This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Applications and services are often slowed down by under-performing DNS communications or misconfigured DNS servers, which can result in frustrated customers uninstalling your application. Ensure high quality network traffic by tracking DNS requests out-of-the-box. Identify under-performing DNS servers.
MySQL does not limit the number of slaves that you can connect to the master server in a replication topology. If the data churn on the master is high, the serving of binary logs alone could saturate the network interface of the master. Ripple is an open source binlog server developed by Pavel Ivanov.
Time To First Byte: Beyond Server Response Time Time To First Byte: Beyond Server Response Time Matt Zeunert 2025-02-12T17:00:00+00:00 2025-02-13T01:34:15+00:00 This article is sponsored by DebugBear Loading your website HTML quickly has a big impact on visitor experience. TCP: Establishing a reliable connection to the server.
We’re no longer living in an age where large companies require only physical servers, with similar and rarely changing configurations, that could be manually maintained in a single Datacenter. And, applying the “Everything as Code” principles can greatly help achieve that. Benefits of Everything as Code. Dynatrace news.
A critical security threat for cloud-native architectures SSRF is a web security vulnerability that allows an attacker to make a server-side application send requests to unintended locations. This can include internal services within an organizations infrastructure or external systems.
The Qualys Threat Research Unit (TRU) has discovered a Remote Unauthenticated Code Execution (RCE) vulnerability in OpenSSH server (sshd) in glibc-based Linux systems. Analyze network flow logs Last but not least, your network logs are the ultimate source of data. The CVE assigned to this vulnerability is CVE-2024-6387.
These vulnerabilities, identified as CVE-2025-1097 , CVE-2025-1098 , CVE-2025-24514 , and CVE-2025-1974 , allow unauthenticated remote code execution (RCE) and unauthorized access to secrets stored across all namespaces in a Kubernetes cluster. Check out the Network functions topic in the Dynatrace docs to learn more about the command.
In this post, we show you how to connect to an SSL-enabled MongoDB replica set configured with self-signed certificates using PyMongo, and how to test MongoDB failover behavior in your code. 1305:12 @(shell):1:1 2019-04-18T19:44:42.261+0530 I NETWORK [thread1] trying reconnect to SG-example-1.servers.mongodirector.com:27017
They may stem from software bugs, cyberattacks, surges in demand, issues with backup processes, network problems, or human errors. Software bugs Software bugs and bad code releases are common culprits behind tech outages. Software bugs Software bugs and bad code releases are common culprits behind tech outages.
Typically, the attackers attempt to exploit some weakness in the vendor’s development or delivery life cycle and attempt to inject malicious code before an application is signed and certified. It all starts with the code. Dynatrace has established a secure SDL, which automatically enforces that all developed code is reviewed by a peer.
However, with the emergence of Infrastructure as Code (IaC) practices, data engineers can now automate infrastructure provisioning, deployment, and management, ensuring reliability, scalability, and reproducibility.
The high likelihood of unreliable network connectivity led us to lean into mobile solutions for robust client side persistence and offline support. You only need to write platform-specific code where it’s necessary, for example, to implement a native UI or when working with platform-specific APIs.
Because container as a service doesn’t rely on a single code language or code stack, it’s platform agnostic. The emergence of Docker and other container services enabled companies to transport code quickly and easily. IaaS provides direct access to compute resources such as servers, storage, and networks.
According to the 2022 CISO Research Report , only 25% of respondents’ security teams “can access a fully accurate, continuously updated report of every application and code library running in production in real-time.” Undetected, the compromised code could allow attackers to access data they’re not authorized to have.
Open Connect Open Connect is Netflix’s content delivery network (CDN). video streaming) takes place in the Open Connect network. The network devices that underlie a large portion of the CDN are mostly managed by Python applications. If any of this interests you, check out the jobs site or find us at PyCon. are you logged in?
A standard Docker container can run anywhere, on a personal computer (for example, PC, Mac, Linux), in the cloud, on local servers, and even on edge devices. These tools integrate tightly with code repositories (such as GitHub) and continuous integration and continuous delivery (CI/CD) pipeline tools (such as Jenkins). Networking.
