This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When first working on a new site-speed engagement, you need to work out quickly where the slowdowns, blindspots, and inefficiencies lie. Any time you run a test with WebPageTest, you’ll get this table of different milestones and metrics. Higher variance means a less stable metric across pages. Visualising the Data.
Lines of code govern almost everything we do in our day-to-day activities. In an attempt to hold their place within the market, developers are having to speed their process up whilst delivering products of ever-increasing quality. Often speed and quality seem at odds with one another, but in reality, this isn’t the case.
I realized that our platforms unique ability to contextualize security events, metrics, logs, traces, and user behavior could revolutionize the security domain by converging observability and security. Collect observability and security data user behavior, metrics, events, logs, traces (UMELT) once, store it together and analyze in context.
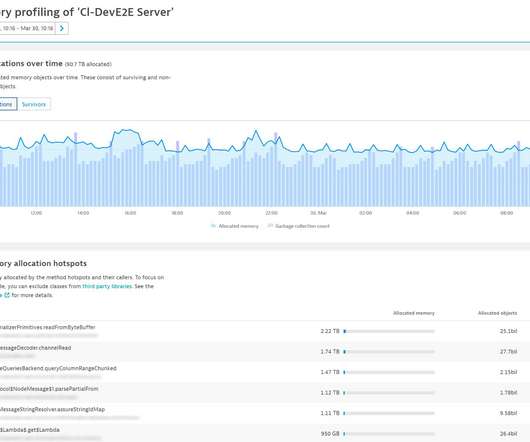
Optimize your code by finding and fixing the root cause of garbage collection problems. These details arm you with the knowledge necessary to find the respective code and remove unnecessary allocations. Any significant reduction in allocations will inevitably speed up your code. So what’s going on here?
Organizations can customize quality gate criteria to validate technical service-level objectives (SLOs) and business goals, ensuring early detection and resolution of code deficiencies. Automating quality gates is ideal, as it minimizes manually checking and validating key metrics throughout the SDLC.
Key components of GitOps are declarative infrastructure as code, orchestration, and observability. Many observability solutions don’t support an “as code” approach. Dynatrace enables software intelligence as code. Observability is required for effective collaboration and automation.
Metrics matter. But without complex analytics to make sense of them in context, metrics are often too raw to be useful on their own. To achieve relevant insights, raw metrics typically need to be processed through filtering, aggregation, or arithmetic operations. Examples of metric calculations. Dynatrace news.
As a result, organizations need to monitor mobile app performance metrics that are meaningful and actionable by gaining adequate observability of mobile app performance. There are many common mobile app performance metrics that are used to measure key performance indicators (KPIs) related to user experience and satisfaction.
With Dynatrace, you can also validate your findings against Real User Monitoring data or even drill down to the code level to pinpoint the root cause of a change in performance. Recently introduced improvements to Visually complete and new web performance metrics for Real User Monitoring are now available for Synthetic Monitoring as well.
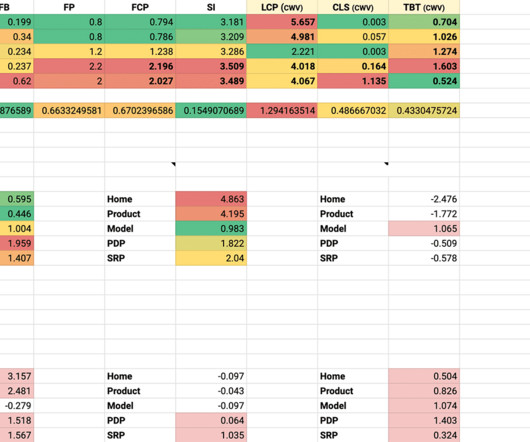
Metrics that offer measurable, repeatable insight into the user experience from the moment they arrive on a website from a mobile or desktop device. Great user experiences start with Core Web Vitals (CWVs) — a set of metrics defined by Google to help measure user experience at scale. When do these metrics matter?
I never thought I’d write an article in defence of DOMContentLoaded , but here it is… For many, many years now, performance engineers have been making a concerted effort to move away from technical metrics such as Load , and toward more user-facing, UX metrics such as Speed Index or Largest Contentful Paint. Or are they…?
