This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
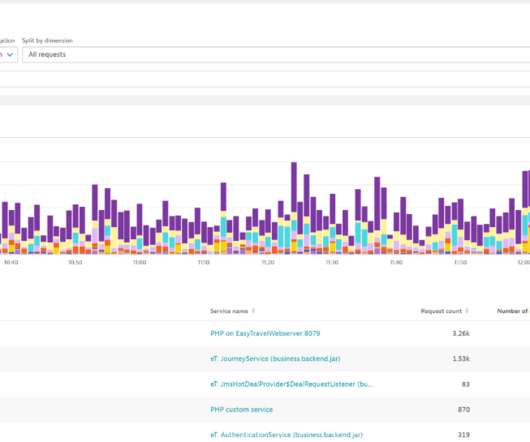
In an existing application landscape, however, it can be difficult to get to those metrics. A larger financial institution is using the analysis to report business metrics on dashboards and make them accessible via the Dynatrace API. Optimize your application and business performance by analyzing request- and service-based metrics.
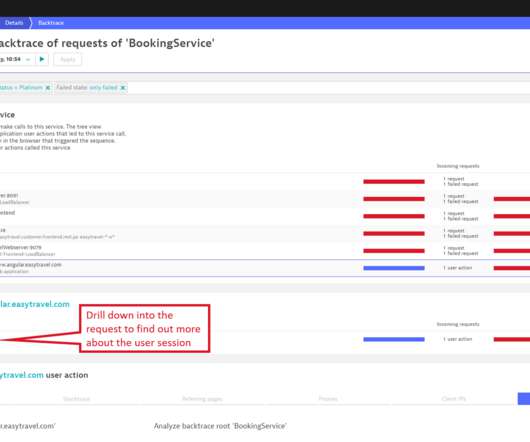
Select a Metric and Aggregation to get started. You can choose any standard Dynatrace metric and any request attribute. Simply switch the metric to Failure rate to find out if there was an error that might have impacted your platinum customers. You might guess that the relatively long booking time is caused by a failure.
The emerging concepts of working with DevOps metrics and DevOps KPIs have really come a long way. DevOps metrics to help you meet your DevOps goals. Like any IT or business project, you’ll need to track critical key metrics. Here are nine key DevOps metrics and DevOps KPIs that will help you be successful.
Amazon Bedrock , equipped with Dynatrace Davis AI and LLM observability , gives you end-to-end insight into the Generative AI stack, from code-level visibility and performance metrics to GenAI-specific guardrails. Send unified data to Dynatrace for analysis alongside your logs, metrics, and traces.
Key components of GitOps are declarative infrastructure as code, orchestration, and observability. Many observability solutions don’t support an “as code” approach. Dynatrace enables software intelligence as code. Observability is required for effective collaboration and automation.
OpenTelemetry metrics are useful for augmenting the fully automatic observability that can be achieved with Dynatrace OneAgent. OpenTelemetry metrics add domain specific data such as business KPIs and license relevant consumption details. Enterprise-grade observability for custom OpenTelemetry metrics from AWS. Dynatrace news.
To ensure observability, the open source CNCF project OpenTelemetry aims at providing a standardized, vendor-neutral way of pre-instrumenting libraries and platforms and annotating UserLAnd code. New OpenTelemetry metrics exporters provide the broadest language support on the market.
With Dynatrace, you can also validate your findings against Real User Monitoring data or even drill down to the code level to pinpoint the root cause of a change in performance. Recently introduced improvements to Visually complete and new web performance metrics for Real User Monitoring are now available for Synthetic Monitoring as well.
Welcome back to the second part of our blog series on how easy it is to get enterprise-grade observability at scale in Dynatrace for your OpenTelemetry custom metrics. In Part 1 , we announced our new OpenTelemetry custom-metric exporters that provide the broadest language coverage on the market, including Go , .NET record(value); }.
Migrating Critical Traffic At Scale with No Downtime — Part 1 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Hundreds of millions of customers tune into Netflix every day, expecting an uninterrupted and immersive streaming experience. This technique facilitates validation on multiple fronts.
