This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
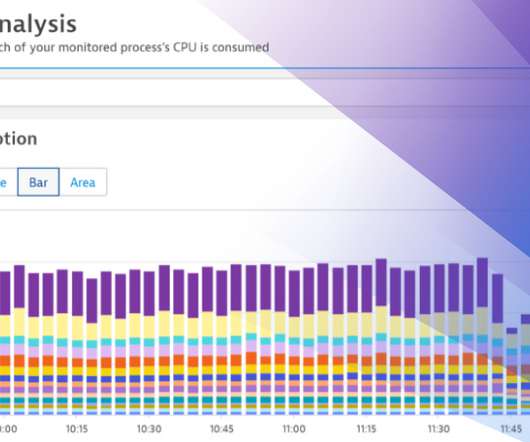
Imagine you’re using a lot of OpenTelemetry and Prometheus metrics on a crucial platform. A histogram is a specific type of metric that allows users to understand the distribution of data points over a period of time. Histograms are commonly used to define and monitor service-level objectives (SLOs).
In IT and cloud computing, observability is the ability to measure a system’s current state based on the data it generates, such as logs, metrics, and traces. What is the difference between monitoring and observability? Is observability really monitoring by another name? What is observability? In short, no.
This lets you build your SLOs around the indicators that matter to you and your customers—critical metrics related to availability, failure rates, request response times, or select logs and business events. At the same time, dedicated configuration-as-code support in Monaco and Terraform will provide a scalable, automated solution.
Most of these leverage the unique capability of Dynatrace OneAgent® to extract business data from in-flight application payloads — without writing any code. For years, logs have been the dominant approach many observability vendors have taken to report business metrics on dashboards. Business process monitoring and optimization.
The emerging concepts of working with DevOps metrics and DevOps KPIs have really come a long way. DevOps metrics to help you meet your DevOps goals. Like any IT or business project, you’ll need to track critical key metrics. Here are nine key DevOps metrics and DevOps KPIs that will help you be successful.
But to be scalable, they also need low-code/no-code solutions that don’t require a lot of spin-up or engineering expertise. IT leaders know that managing cloud environments through traditional manual monitoring practices will no longer suffice. The low-code/no-code AutomationEngine brings several benefits to customers.
On average, organizations use 10 different tools to monitor applications, infrastructure, and user experiences across these environments. Clearly, continuing to depend on siloed systems, disjointed monitoring tools, and manual analytics is no longer sustainable.
Dynatrace has recently extended its Kubernetes operator by adding a new feature, the Prometheus OpenMetrics Ingest , which enables you to import Prometheus metrics in Dynatrace and build SLO and anomaly detection dashboards with Prometheus data. Here we’ll explore how to collect Prometheus metrics and what you can achieve with them.
I realized that our platforms unique ability to contextualize security events, metrics, logs, traces, and user behavior could revolutionize the security domain by converging observability and security. Collect observability and security data user behavior, metrics, events, logs, traces (UMELT) once, store it together and analyze in context.
Take your monitoring, data exploration, and storytelling to the next level with outstanding data visualization All your applications and underlying infrastructure produce vast volumes of data that you need to monitor or analyze for insights. Use color coding to tell a story. Try different cell shapes.
Traditional monitoring approaches often require manual scripting and integration to get alerted about production-threatening issues in pre-production environments. Your teams want to iterate rapidly but face multiple hurdles: Increased complexity: Microservices and container-based apps generate massive logs and metrics.
As a result, API monitoring has become a must for DevOps teams. So what is API monitoring? What is API Monitoring? API monitoring is the process of collecting and analyzing data about the performance of an API in order to identify problems that impact users. The need for API monitoring. Ways to monitor APIs.
As a result, organizations need to monitor mobile app performance metrics that are meaningful and actionable by gaining adequate observability of mobile app performance. There are many common mobile app performance metrics that are used to measure key performance indicators (KPIs) related to user experience and satisfaction.
One of these solutions is Micrometer which provides 17+ pre-instrumented JVM-based frameworks for data collection and enables instrumentation code with a vendor-neutral API. Micrometer is used for instrumenting both out-of-the-box and custom metrics from Spring Boot applications. That’s a large amount of data to handle.
But are observability platforms—born from the collision between the demands of cloud computing and the limitations of APM and infrastructure monitoring—the best solution for managing business analytics? Observability fault lines The monitoring of complex and dynamic IT systems includes real-time analysis of baselines, trends, and anomalies.
Real user monitoring can help you catch these issues before they impact the bottom line. What is real user monitoring? Real user monitoring (RUM) is a performance monitoring process that collects detailed data about a user’s interaction with an application. Real user monitoring collects data on a variety of metrics.
Dynatrace has offered a Lambda code module for Node.js This has led to the recent release of our new Lambda monitoring extension supporting Node.js, Java, and Python. Special challenges when monitoring Lambda functions. Also, agents optimize communication and, therefore, send monitoring data to back ends in batches.
Every software development team grappling with Generative AI (GenAI) and LLM-based applications knows the challenge: how to observe, monitor, and secure production-level workloads at scale. Production performance monitoring: Service uptime, service health, CPU, GPU, memory, token usage, and real-time cost and performance metrics.
These resources generate vast amounts of data in various locations, including containers, which can be virtual and ephemeral, thus more difficult to monitor. These challenges make AWS observability a key practice for building and monitoring cloud-native applications. AWS monitoring best practices. What is AWS observability?
