This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
"Employing these Metrics to excel the performance of code directly impacts the profitability of the business. For the developers, practicing to write a good quality code in the initial phase of the coding job not only prevents the efforts and hours spent in précising the errors but also the costs are reduced.
Provide an at-a-glance view of your system’s health and performance Dynatrace guides you in quickly getting the most valuable SLOs set up in just a few clicks. Heterogeneous services require heterogeneous indicators Metrics, logs, and traces are the core ingredients for making your environment observable.
Imagine you’re using a lot of OpenTelemetry and Prometheus metrics on a crucial platform. A histogram is a specific type of metric that allows users to understand the distribution of data points over a period of time. In practical applications, percentiles are particularly useful for web performance analysis.
Code Quality defines that the code is good, which means code is of high quality, and code is bad, which means code is of low quality. Code can be considered good quality if it is clear, simple, well tested, bug-free, refactored, documented, and performant.
In IT and cloud computing, observability is the ability to measure a system’s current state based on the data it generates, such as logs, metrics, and traces. In a monitoring scenario, you typically preconfigure dashboards that are meant to alert you to performance issues you expect to see later. What is observability?
Mobile applications (apps) are an increasingly important channel for reaching customers, but the distributed nature of mobile app platforms and delivery networks can cause performance problems that leave users frustrated, or worse, turning to competitors. What is mobile app performance? Some of the most important KPIs are listed below.
The release candidate of OpenTelemetry metrics was announced earlier this year at Kubecon in Valencia, Spain. Since then, organizations have embraced OTLP as an all-in-one protocol for observability signals, including metrics, traces, and logs, which will also gain Dynatrace support in early 2023.
But to be scalable, they also need low-code/no-code solutions that don’t require a lot of spin-up or engineering expertise. With the Dynatrace modern observability platform, teams can now use intuitive, low-code/no-code toolsets and causal AI to extend answer-driven automation for business, development and security workflows.
The emerging concepts of working with DevOps metrics and DevOps KPIs have really come a long way. DevOps metrics to help you meet your DevOps goals. Like any IT or business project, you’ll need to track critical key metrics. Here are nine key DevOps metrics and DevOps KPIs that will help you be successful.
I realized that our platforms unique ability to contextualize security events, metrics, logs, traces, and user behavior could revolutionize the security domain by converging observability and security. Collect observability and security data user behavior, metrics, events, logs, traces (UMELT) once, store it together and analyze in context.
Dynatrace has recently extended its Kubernetes operator by adding a new feature, the Prometheus OpenMetrics Ingest , which enables you to import Prometheus metrics in Dynatrace and build SLO and anomaly detection dashboards with Prometheus data. Here we’ll explore how to collect Prometheus metrics and what you can achieve with them.
Most of these leverage the unique capability of Dynatrace OneAgent® to extract business data from in-flight application payloads — without writing any code. For years, logs have been the dominant approach many observability vendors have taken to report business metrics on dashboards.
Traditional debugging approaches, logs, and occasional remote breakpoint instrumentation cant easily keep pace with cloud-native AI deployments, where performance, compliance, and costs are all on the line. Send unified data to Dynatrace for analysis alongside your logs, metrics, and traces.
This is achieved, in part, by establishing actionable statistical accuracy —not necessarily precise accuracy —through practical levels of metric sampling, aggregation, and extrapolation. At the same time, deep payload inspection makes it easy to extract important business data locked in application payloads—without writing any code.
Find and prevent application performance risks A major challenge for DevOps and security teams is responding to outages or poor application performance fast enough to maintain normal service. It should also be possible to analyze data in context to proactively address events, optimize performance, and remediate issues in real time.
In both bands, performance characteristics remain consistent for the entire uptime of the JVM on the node, i.e. nodes never jumped the bands. Luckily, the m5.12xl instance type exposes a set of core PMCs (Performance Monitoring Counters, a.k.a. This was our starting point for troubleshooting.
