This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In softwareengineering, we've learned that building robust and stable applications has a direct correlation with overall organization performance. The data community is striving to incorporate the core concepts of engineering rigor found in software communities but still has further to go. Posted with permission.
It's easy to write "unit test" tests that use JUnit and some mocking library. They may produce code coverage that keeps some stakeholders happy, even though the tests aren't even unit tests and provide questionable value. It is like the test has a negative value.
For softwareengineering teams, this demand means not only delivering new features faster but ensuring quality, performance, and scalability too. One way to apply improvements is transforming the way application performance engineering and testing is done. Check out Dynatrace’s Load testing tool integration.
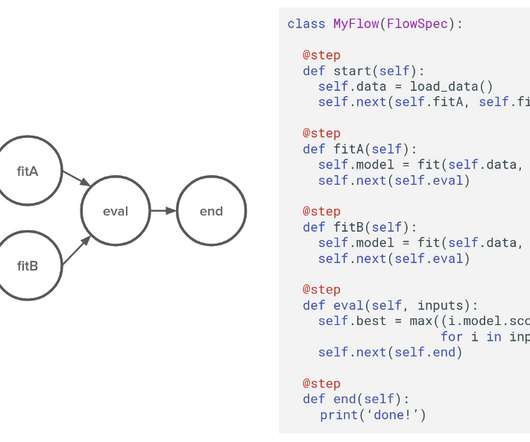
Instead of having LLMs make runtime decisions about business logic, use them to help create robust, reusable workflows that can be tested, versioned, and maintained like traditional software. By predefined, tested workflows, we mean creating workflows during the design phase, using AI to assist with ideas and patterns.
SRE is the transformation of traditional operations practices by using softwareengineering and DevOps principles to improve the availability, performance, and scalability of releases by building resiliency into apps and infrastructure. Encouraging a shift-left approach , testing earlier in the development lifecycle.
Platform engineering is a practice that outlines how development teams build internal platforms to create self-service capabilities for softwareengineering teams. The result is a cloud-native approach to software delivery.
Introduction to Flaky Tests. Unit testing forms the bedrock of any Continuous Integration (CI) system. It warns softwareengineers of bugs in newly-implemented code and regressions in existing code, before it is merged. This ensures increased software reliability.
Application security is a softwareengineering term that refers to several different types of security practices designed to ensure applications do not contain vulnerabilities that could allow illicit access to sensitive data, unauthorized code modification, or resource hijacking. Application security tests and what they do.
As a result, teams can focus on writing code and building features rather than dealing with infrastructure nuances. They shouldn’t worry about the platform; they should just start writing code.” Test continuously Synthetic testing simulates user behaviors within an application or service to pinpoint potential problems.
Free Trial: Does the paid product offer a free trial so users can test before committing? The ability to generate synthetic data for system testing. An intelligent query editor with code refactoring, autocomplete, error detection, optimization, and analysis tools sensitive to context and aware of schema. Non-Commercial: $9.99/month
What is site reliability engineering? Site reliability engineering (SRE) is the practice of applying softwareengineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Dynatrace news.
When it comes to site reliability engineering (SRE) initiatives adopting DevOps practices, developers and operations teams frequently find themselves at odds with one another. Developers want to write high-quality code and deploy it quickly. Operations teams want to make sure the system doesn’t break.
Build an umbrella for Development and Operations In modern softwareengineering, the discipline of platform engineering delivers DevSecOps practices to developers to bridge the gaps between development, security, and operations and enhance the developer experience.
As a SoftwareEngineer, the mind is trained to seek optimizations in every aspect of development and ooze out every bit of available CPU Resource to deliver a performing application. Though I have spent the last ~17 years (In 2021) of my life coding and perfecting my Java and J2EE skill — I suddenly feel. Ahem, Slow!
In a recent webinar , Dynatrace DevOps activist Andi Grabner and senior softwareengineer Yarden Laifenfeld explored developer observability. But developers need code-level visibility and code-level data.” That’s not how I envision code-level observability,” Laifenfeld said. KubeCon North America is this week.
Although IT teams are thorough in checking their code for any errors, an attacker can always discover a loophole to exploit and damage applications, infrastructure, and critical data. If a malicious attacker can identify a key software vulnerability, they can exploit the vulnerability, allowing them to gain access to your systems.
Site reliability engineering (SRE) is the practice of applying softwareengineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Shift-left using an SRE approach means that reliability is baked into each process, app and code change.
There are a few qualities that differentiate average from high performing softwareengineering organisations. I believe that attitude towards the design of code and architecture is one of them. Equally, code that accurately describes the domain it is modelling is often far easier to understand and change.
Observability-driven development Yarden Laifenfeld, senior softwareengineer at Dynatrace, presented the first use case for the software development lifecycle (SDLC): observability-driven development, which is the process of integrating observability and security before the first line of code is even written.