One option is purchasing your own CA-signed SSL certificates and configuring them on the MongoDB server. If your application connects to the production database over a public network, do reach out to support@scalegrid.io Note: All the code samples have been tested using MongoDB Driver v2.8.1 Else the code samples will not work.
Firstly, managing virtual networks can be complex as networking in a virtual environment differs significantly from traditional networking. Therefore, they experience how the application code functions and how the application operations depend on the underlying hardware resources and the operating system managed by Hyper-V.
For two decades, Dynatrace NAM—Network Application Monitoring, formerly known as DC RUM—has been successfully monitoring the user experience of our customers’ enterprise applications. SNMP managed the costs of network links well, but not the sources of those costs (i.e., Dynatrace news. Performance has always mattered.
To make this possible, the application code should be instrumented with telemetry data for deep insights, including: Metrics to find out how the behavior of a system has changed over time. When using autoscaling-mechanisms and having a lot of application containers, tracing requests through the network is a challenging task.
But there’s more than just a need for minimizing resource (CPU, memory, storage) and network (bandwidth) consumption for observability at the edge. Moreover, edge environments can be highly dynamic, with devices frequently joining and leaving the network. Data is integrated seamlessly with Kubernetes topology.
Concatenating our files on the server: Are we going to send many smaller files, or are we going to send one monolithic file? Compressing them over the network: Which compression algorithm, if any, will we use? Connection One thing we haven’t looked at is the impact of network speeds on these outcomes.
Despite the name, serverless computing still uses servers. This means companies can access the exact resources they need whenever they need them, rather than paying for server space and computing power they only need occasionally. If servers reach maximum load and capacity in-house, something has to give before adding new services.
While memory allocation analysis can show wasteful or inefficient code, it can also reveal different problems, one of which we’ll examine in this blog post. We recently extended the pre-shipped code-level API definitions to group logical parts of our code so they’re consistently highlighted in all code-level views.
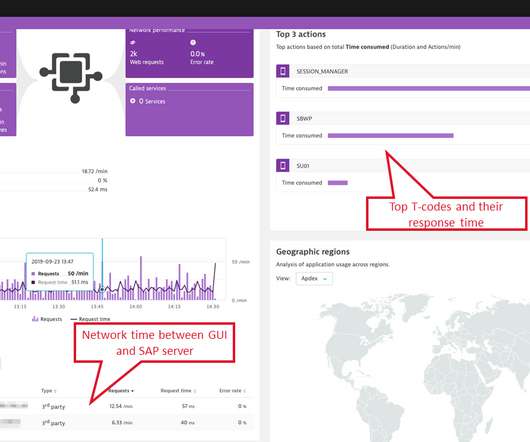
We do this by reporting on every T-code execution of every SAP user (SAP T-code, or transaction code, is a shortcut key that provides direct access to the desired transaction from anywhere within the SAP system). Was it the server, the network, or the database that caused the degraded response time?
Since December 10, days after a critical vulnerability known as Log4Shell was discovered in servers supporting the game Minecraft, millions of exploit attempts have been made of the Log4j 2 Java library, according to one team tracking the impact, with potential threat to millions more applications and devices across the globe. Dynatrace news.
TTFB is a good measure of your server response times and general back-end health, and issues here may have knock-on effects later down the line (namely with Largest Contentful Paint). More accurately, DOMContentLoaded signifies that all blocking and defer and type=module code has finished running. log ( window. performance. Who knows?!
Cloud-native technologies and microservice architectures have shifted technical complexity from the source code of services to the interconnections between services. Deep-code execution details. OneAgent implements network zones to create traffic routing rules and limit cross data-center traffic. Dynatrace news.
