This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. Its design prioritizes high availability and efficient data transfer with minimal overhead, making it a practical choice for handling real-time data pipelines and distributed event processing.
ScaleGrid MySQL on Azure so you can see which provider offers the best throughput and latency performance. We measure latency in ms 95th percentile latency. During Read-Intensive Workloads, ScaleGrid manages to achieve up to 3 times higher throughput and averages 66% better latency compared to Azure Database.
Timestone: Netflix’s High-Throughput, Low-Latency Priority Queueing System with Built-in Support for Non-Parallelizable Workloads by Kostas Christidis Introduction Timestone is a high-throughput, low-latency priority queueing system we built in-house to support the needs of Cosmos , our media encoding platform. In comparison, we see 1.2K
We have run these benchmarks on the AWS EC2 instances and designed a custom dataset to make it as close as possible to real application use cases. We compare throughput, operations per second, and latency under different loads, namely the P90 and P99 percentiles.
Plotted on the same horizontal axis of 1.6s, the waterfalls speak for themselves: 201ms of cumulative latency; 109ms of cumulative download. 4,362ms of cumulative latency; 240ms of cumulative download. When we talk about downloading files, we—generally speaking—have two things to consider: latency and bandwidth. It gets worse.
When designing an architecture, many components need to be considered before deciding on the best solution. Let us take a look also the latency: Here the situation starts to be a little bit more complicated. MySQL Router is the one that has the higher latency no matter what. That allows it to go a bit further. and ProxySQL 6.6k.
By collecting and analyzing key performance metrics of the service over time, we can assess the impact of the new changes and determine if they meet the availability, latency, and performance requirements. One can perform this comparison live on the request path or offline based on the latency requirements of the particular use case.
Uploading and downloading data always come with a penalty, namely latency. Figure 2: Cloud Resource and Job Sizes This initial architecture was designed at a time when packaging from a list of chunks was not possible and terabyte-sized files were not considered. thus making this design viable. at most few parts at a time?—?thus
For production models, this provides observability of service-level agreement (SLA) performance metrics, such as token consumption, latency, availability, response time, and error count. To observe model drift and accuracy, companies can use holdout evaluation sets for comparison to model data.
Historically, NoSQL paid a lot of attention to tradeoffs between consistency, fault-tolerance and performance to serve geographically distributed systems, low-latency or highly available applications. Read/Write latency. Read/Write requests are processes with a minimal latency. Data Placement. Read/Write scalability.
Although this response has a 0B filesize, we will always take the latency hit on every single page view (and this response is basically 100% latency). com , which introduces yet more latency for the connection setup. If you’re interested in seeing a real-world example of this, consider the following filmstrip comparison.
Perceptual quality measurements are used to drive video encoding optimizations , perform video codec comparisons , carry out A/B testing and optimize streaming QoE decisions to mention a few. For example, when we design a new version of VMAF, we need to effectively roll it out throughout the entire Netflix catalog of movies and TV shows.
This freshness measurement can then be used by out-of-the-box Dynatrace anomaly detection to actively alert on abnormal changes within the data ingest latency to ensure the expected freshness of all the data records. Solution : Like the freshness example, Dynatrace can monitor the record count over time.
In this comparison of Redis vs Memcached, we strip away the complexity, focusing on each in-memory data store’s performance, scalability, and unique features. Redis Data Types and Structures The design of Redis’s data structures emphasizes versatility. Memcached’s primary strength lies in its simplicity.
Snappy compression is designed to be fast and efficient regarding memory usage, making it a good fit for MongoDB workloads. s Time taken to import 120000000 document: 7412 seconds We can see from the above comparison that we can save almost 3GB of disk space without impacting the CPU or memory. provides higher compression rates.
Audience This article is designed for database administrators (DBAs), DevOps teams, system architects, CTOs, and any stakeholders responsible for selecting and optimizing database solutions in cloud environments. Test Environment Setup Instance Types : We used similar cloud instances for AWS RDS and ScaleGrid to ensure a fair comparison.