We sat together with Armin Ruech and Daniel Dyla, softwareengineers at Dynatrace and leaders within the OpenTelemetry community, to hear about their involvement with the second most active CNCF project. My name is Armin Ruech, I’m a SoftwareEngineer at Dynatrace and I started as a software developer around 3.5
And the last sentence of the email was what made me want to share this story publicly, as it’s a testimonial to how modern softwareengineering and operations should make you feel. Those tests get executed from two locations (Paris and London) hosted by different cloud vendors (Azure & AWS).
mainly because of mundane reasons related to softwareengineering. A key observation was that most of our data scientists had nothing against writing Python code. Data scientists want to retain their freedom to use arbitrary, idiomatic Python code to express their business logic?—?like
According to recent Dynatrace research , organizations expect to make software updates 58% more frequently in the coming year. This drive for speed has a cost: 22% of leaders admit they’re under so much pressure to innovate faster that they must sacrifice code quality. What is DevOps?
Here we describe the role of Experimentation and A/B testing within the larger Data Science and Engineering organization at Netflix, including how our platform investments support running tests at scale while enabling innovation. What more can we learn from this test, to inform the next one?”
Groups beyond softwareengineering teams are standing up their own systems and automation. The best way to get started is to read through the documentation and code, install ConsoleMe, and take a look at our open issues to see what work needs to be done, or submit issues yourself. If you missed the talk, check it out here.
This is both frustrating for companies that would prefer making ML an ordinary, fuss-free value-generating function like softwareengineering, as well as exciting for vendors who see the opportunity to create buzz around a new category of enterprise software. The new category is often called MLOps. This approach is not novel.
It allows data scientists to define ML workflows, test them locally, scale-out to the cloud, and deploy to production in idiomatic Python code. It makes it easy for data scientists to express even complex machine learning applications in idiomatic Python, test them locally, or scale them out in the cloud?—?all
Our very first mobile app is called Prodicle and was built for Android & iOS using the same reactive architecture in both platforms, which allowed us to build 2 apps from scratch in 3 months with 4 softwareengineers. It was extremely important to the team that we did not completely change the way our engineers write Android code.
According to a survey conducted on softwaretest automation , 51% of organisations prefer to retrain existing staff in test automation skills. While there are still 49% that would like to hire them specially for test automation related tasks. And, 14% said they’d like to have no manual testing at all.”
Commit Cycle Time refers to the average time for a code or configuration change until it’s deployed into production and accessible to users. Improving your team’s Commit Cycle Time means relying on efficient testing and soliciting feedback as quickly as possible. Break down software into smaller chunks. Get rid of dependencies.
Weve seen this across dozens of companies, and the teams that break out of this trap all adopt some version of Evaluation-Driven Development (EDD), where testing, monitoring, and evaluation drive every decision from the start. Were also betting that this will be a time of software development flourishing. The way out?
Site reliability engineering (SRE) continues to gain popularity as organizations embrace hybrid cloud strategies and IT automation at scale. By applying softwareengineering principles to operations and infrastructure practices, SRE enables organizations to streamline and automate IT processes. Dynatrace news.
We make sure there is no training/serving skew by using the same data and the code for online and offline feature generation. Corruption in data can significantly impact production model performance and A/B test results. Another learning is that we should have invested early into a robust testing framework.
Now that you’ve deployed your code, it’s time to monitor it, collect data, and analyze your metrics. You’ve just released your new app into the wild, live in production. Your job is done, right? Without application performance monitoring in place, you can’t accurately determine how well things are going. Are people using your app?
On one hand, ops groups are in a good position to do this; they’re already heavily invested in testing, monitoring, version control, reproducibility, and automation. First, the behavior of an AI application depends on a model , which is built from source code and training data. This has important implications for testing.
mainly because of mundane reasons related to softwareengineering. A key observation was that most of our data scientists had nothing against writing Python code. Data scientists want to retain their freedom to use arbitrary, idiomatic Python code to express their business logic?—?like
The beginning of my experience as a Junior SoftwareEngineer on one of Tasktop’s ‘Integrations Teams’ marked a definitive transition in the way I learned and practiced computer science and software development. SoftwareEngineers, was introduced to the fundamental concepts and tools on which Tasktop is built.
T riplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Learn how engineering teams are using products like StackHawk and Snyk to add security bug testing to their CI pipelines. Try out their platform. Apply here.
Introduction to Flaky Tests. Unit testing forms the bedrock of any Continuous Integration (CI) system. It warns softwareengineers of bugs in newly-implemented code and regressions in existing code, before it is merged. This ensures increased software reliability.
Interview with Samuel Setegne Samuel Setegne This post is part of our “Data Engineers of Netflix” interview series, where our very own data engineers talk about their journeys to Data Engineering @ Netflix. Samuel Setegne is a Senior SoftwareEngineer on the Core Data Science and Engineering team.
T riplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Learn how engineering teams are using products like StackHawk and Snyk to add security bug testing to their CI pipelines. Try out their platform. Apply here.
T riplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Learn how engineering teams are using products like StackHawk and Snyk to add security bug testing to their CI pipelines. Try out their platform. Apply here.
T riplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Learn how engineering teams are using products like StackHawk and Snyk to add security bug testing to their CI pipelines. Try out their platform. Apply here.
T riplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. By leveraging automation and delivering security-as-code, Bridgecrew empowers teams to find, fix, and prevent misconfigurations in deployed cloud resources and in infrastructure as code.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content