Now that you’ve deployed your code, it’s time to monitor it, collect data, and analyze your metrics. You’ve just released your new app into the wild, live in production. Your job is done, right? Without application performance monitoring in place, you can’t accurately determine how well things are going. Are people using your app?
In my last post , I started to outline the process I go through when tuning queries – specifically when I discover that I need to add a new index, or modify an existing one. This is where index tuning becomes an art. Then I roll through and force each index with a hint, capturing the plan and performance metrics for each execution.
To provide automated feedback for developers, the concept of quality gates for static code analysis in continuous integration is widely adopted throughout the industry. The developer must pause their current engineering work to address the reported issue and consider the code changes they worked on a few days or weeks prior.
Similar to the observability desired for a request being processed by your digital services, it’s necessary to comprehend the metrics, traces, logs, and events associated with a code change from development through to production. Code : The branch for the new feature in a GitHub repository is merged into the main branch.
From a cost perspective, internal customers waste valuable time sending tickets to operations teams asking for metrics, logs, and traces to be enabled. A team looking for metrics, traces, and logs no longer needs to file a ticket to get their app monitored in their own environments. This approach is costly and error prone.
Open-source metric sources automatically map to our Smartscape model for AI analytics. We’ve just enhanced Dynatrace OneAgent with an open metric API. Here’s a quick overview of what you can achieve now that the Dynatrace Software Intelligence Platform has been extended to ingest third-party metrics. Dynatrace news.
VMAF is a video quality metric that Netflix jointly developed with a number of university collaborators and open-sourced on Github. One aspect that differentiates VMAF from other traditional metrics such as PSNR or SSIM, is that VMAF is able to predict more consistently across spatial resolutions, across shots, and across genres (for example.
Building on its advanced analytics capabilities for Prometheus data , Dynatrace now enables you to create extensions based on Prometheus metrics. Without any coding, these extensions make it easy to ingest data from these technologies and provide tailor-made analysis views and zero-config alerting. Prometheus in Kubernetes ?and
This means, you don’t need to change even a single line of code in the serverless functions themselves. Full integration with existing Dynatrace capabilities for AWS Lambda (for example, metric ingestion via AWS Cloud Watch). So please stay tuned! Serverless functions extend applications to accelerate speed of innovation.
Are you applying AI to the unique metrics and KPIs that matter most to the success of your digital business? Do you provide dashboards and analytics that combine technical and business metrics that are specific to your business? Dynatrace out-of-the-box metrics generally focus on availability, failure rate, and performance.
Observability Observability is the ability to determine a system’s health by analyzing the data it generates, such as logs, metrics, and traces. There are three main types of telemetry data: Metrics. Metrics are typically aggregated and stored in time series databases for monitoring and alerting purposes.
Every service and component exposes observability data (metrics, logs, and traces) that contains crucial information to drive digital businesses. To connect these siloes, and to make sense out of it requires massive manual efforts including code changes and maintenance, heavy integrations, or working with multiple analytics tools.
With support for the new Metrics REST API , Davis Assistant will soon support many new interactions for retrieving high-value metrics. In addition, stay tuned for a code-free interaction builder that you can use to quickly map custom interactions, such as “What’s the shopping cart abandonment rate?”,
In particular, the following capabilities are included in this release of OneAgent for Linux on Z platform: Deep-code monitoring. OneAgent for IBM Z platform comes with several deep-code monitoring modules: Java, Apache/IHS, and IIB/MQ (read more about this announcement in our blog post about IBM Integration Bus monitoring ).
Dynatrace has offered a Lambda code module for Node.js In theory, an existing code module or agent can be used to monitor a Lambda function if there’s a way to load it into the running Lambda process. Dynatrace tackled these challenges by writing our Lambda code module from scratch to include the following: A small file size.
Any time you run a test with WebPageTest, you’ll get this table of different milestones and metrics. Higher variance means a less stable metric across pages. I can see from the screenshot above that TTFB is my most stable metrics—no one page appears to have particularly expensive database queries or API calls on the back-end.
By collecting and analyzing key performance metrics of the service over time, we can assess the impact of the new changes and determine if they meet the availability, latency, and performance requirements. They enable us to further fine-tune and configure the system, ensuring the new changes are integrated smoothly and seamlessly.
