This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
On the other hand, deploying new code on the backend is complex and offers no such transparency. With Dynatrace Live Debugger, you can set a non-breaking breakpoint and instantly see if new code is following the intended new paths, if any new arguments are being considered, and if input and output arguments are aligned with expectations.
Readable code is usable code. The world’s greatest chefs never put anything on the plate that will never be eaten, this rule corresponds to the YAGNI principle in SoftwareEngineering. Such non-used code blocks may affect code readability in the future.
In early September I had a very enjoyable technical chat with Steve Klabnik of Rust fame and interviewer Kevin Ball of SoftwareEngineering Daily, and the podcast is now available. Its long-standing presence and compatibility with legacy code make it a go-to language for maintaining and extending older projects.
The system is inconsistent, slow, hallucinatingand that amazing demo starts collecting digital dust. Traditional versus GenAI software: Excitement builds steadilyor crashes after the demo. Two big things: They bring the messiness of the real world into your system through unstructured data. Leadership gets excited. The way out?
Our industry is in the early days of an explosion in software using LLMs, as well as (separately, but relatedly) a revolution in how engineers write and run code, thanks to generative AI.
We are well aware of what is meant by system scalability. System scalability is about maintaining the SLA of the system as the user base continues to grow and as the user activity continues to rise. Softwareengineering team scalability is equally important. SoftwareEngineering Team Scalability.
Over the past decade, DevOps has emerged as a new tech culture and career that marries the rapid iteration desired by software development with the rock-solid stability of the infrastructure operations team. As of August 2019, there are currently over 50,000 LinkedIn DevOps job listings in the United States alone.
TL;DR: Enterprise AI teams are discovering that purely agentic approaches (dynamically chaining LLM calls) dont deliver the reliability needed for production systems. The prompt-and-pray modelwhere business logic lives entirely in promptscreates systems that are unreliable, inefficient, and impossible to maintain at scale.
For softwareengineering teams, this demand means not only delivering new features faster but ensuring quality, performance, and scalability too. One way to apply improvements is transforming the way application performance engineering and testing is done. Industry apps explosion. Here is a shortlist to get you started.
Due to its versatility for storing information in both structured and unstructured formats, PostgreSQL is the fourth most used standard in modern database management systems (DBMS) worldwide 1. Offering comprehensive access to files, software features, and the operating system in a more user-friendly manner to ensure control.
Softwareengineering for machine learning: a case study Amershi et al., More specifically, we’ll be looking at the results of an internal study with over 500 participants designed to figure out how product development and softwareengineering is changing at Microsoft with the rise of AI and ML. ICSE’19.
Malicious attackers have gotten increasingly better at identifying vulnerabilities and launching zero-day attacks to exploit these weak points in IT systems. A zero-day exploit is a technique an attacker uses to take advantage of an organization’s vulnerability and gain access to its systems.
Application observability helps IT teams gain visibility in their highly distributed systems, but what is developer observability and why is it important? In a recent webinar , Dynatrace DevOps activist Andi Grabner and senior softwareengineer Yarden Laifenfeld explored developer observability. Observability is about answering.”
Submit a proposal for a talk at our new virtual conference, Coding with AI: The End of Software Development as We Know It.Proposals must be submitted by March 5; the conference will take place April 24, 2025, from 11AM to 3PM EDT. AI writes buggy code? So do humansand AI seems to be getting better at writing correct code.
Platform engineering is on the rise. According to leading analyst firm Gartner, “80% of softwareengineering organizations will establish platform teams as internal providers of reusable services, components, and tools for application delivery…” by 2026. Monitoring-as-code can also be configured in GitOps fashion.
What is site reliability engineering? Site reliability engineering (SRE) is the practice of applying softwareengineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable softwaresystems. SRE bridges the gap between Dev and Ops teams.
By helping teams release new software more frequently, DevOps practices are an essential component of digital transformation. Yet, ensuring code quality and breaking down silos are some of the many challenges that come with DevOps methodologies. Manually managing and securing multi-cloud environments is no longer practical.
Software development is not an established discipline where there is a clear technique used to solve any given problem. In fact, there are near infinite ways to solve every softwareengineering challenging. However, as softwaresystems age, the time it takes to add new features grows exponentially?—?and
There are a few qualities that differentiate average from high performing softwareengineering organisations. I believe that attitude towards the design of code and architecture is one of them. Martin Fowler argues that internal quality of a softwaresystem enables new features and improvements to be delivered more sustainably.
As a SoftwareEngineer, the mind is trained to seek optimizations in every aspect of development and ooze out every bit of available CPU Resource to deliver a performing application. They still will win for mission-critical or real-time systems, which need performance over these parameters. Ahem, Slow!
Site reliability engineering (SRE) is the practice of applying softwareengineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable softwaresystems. This can be anything from adjusting monitoring and alerting to making code changes in production.
When it comes to site reliability engineering (SRE) initiatives adopting DevOps practices, developers and operations teams frequently find themselves at odds with one another. Developers want to write high-quality code and deploy it quickly. Operations teams want to make sure the system doesn’t break.
Visibility into system activity and behavior has become increasingly critical given organizations’ widespread use of Amazon Web Services (AWS) and other serverless platforms. Lambda is Amazon’s event-driven, functions-as-a-service (FaaS) compute service that runs code when triggered for application and back-end services.