Netflix was thrilled to be the premier sponsor for the 2nd year in a row at the 2023 Conference on Digital Experimentation (CODE@MIT) in Cambridge, MA. Our next topic focused on how to understand and balance competing engagement metrics; for example, should 1 hour of gaming equal 1 hour of streaming?
That is, relying on metrics, logs, and traces to understand what software is doing and where it’s running into snags. While classic logging is an essential tool in debugging issues, it often lacks context and only provides snapshot information of one specific location in your code/application. What is OpenTelemetry?
Similar to the observability desired for a request being processed by your digital services, it’s necessary to comprehend the metrics, traces, logs, and events associated with a code change from development through to production. Code : The branch for the new feature in a GitHub repository is merged into the main branch.
Metrics matter. But without complex analytics to make sense of them in context, metrics are often too raw to be useful on their own. To achieve relevant insights, raw metrics typically need to be processed through filtering, aggregation, or arithmetic operations. Examples of metric calculations. Dynatrace news.
Let's kick off the new year by celebrating someone who has not just had a huge impact on web performance over the past few years, but who has even more exciting stuff in the works for the future: Annie Sullivan! Annie and her team navigate this arduous task with true passion for web performance and for improving the user experience.
Your teams want to iterate rapidly but face multiple hurdles: Increased complexity: Microservices and container-based apps generate massive logs and metrics. This caused you to lose complete visibility of your containers logs, performance, and error data, and you could not tell if the system was down or not.
There’s no lack of metrics, logs, traces, or events when monitoring your Kubernetes (K8s) workloads. Dynatrace Davis , our deterministic AI, recently notified our teams about a problem in one of our Keptn instances we just recently spun up to demo our automated performance analysis capabilities orchestrated by Keptn. Dynatrace news.
OpenTelemetry metrics are useful for augmenting the fully automatic observability that can be achieved with Dynatrace OneAgent. OpenTelemetry metrics add domain specific data such as business KPIs and license relevant consumption details. Enterprise-grade observability for custom OpenTelemetry metrics from AWS. Dynatrace news.
OpenTelemetry (also referred to as OTel) is an open-source observability framework made up of a collection of tools, APIs, and SDKs, that enables IT teams to instrument, generate, collect, and export telemetry data for analysis and understand software performance and behavior. Logs, metrics, and traces make up the bulk of all telemetry data.
For software engineering teams, this demand means not only delivering new features faster but ensuring quality, performance, and scalability too. One way to apply improvements is transforming the way application performance engineering and testing is done. Performance-as-a-self-service . Try it today using Keptn .
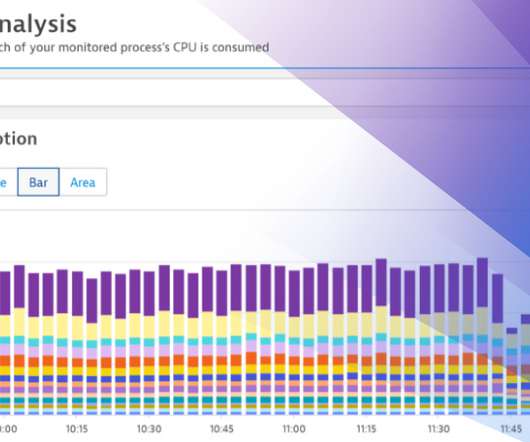
Service Level Objectives (SLO) tracking: Honeycomb charts can visualize SLOs, helping you monitor whether your services meet performance and reliability targets. Use color coding to tell a story. This is useful for identifying performance bottlenecks and understanding the overall user experience. Figure 2.
Despite having to reboot Perform 2022 from onsite in Vegas to virtual, due to changing circumstances, we’re still set to offer just the same high-quality training. This means that despite not being in Vegas, our hands-on training (HOT) session attendees will see very minimal changes as we migrate to a virtual Perform 2022.