This is an update to my 2020 article Site-Speed Topography. Around two and a half years ago, I debuted my Site-Speed Topography technique for getting broad view of an entire site’s performance from just a handful of key URLs and some readily available metrics. What Is Site-Speed Topography? Are any metrics over budget?
For this blog post I want to focus on how you can leverage Dynatrace to get a lot of insight into your plugin code. Part 1 – The code as it stood. The Juniper plugin is an ActiveGate Plugin written in Python, it consists of a script that connects to a Juniper Networks device and collects some facts and metrics about it.
Annie leads the Chrome SpeedMetrics team at Google, which has arguably had the most significant impact on web performance of the past decade. It's really important to acknowledge that none of this would have been possible without the great work from Annie and her small-but-mighty SpeedMetrics team at Google.
VMAF is a video quality metric that Netflix jointly developed with a number of university collaborators and open-sourced on Github. One aspect that differentiates VMAF from other traditional metrics such as PSNR or SSIM, is that VMAF is able to predict more consistently across spatial resolutions, across shots, and across genres (for example.
As businesses increasingly embrace these technologies, integrating IoT metrics with advanced observability solutions like Dynatrace becomes essential to gaining additional business value through end-to-end observability. Both methods allow you to ingest and process raw data and metrics.
Spring also introduced Micrometer, a vendor-agnostic metric API with rich instrumentation options. Soon after, Dynatrace built a registry for exporting Micrometer metrics. Our data APIs, which ingest millions of metrics, traces, and logs per second, are reconciled using Micrometer-based metrics.
Provide self-service platform services with dedicated UI for development teams to improve developer experience and increase speed of delivery. Monitoring-as-code can also be configured in GitOps fashion. Open source logs and metrics take precedence in the monitoring process. All this can be self-defined in the source code.
Connection One thing we haven’t looked at is the impact of network speeds on these outcomes. Compile: the parsed code is compiled into optimised bytecode. Execute: the code is now executed, and does whatever we wanted it to do. It’s better to send no code than it is to compress 1MB down to 50KB. For example: vendor.js
Staying ahead of customer needs requires speed and agility from all phases of the software development life cycle (SDLC). DevOps automation tools speed up delivery cycles by reducing human error and bottlenecks, resulting in fewer and shorter feedback loops. It helps to assess the long- and short-term efficiency and speed of DevOps.
Similar to the observability desired for a request being processed by your digital services, it’s necessary to comprehend the metrics, traces, logs, and events associated with a code change from development through to production. Code : The branch for the new feature in a GitHub repository is merged into the main branch.
However, understanding the performance of different application types requires an emphasis on different performance metrics, that is, key performance metrics. For many traditional web applications , User action duration is considered the best metric available for web-performance optimization.
However, getting reliable answers from observability data so teams can automate more processes to ensure speed, quality, and reliability can be challenging. This drive for speed has a cost: 22% of leaders admit they’re under so much pressure to innovate faster that they must sacrifice code quality. What is DevOps?
When an incident occurs, developers need to know what data to look at, where the incident occurred, and other relevant metrics. But developers need code-level visibility and code-level data.” That’s not how I envision code-level observability,” Laifenfeld said. KubeCon North America is this week.
Developers want to write high-quality code and deploy it quickly. One particular use case for Austrian banking software developer Raiffeisen involves using Keptn to automate the production release and readiness validation of all its products using scoring metrics. Everything is code and version-controlled in GitOps.
The only way to address these challenges is through observability data — logs, metrics, and traces. IT pros want a data and analytics solution that doesn’t require tradeoffs between speed, scale, and cost. Your key business objectives will drive your strategy and metrics. But it doesn’t stop there.
A full-stack observability solution uses telemetry data such as logs, metrics, and traces to give IT teams insight into application, infrastructure, and UX performance. Not just infrastructure connections, but the relationships and dependencies between containers, microservices , and code at all network layers. Watch webinar now!
