pool in each module is hardly efficient: Even with a relatively small number of modules, and a small pool size in each, you end up with a lot of server processes. The architecture of a generic connection-pool. However, modern web applications are rarely monolithic, and often use multiple languages and technologies.
In this article I provide a short comparison of NoSQL system families from the data modeling point of view and digest several common modeling techniques. Nevertheless, entry modification is generally less efficient than entry insertion in the majority of implementations. 10) Inverted Search – Direct Aggregation.
We have been leveraging machine learning (ML) models to personalize artwork and to help our creatives create promotional content efficiently. For instance, matching across a series with 10 episodes with an average of 2K shots per episode translates into 200M comparisons.
The teams have been working closely on SVT-AV1 development, discussing architectural decisions, implementing new tools, and improving compression efficiency. The SVT-AV1 encoder supports all AV1 tools which contribute to compression efficiency.
In comparison, the AIOps approach discussed within this article, is built upon a radically different deterministic AI engine – at Dynatrace known as Davis – that yields precise, actionable results in real-time. These approaches are slow and inaccurate limiting its practical applications. Lost and rebuilt context.
Bitrate versus quality comparison HDR-VMAF is designed to be format-agnostic — it measures the perceptual quality of HDR video signal regardless of its container format, for example, Dolby Vision or HDR10. This is achieved by more efficiently spacing the ladder points, especially in the high-bitrate region. The graphic below (Fig.
JSONB supports indexing the JSON data, and is very efficient at parsing and querying the JSON data. Essentially, this can only be used for whole object comparisons, which has a very limited use case. JSONB stands for “JSON Binary” or “JSON better” depending on whom you ask.
It presents a wide array of powerful management features that allow users to fine-tune their MongoDB hosting according to their exact requirements, facilitating an efficient and strategically aligned navigational experience. By adopting proactive management and future-readiness, your databases can remain secure and efficient.
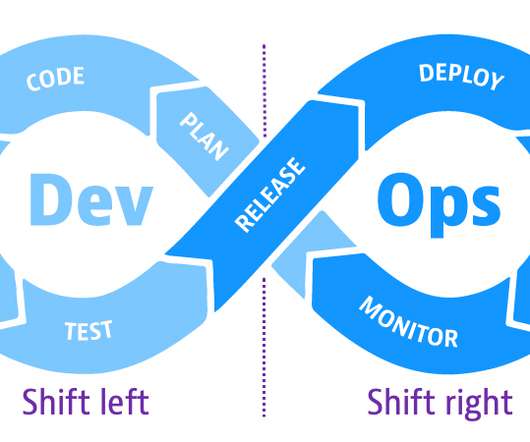
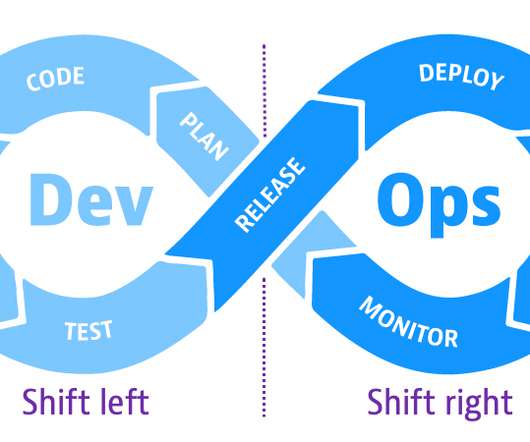
Shift-left speeds up development efficiency and reduces costs by detecting and addressing software defects earlier in the development cycle before they get to production. This concept has become increasingly important as teams face pressure to deliver software faster and more frequently with higher quality.
Shift-left speeds up development efficiency and reduces costs by detecting and addressing software defects earlier in the development cycle before they get to production. This concept has become increasingly important as teams face pressure to deliver software faster and more frequently with higher quality. Watch webinar.
Once inside the function, there's nothing wrong with multi-threading to do the work as efficiently as possible. Matthew Dillon : This is *very* impressive efficiency. This is *very* impressive efficiency. @sapessi : Lambda simplifies concurrency at the frontend, enforcing one event per function at a time.
By conducting routine tasks on machinery and infrastructure, organizations can avoid costly breakdowns and maintain operational efficiency. As industries adopt these technologies, preventive maintenance is evolving to support smarter, data-driven decision-making, ultimately boosting efficiency, safety, and cost savings.
Continuous improvement of services is the most efficient process for all teams that are looking to improve the performance of their applications by considering all layers of their architecture. Similar to an athlete, the objective here is to have teams always push the limits to become faster and stronger.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content