However, understanding the performance of different application types requires an emphasis on different performance metrics, that is, key performance metrics. For many traditional web applications , User action duration is considered the best metric available for web-performance optimization.
A metric crossed a threshold. You’re half awake and wondering, “Is there really a problem or is this just an alert that needs tuning? Telltale learns what constitutes typical health for an application, no alert tuning required. Metrics are a key part of understanding application health. Client metrics and QoE changes.
You will need to know which monitoring metrics for Redis to watch and a tool to monitor these critical server metrics to ensure its health. Redis returns a big list of database metrics when you run the info command on the Redis shell. You can pick a smart selection of relevant metrics from these.
“If you’re going to have an SLO, you should have a story in mind of why you’re setting up all these alerts and collecting all these metrics. Infrastructure as code vs infrastructure as data. Grabner noted that Dynatrace just announced the release of software intelligence as code , an enhancement of API endpoints.
Cloud-native technologies and microservice architectures have shifted technical complexity from the source code of services to the interconnections between services. Deep-code execution details. You get code-level insights into application code without code changes. Dynatrace news. The app is powered by Kubernetes.
The Dynatrace v2 Environment APIs such as the Metrics API v2 or the Monitored entites API v2 provide you with new capabilities and features, such as: RESTful, generic resources that you can use in a wide range of integration scenarios. Example: GET /metric?fields=+aggregationTypes,-description. Example: GET /metric?fields=transformations,dimensionDefinitions.
Developer tools for building container images : Docker Build creates a container image, the blueprint for a container, including everything needed to run an application – the application code, binaries, scripts, dependencies, configuration, environment variables, and so on. Watch webinar now! Observability. Here are some examples.
The short answer: The three pillars of observability—logs, metrics, and traces—converging on a data lakehouse. You’re getting all the architectural benefits of Grail—the petabytes, the cardinality—with this implementation,” including the three pillars of observability: logs, metrics, and traces in context.
Observability is typically achieved by collecting three types of data from a system, metrics, logs and traces. Some platforms provide built-in metrics, logs and traces for serverless functions, while others require additional configuration or integration with external services or agents.
This category hosts many single-purpose projects and solutions that focus either on metrics, traces, or logs. Dynatrace is the first and only solution to provide full-stack visibility into containerized workloads with zero changes required to your code or deployments. So stay tuned.
We had several goals in mind when trying to improve the baking methodology: Configuration as code Leverage Spinnaker for Continuous Delivery Eliminate Toil Configuration as Code The first part of our new Windows baking solution is Packer. We now have the software and instance configuration as code.
Observability is divided into three major verticals—metrics, logs, and distributed traces—the so-called three pillars of observability. The three pillars of observability—captured automatically, no code change required. New components are auto-instrumented on the fly, with no code change required. 1) Metrics.
This gives you deep visibility into your code running in Azure Functions, and, as a result, an understanding of its impact on overall application performance and user experience. Code-level visibility continues to be supported for.NET-based functions running in an App Service plan. Optimize your code with code-level visibility.
Dynatrace provides advanced observability across on-premises systems and cloud providers in a single platform, providing application performance monitoring, infrastructure monitoring, Artificial Intelligence-driven operations (AIOps), code-level execution, digital experience monitoring (DEM), and digital business analytics. Stay tuned.
This gives you seamless end-to-end distributed tracing for AWS Lambda functions without touching any code through auto-instrumentation, thereby helping you to better understand potential issues that may impact your end users’ experience. A single pane of glass to view trace information along with AWS CloudWatch metrics. entire stack,?including
We wanted to expand and provide business process metrics (# of total orders per restaurant, orders canceled ratios, time per order, ingredients in or out of stock …) to quickly react to any issues and also get automatically alerted on anomalies. Rejections and Cancellation of Orders (our Code Red): 30% faster MTTR and 50% better visibility.
As an example, Kubernetes does not deploy source code, nor does it have the capacity to connect application-level services. In fact, once containerized, many of these services and the source code itself is virtually invisible in a standalone Kubernetes environment. Code level visibility for fast problem resolution.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content