Thats why the Time to First Byte (TTFB) metric is important: it measures how soon after navigation the browser starts receiving the HTML response. But actually, theres a lot more to optimizing this metric. What Components Make Up The Time To First Byte Metric? TTFB stands for Time to First Byte. But where does it measure from ?
The short answer: The three pillars of observability—logs, metrics, and traces—converging on a data lakehouse. As teams try to gain insight into this data deluge, they have to balance the need for speed, data fidelity, and scale with capacity constraints and cost. Logs on Grail Log data is foundational for any IT analytics.
Traditional monitoring systems cannot keep up with the speed of change in those highly dynamic large-scale container environments. These enhancements include: Integration of the new Kubernetes/OpenShift cluster metrics with custom charting. Universal container-level metrics for resource contention analytics.
As I see it, there are two main issues when it comes to measuring performance changes (note, not improvements , but changes) in the lab: Site-speed is nondeterministic 1. As noted above, it’s not actually possible to improve certain metrics in their own right. There are myriad reasons for this that I won’t cover here. duration ).
Telemetry data — such as metrics, logs, and traces — gives IT teams crucial context to understand how all entities are connected. This includes not only infrastructure connections but also the relationships and dependencies between containers, microservices , and code at all network layers. These are not only numerous but also dynamic.
You will need to know which monitoring metrics for Redis to watch and a tool to monitor these critical server metrics to ensure its health. Redis returns a big list of database metrics when you run the info command on the Redis shell. You can pick a smart selection of relevant metrics from these.
As a result, site reliability has emerged as a critical success metric for many organizations. Microservices-based architectures and software containers enable organizations to deploy and modify applications with unprecedented speed. The following three metrics are commonly used to measure success: Service-level agreements (SLAs).
These technologies are poorly suited to address the needs of modern enterprises—getting real value from data beyond isolated metrics. Further, it builds a rich analytics layer powered by Dynatrace causational artificial intelligence, Davis® AI, and creates a query engine that offers insights at unmatched speed. Thus, Grail was born.
As they increase the speed of product innovation and software development, organizations have an increasing number of applications, microservices and cloud infrastructure to manage. Further, many organizations—more than 90%—have turned to cloud computing to navigate the highwire act of balancing speed and quality.
As a result, teams can focus on writing code and building features rather than dealing with infrastructure nuances. The pair showed how to track factors including developer velocity, platform adoption, DevOps research and assessment metrics, security, and operational costs. “It makes them more productive.
You can, for example, drive ad hoc multidimensional analysis to analyze, chart, and report on microservice-based metrics without code changes. You can use powerful dashboard capabilities to visualize whatever metrics are most relevant to your teams and let the Davis AI causation engine automatically identify the root cause of problems.
Effective application development requires speed and specificity. Function as a service is a cloud computing model that runs code in small modular pieces, or microservices. In a FaaS model, developers can write code functions on demand, without being hindered by dependencies on existing applications. Dynatrace news.
Today, the speed of software development has become a key business differentiator, but collaboration, continuous improvement, and automation are even more critical to providing unprecedented customer value. Dynatrace’s version awareness allows you to stay in control despite speeding up application delivery.
Cloud-native technologies and microservice architectures have shifted technical complexity from the source code of services to the interconnections between services. Deep-code execution details. Dynatrace news. Always-on profiling in transaction context. The app is powered by Kubernetes. public Tracer initTracer() {.
Achieving the ideal state with aggregated, centralized log data, metrics, traces , and other metadata is challenging—particularly for multicloud environments. where an error occurred at the code level. Lining up traces, logs, and metrics based on user events and timestamps provides the most complete picture of full-stack dependencies.
IT pros need a data and analytics platform that doesn’t require sacrifices among speed, scale, and cost. Therefore, many organizations turn to a data lakehouse, which combines the flexibility and cost-efficiency of a data lake with the contextual and high-speed querying capabilities of a data warehouse. Learn more. Learn more.
How To Benchmark And Improve Web Vitals With Real User Metrics. How To Benchmark And Improve Web Vitals With Real User Metrics. Different products will have different benchmarks and two apps may perform differently against the same metrics, but still rank quite similarly to our subjective “good” and “bad” verdicts.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content