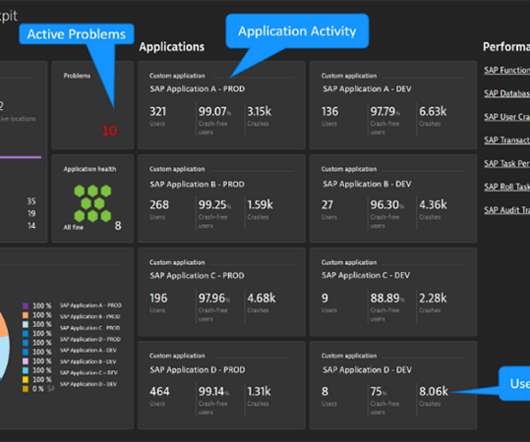
The SAP Module Dashboard details the experience of the users and transaction code executions for each specific area , with t op transactions and users displayed. The most important part s are the impact s on users and longest-running transaction codes , as these are the indicators for the overall health of module performance.
IT infrastructure is the heart of your digital business and connects every area – physical and virtual servers, storage, databases, networks, cloud services. This shift requires infrastructure monitoring to ensure all your components work together across applications, operating systems, storage, servers, virtualization, and more.
How to assess an environment’s security posture, risk and threat profile, and possible attack vectors, where perhaps you didn’t code the application or build the infrastructure, and where new code is deployed frequently, and the infrastructure is constantly changing? And this poses a significant risk.
For example, poorly written code can consume a lot of resources, or an application can make unnecessary calls to cloud services. Are there rogue servers running in the environment where ITOps, CloudOps, or another team can’t assign or identify who’s financially responsible for it? Suboptimal architecture design.
TLDR eBPF is a mechanism that makes the kernel dynamically programmable without modifying the source code. eBPF has been running in production for over half a decade at an internet scale on millions of servers. eBPF use cases range from observability, networking, security, tracing, and profiling.
In these blogs, we dove deep into how the frameworks work, their setup requirements, pros and cons, and how they performed in standby server tests, primary server tests and network isolation tests (split brain scenario) to help you determine the best framework to improve the uptime for your PostgreSQL-powered applications.
The Operator also manages configurations across a fleet of Collectors using Open Agent Management Protocol (OpAMP), which is a network protocol for remotely managing large fleets of data collection agents. Instrumentation Instrumentation is the process of adding code to software to generate telemetry signalslogs, metrics, and traces.
At the same time, open source software (OSS) libraries now account for more than 70% of most applications’ code base, increasing the risk of application vulnerabilities. RASP capabilities aim to close the gap left by application security testing and network perimeter controls such as web application firewalls (WAFs). million attacks.
Remote calls are never free; they impose extra latency, increase probability of an error, and consume network bandwidth. This can become an issue for some applications, for example, on mobile devices with limited network bandwidth. This generated code contains classes for defined messages, together with message and field descriptors.
The process involves monitoring various components of the software delivery pipeline, including applications, infrastructure, networks, and databases. Infrastructure monitoring Infrastructure monitoring reviews servers, storage, network connections, virtual machines, and other data center elements that support applications.
Function as a service is a cloud computing model that runs code in small modular pieces, or microservices. Cloud providers then manage physical hardware, virtual machines, and web server software management. In a FaaS model, developers can write code functions on demand, without being hindered by dependencies on existing applications.
DevOps platform engineers are responsible for cloud platform availability and performance, as well as the efficiency of virtual bandwidth, routers, switches, virtual private networks, firewalls, and network management. Version control system and source code management with end-to-end DevOps platform and cloud-hosted Git services.
A lot of people surmise that TTFB is merely time spent on the server, but that is only a small fraction of the true extent of things. TTFB isn’t just time spent on the server, it is also the time spent getting from our device to the sever and back again (carrying, that’s right, the first byte of data!). Expect closer to 75ms.
Rethinking Server-Timing As A Critical Monitoring Tool. Rethinking Server-Timing As A Critical Monitoring Tool. In the world of HTTP Headers, there is one header that I believe deserves more air-time and that is the Server-Timing header. Setting Server-Timing. Sean Roberts. 2022-05-16T10:00:00+00:00.
Years later, a few configuration management solutions came into play that required heavy amounts of coding, but proved that the industry was moving toward compartmentalized automation solutions. These evaluations that I hard-coded into a script were now embedded into the back-end of Ansible’s modular approach.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content