With more nodes and more coordination comes more complexity, both in design and operation. This makes the whole system latency sensitive. One of the joys of this paper is that you don’t just get to see the final design, you also get insight into the forces and trade-offs that led to it.
The chief effect of the architectural difference is to shift the distribution of latency within the loop. Herein lies the source of our collective anxiety about front-end architectures: traversing networks is always fraught, but the costs to deliver client-side logic to cushion users from variable network latency remain stubbornly high.
Edge servers are the middle ground – more compute power than a mobile device, but with latency of just a few ms. The client MWW combines these estimates with an estimate of the input/output transmission time (latency) to find the worker with the minimum overall execution latency. for the wasm-version.
Compared to the most recent master version of libaom (AV1 reference software), SVT-AV1 is similar in compression efficiency and at the same time achieves significantly lower encoding latency on multi-core platforms when using its inherent parallelization capabilities.
Quick summary : Node vs React Comparison is not correct because both technologies are entirely different things. Node JS vs. React JS Comparison. The technology develops single-page applications , websites, and backend API services designed with real-time and push-based architectures. Node JS vs. React JS Comparison.
This approach often leads to heavyweight high-latency analytical processes and poor applicability to realtime use cases. This process is illustrated in the following code snippet: class LinearCounter { BitSet mask = new BitSet(m) // m is a design parameter void add(value) { int position = hash(value) // map the value to the range 0.m
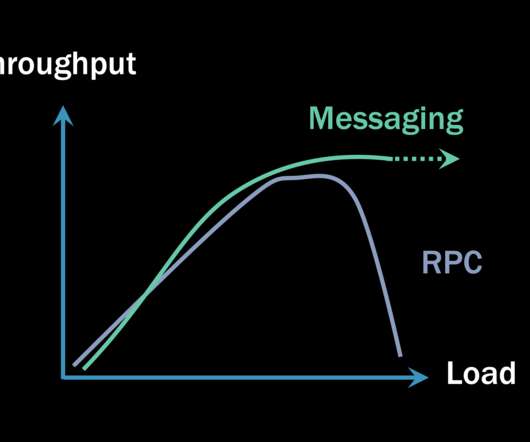
Some will claim that any type of RPC communication ends up being faster (meaning it has lower latency) than any equivalent invocation using asynchronous messaging. It’s less of an apples-to-oranges comparison and more like apples-to-orange-sherbet. There are more steps, so the increased latency is easily explained.
Technically, “performance” metrics are those relating to the responsiveness or latency of the app, including start up time. There are roughly 50 performance tests, each one designed to reproduce an aspect of member engagement. and often before they are even committed to the codebase. What do we mean by Performance?
A Dedicated Log Volume (DLV) is a specialized storage volume designed to house database transaction logs separately from the volume containing the database tables. DLVs are particularly advantageous for databases with large allocated storage, high I/O per second (IOPS) requirements, or latency-sensitive workloads.
You could play with it until you felt like building something else and turning the current models into interior design pieces. Here’s a quick comparison: Preventive maintenance: Planned in advance, cost-effective, reduces downtime, and improves reliability. The beauty of Legos was (is) the “one and done” aspect of it.
This is a complex topic, but to borrow from a recent post , web performance expands access to information and services by reducing latency and variance across interactions in a session, with a particular focus on the tail of the distribution (P75+). Consistent performance matters just as much as low average latency.
The design space. We group the DBMS design choices and tradeoffs into three broad categories, which result from the need for dealing with (A) external storage; (B) query executors that are spun on demand; and (C) DBMS-as-a-service offerings. Key findings. Query restrictions.
In comparison, for Linpack Frontier operates at 68% of peak capacity. During the Reinventing HPC panel session, there was some discussion of the cost of designing custom processors for HPC, and a statement that it was too high, in the hundreds of millions of dollars.