These are just some of the topics being showcased at Perform 2023 in Las Vegas. Perform 2023 news At Perform 2023 in Las Vegas, the headliner theme is IT automation. What’s more, organizations are no longer concerned only about application performance and sales numbers. We’ll post news here as it happens!
Observability means how well you can understand what is happening in a system by collecting metrics, logs, and traces. This allows you to get comfortable with all the underlying metrics and log data. Observability of Azure infrastructure and all the services it supports helps you pinpoint performance issues and eliminate guesswork.
I never thought I’d write an article in defence of DOMContentLoaded , but here it is… For many, many years now, performance engineers have been making a concerted effort to move away from technical metrics such as Load , and toward more user-facing, UX metrics such as Speed Index or Largest Contentful Paint. Or are they…?
Fully automated code-level visibility. Apart from its best-in-class observability capabilities like distributed traces, metrics, and logs, Dynatrace OneAgent additionally provides automatic deep code-level insights for Java,NET, Node.js, PHP, and Golang, without the need to change any application code or configuration.
As organizations develop more applications and microservices, they are discovering they also need to run more performance tests in the same amount of time or less to meet service-level objectives (SLOs) that fulfill service-level agreements (SLAs). Current challenges with performance testing.
Back during Perform 2019, we introduced the next generation of the Dynatrace AI causation engine , also known as Davis. Save time by directly analyzing code-level information. With the unique code-level capabilities of Davis, we’ve reduced the number of clicks required to reach and understand code-level findings.
To address this, we introduced the term Title Health, a concept designed to help us communicate effectively and capture the nuances of maintaining each titles visibility and performance. Title Health encompasses various metrics and indicators that reflect how well a title is performing, in terms of discoverability and member engagement.
Dynatrace CEO Rick McConnell at Perform 2022 in Las Vegas. Organizations are accelerating movement to the cloud, resulting in complex combinations of hybrid, multicloud [architecture],” said Rick McConnell, Dynatrace chief executive officer at the annual Perform conference in Las Vegas this week. We gather logs, metrics and traces.
To provide automated feedback for developers, the concept of quality gates for static code analysis in continuous integration is widely adopted throughout the industry. The developer must pause their current engineering work to address the reported issue and consider the code changes they worked on a few days or weeks prior.
By Jose Fernandez , Sebastien Dabdoub , Jason Koch , Artem Tkachuk The Compute and Performance Engineering teams at Netflix regularly investigate performance issues in our multi-tenant environment. Traditional performance analysis tools such as perf can introduce significant overhead, risking further performance degradation.
The first phase involves validating functional correctness, scalability, and performance concerns and ensuring the new systems’ resilience before the migration. These include Quality-of-Experience(QoE) measurements at the customer device level, Service-Level-Agreements (SLAs), and business-level Key-Performance-Indicators(KPIs).
Department of Veterans Affairs (VA) is packaging application code along with its libraries and dependencies within an executable software unit. Dynatrace container monitoring supports customers as they collect metrics, traces, logs, and other observability-enabled data to improve the health and performance of containerized applications.
Telemetry data, such as traces and metrics, allow you to analyze the end-to-end performance of your deployed applications. You can automatically detect and analyze performance issues across your entire tech stack with Davis® AI. This is significant when coupled with the OpenShift platform.
You need to find the right tools to monitor, track and trace these systems by analyzing outputs through metrics, logs, and traces. It enables teams to quickly pinpoint the root cause of issues, fix them and optimize the application performance, giving them the confidence to deliver code faster.
Organizations can customize quality gate criteria to validate technical service-level objectives (SLOs) and business goals, ensuring early detection and resolution of code deficiencies. Automating quality gates is ideal, as it minimizes manually checking and validating key metrics throughout the SDLC.
focused on technology coverage, building on the flexibility of JMX for Java and Python-based coded extensions for everything else. While Python code can address most data acquisition and ingest requirements, it comes at the cost of complexity in implementation and use-case modeling. Comprehensive metrics support Extensions 2.0
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content