By Karen Casella, Director of Engineering, Access & Identity Management Have you ever experienced one of the following scenarios while looking for your next role? You study and practice coding interview problems for hours/days/weeks/months, only to be asked to merge two sorted lists. This is a conversation, not an inquisition!
Application security is a softwareengineering term that refers to several different types of security practices designed to ensure applications do not contain vulnerabilities that could allow illicit access to sensitive data, unauthorized code modification, or resource hijacking. Dynatrace news.
We sat together with Armin Ruech and Daniel Dyla, softwareengineers at Dynatrace and leaders within the OpenTelemetry community, to hear about their involvement with the second most active CNCF project. My name is Armin Ruech, I’m a SoftwareEngineer at Dynatrace and I started as a software developer around 3.5
This shift is leading more organizations to hire site reliability engineers to guarantee the reliability and resiliency of their services. How site reliability engineering affects organizations’ bottom line SRE applies the disciplines of softwareengineering to infrastructure management, both on-premises and in the cloud.
According to recent Dynatrace research , organizations expect to make software updates 58% more frequently in the coming year. This drive for speed has a cost: 22% of leaders admit they’re under so much pressure to innovate faster that they must sacrifice code quality. What is DevOps?
The fact is, Reliability and Resiliency must be rooted in the architecture of a distributed system. And the last sentence of the email was what made me want to share this story publicly, as it’s a testimonial to how modern softwareengineering and operations should make you feel.
Unit testing forms the bedrock of any Continuous Integration (CI) system. It warns softwareengineers of bugs in newly-implemented code and regressions in existing code, before it is merged. This ensures increased software reliability. Introduction to Flaky Tests.
The GUI can be extended with plugins, allowing the community to build integrations to other systems, custom visualizations, and embed upcoming features of Metaflow directly into its views. It allows data scientists to define ML workflows, test them locally, scale-out to the cloud, and deploy to production in idiomatic Python code.
This is both frustrating for companies that would prefer making ML an ordinary, fuss-free value-generating function like softwareengineering, as well as exciting for vendors who see the opportunity to create buzz around a new category of enterprise software. The new category is often called MLOps. This approach is not novel.
Site reliability engineering (SRE) is the practice of applying softwareengineering expertise to DevOps and operations problems. Service level objectives (SLOs) are the goals set for the availability expected out of a system.
Groups beyond softwareengineering teams are standing up their own systems and automation. Permission whack-a-mole At Netflix, we’re firm believers in empowering our employees and providing low-friction systems that allow users to get their jobs done in a safe way. If you missed the talk, check it out here. No problem.
Due to its popularity, the number of workflows managed by the system has grown exponentially. The scheduler on-call has to closely monitor the system during non-business hours. As the usage increased, we had to vertically scale the system to keep up and were approaching AWS instance type limits.
The whole system was quite complex, and starting to become brittle. The API server orchestrates backend systems to authenticate the user. Upstream systems had to reopen the tokens to identify the user logging in and potentially manage multiple parallel identity data structures, which could easily get out of sync.
Site reliability engineering (SRE) continues to gain popularity as organizations embrace hybrid cloud strategies and IT automation at scale. By applying softwareengineering principles to operations and infrastructure practices, SRE enables organizations to streamline and automate IT processes. Dynatrace news.
billion : venture investment first half of 2018; 1 billion : Utah voting system per day hack attempts; 67% : did not deploy a serverless app last year; $1.8 Leslie Lamport : Today, programming is generally equated with coding. Margaret Hamilton started the field of softwareengineering.
Triplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. We found that High Scalability readers are about 80% more likely to be in the top bracket of engineering skill. Who's Hiring? Make your job search O (1), not O ( n ). Apply here.
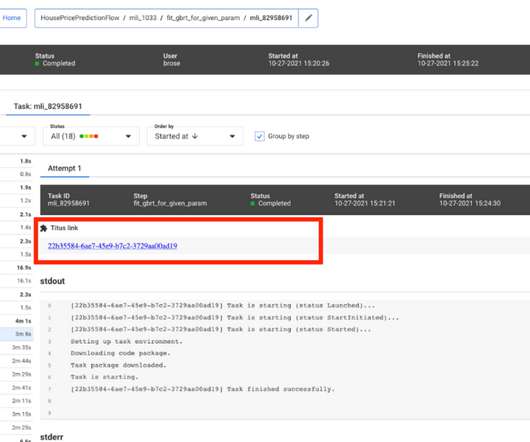
Migrating a privacy-safe information extraction system to a software 2.0 This is a comparatively short (7 pages) but very interesting paper detailing the migration of a softwaresystem to a ‘Software 2.0’ A really interesting thing happens when you go from developing a Software 1.0 (i.e.,
Triplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. We found that High Scalability readers are about 80% more likely to be in the top bracket of engineering skill. Who's Hiring? Make your job search O (1), not O ( n ). Apply here.
They were succeeded by programmers writing machine instructions as binary code to be input one bit at a time by flipping switches on the front of a computer. Then, development of even higher-level compiled languages like Fortran, COBOL, and their successors C, C++, and Java meant that most programmers no longer wrote assembly code.
Triplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. We found that High Scalability readers are about 80% more likely to be in the top bracket of engineering skill. Who's Hiring? Make your job search O (1), not O ( n ). Apply here.
Triplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. We found that High Scalability readers are about 80% more likely to be in the top bracket of engineering skill. Who's Hiring? Make your job search O (1), not O ( n ). Apply here.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content