Due to the design of web browser APIs, there are currently no mechanisms for querying requests and their relative responses after the fact. We can also lean into what we’ve learned with Server-Timing to set a timestamp on the header for comparison. No References Required. This is important because of the need to manage memory.
Certain tools are designed for certain metrics with certain assumptions that produce certain results. In contrast, tools like DebugBear and WebPageTest use more realistic throttling that accurately reflects network round trips on a higher-latency connection. Lighthouse results. Real usage data would be better, of course.
Apple's policy against browser engine choice adds years of delays beyond the (expected) delay of design iteration, specification authoring, and browser feature development. For heavily latency-sensitive use-cases like WebXR, this is a critical component in delivering a good experience. Offscreen Canvas.
You’ve probably heard things like: “HTTP/3 is much faster than HTTP/2 when there is packet loss”, or “HTTP/3 connections have less latency and take less time to set up”, and probably “HTTP/3 can send data more quickly and can send more resources in parallel”. HTTP/2 versus HTTP/3 protocol stack comparison ( Large preview ). Conclusion.
(Byte-addressable non-volatile memory,) NVM will fundamentally change the way hardware interacts, the way operating systems are designed, and the way applications operate on data. Therefore any programming abstraction must be low latency and the kernel needs to be kept off the path of persistent data access as much as possible.
The resulting system can integrate seamlessly into a scikit-learn based development process, and dramatically reduces the total energy usage required for classification with very low latency. The evaluation is performed using the MNIST dataset, since that has the most results available in the literature for comparison.
This can lead to a ‘camel-is -a-horse designed-by-committee’ situation, where the resulting API is more a reflection of battling political wills than technical common sense. And while the APIs define contracts for what gets passed back and forth, we generally don’t discuss expected latency or availability. API Challenge #5.
The applications are designed using the same code base as Desktop like HTML, Javascript, and CSS. Unlike Native Applications, Mobile web applications do not have to be designed separately for IOS and Android. Test how user-friendly an application is: Google search engine gives high priority to websites in comparison to desktop apps.
Likewise, object access paths must be heavily multi-threaded and avoid lock contention to minimize access latency and maximize throughput. A Few Words on Design Philosophy: Keep It Simple. Use Fully Peer-to-Peer Design for Simplicity and High Availability. Testing Scale-Up Performance. Distributed Cache or In-Memory Data Grid?
The benefits to apps that adopt WebView-based IABs are numerous: WebViews are system components designed for use within other apps. CCT's core design is sound and has enormous potential if made mandatory in place of WebView IABs by the Android and Play teams. There's reason to worry that this is unlikely.
This type of traffic originates directly from the server, making it more challenging to handle due to latency and server load considerations; it’s hard but not impossible. Statistics reveal that a 1% improvement in latency can lead to a 3% increase in viewer engagement, highlighting its significance in live content delivery.3.
This type of traffic originates directly from the server, making it more challenging to handle due to latency and server load considerations; it’s hard but not impossible. This is mainly because video files are notably bulkier than a simple text-based API request, which, in comparison, would be more like a droplet than an entire river.
Each of the two vector units can issue one FMA instruction per cycle, assuming that there are enough independent accumulators to tolerate the 6-cycle dependent-operation latency. Using the minimum number of accumulator registers needed to tolerate the pipeline latency (12), the assembly code for the inner loop is: B1.8: 8.056 0.056 75.0%
Each of the two vector units can issue one FMA instruction per cycle, assuming that there are enough independent accumulators to tolerate the 6-cycle dependent-operation latency. Using the minimum number of accumulator registers needed to tolerate the pipeline latency (12), the assembly code for the inner loop is: B1.8: 8.056 0.056 75.0%
HammerDB has always used stored procedures as a design decision because the original benchmark was implemented as close as possible to the example workload in the TPC-C specification that uses stored procedures. HammerDB uses stored procedures to achieve maximum throughput when benchmarking your database. On MySQL, we saw a 1.5X
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content