Many of our customers—the world’s largest enterprises—have embraced the Dynatrace SaaS approach to monitoring, which provides critical business insights powered by AI and automation for globally-distributed, heterogeneous IT landscapes. New self-monitoring environment provides out-of-the-box insights and custom alerting.
Key components of GitOps are declarative infrastructure as code, orchestration, and observability. Many observability solutions don’t support an “as code” approach. Because of these issues, developers often still lack control over the behavior of their monitoring platform. Dynatrace enables software intelligence as code.
Organizations can now accelerate innovation and reduce the risk of failed software releases by incorporating on-demand synthetic monitoring as a metrics provider for automatic, continuous release-validation processes. This metric indicates how quickly software can be released to production. Dynatrace news.
There’s no lack of metrics, logs, traces, or events when monitoring your Kubernetes (K8s) workloads. At Dynatrace we’re lucky to have Dynatrace monitor our workloads running on K8s. The post Kubernetes workload troubleshooting with metrics, logs, and traces appeared first on Dynatrace blog.
OpenTelemetry metrics are useful for augmenting the fully automatic observability that can be achieved with Dynatrace OneAgent. OpenTelemetry metrics add domain specific data such as business KPIs and license relevant consumption details. Enterprise-grade observability for custom OpenTelemetry metrics from AWS. Dynatrace news.
Observability is the new standard of visibility and monitoring for cloud-native architectures. It’s powered by vast amounts of collected telemetry data such as metrics, logs, events, and distributed traces to measure the health of application performance and behavior. Observability brings multicloud environments to heel.
Monitoring Kubernetes is an important aspect of Day 2 o perations and is often perceived as a significant challenge. A container with inefficient code might affect critical workloads and practically make the whole node unusable , or worse, because of replication, it can impact the whole cluster. Node and w orkload health .
With the world’s increased reliance on digital services and the organizational pressure on IT teams to innovate faster, the need for DevOps monitoring tools has grown exponentially. But when and how does DevOps monitoring fit into the process? And how do DevOps monitoring tools help teams achieve DevOps efficiency?
Prometheus is an open-source monitoring and alerting toolkit for services and applications that run in containers. Prometheus collects metrics from a number endpoints that expose metrics in the OpenMetrics format. The Dynatrace AMP extension enables you to easily ingest Prometheus metrics into Dynatrace. Dynatrace news.
Log monitoring, log analysis, and log analytics are more important than ever as organizations adopt more cloud-native technologies, containers, and microservices-based architectures. What is log monitoring? Log monitoring is a process by which developers and administrators continuously observe logs as they’re being recorded.
That is, relying on metrics, logs, and traces to understand what software is doing and where it’s running into snags. While classic logging is an essential tool in debugging issues, it often lacks context and only provides snapshot information of one specific location in your code/application. What is OpenTelemetry?
Loosely defined, observability is the ability to understand what’s happening inside a system from the knowledge of the external data it produces, which are usually logs, metrics, and traces. Monitoring begins here. Logs, metrics, and traces make up the bulk of all telemetry data.
According to InfoQ , Kubernetes monitoring offers substantial benefits for container management, but it’s not a complete platform in and of itself. “You need to understand and detect non-performing code or where and how exceptions happen — which user or transaction triggered it, its context, its backtrace, and its metadata.
One of the more popular use cases is monitoring business processes, the structured steps that produce a product or service designed to fulfill organizational objectives. By treating processes as assets with measurable key performance indicators (KPIs), business process monitoring helps IT and business teams align toward shared business goals.
Dynatrace Digital Experience Monitoring , as part of the Dynatrace Software Intelligence Platform, connects front-end monitoring and the outside-in user perspective with application performance to understand the impact of performance issues across your full stack on user experience and business outcomes. Virginia (Azure), N.
Fully automated code-level visibility. Apart from its best-in-class observability capabilities like distributed traces, metrics, and logs, Dynatrace OneAgent additionally provides automatic deep code-level insights for Java,NET, Node.js, PHP, and Golang, without the need to change any application code or configuration.
But this approach introduced new complexity and a need for more advanced cloud monitoring capabilities. Dynatrace’s cloud monitoring capabilities are helping Porsche Informatik to simplify complexity and drive improved digital experiences for customers. Simplifying complexity with cloud monitoring. The key value of Dynatrace.
I never thought I’d write an article in defence of DOMContentLoaded , but here it is… For many, many years now, performance engineers have been making a concerted effort to move away from technical metrics such as Load , and toward more user-facing, UX metrics such as Speed Index or Largest Contentful Paint. Or are they…?
Department of Veterans Affairs (VA) is packaging application code along with its libraries and dependencies within an executable software unit. Dynatrace container monitoring supports customers as they collect metrics, traces, logs, and other observability-enabled data to improve the health and performance of containerized applications.
From a cost perspective, internal customers waste valuable time sending tickets to operations teams asking for metrics, logs, and traces to be enabled. A team looking for metrics, traces, and logs no longer needs to file a ticket to get their app monitored in their own environments. Monitoring such an application is easy.
It shows critical SLOs for latency and availability, as well as the most important OpenAI generative AI service metrics, such as response time, error count, and the overall number of requests. OneAgent can automatically monitor all C#,NET, Java, Go, and NodeJS bindings. Our example dashboard below visualizes OpenAI token consumption.
Dynatrace with Red Hat OpenShift monitoring stands out for the following reasons: With infrastructure health monitoring and optimization, you can assess the status of your infrastructure at a glance to understand resource consumption and thus optimize resource allocation for cost efficiency.
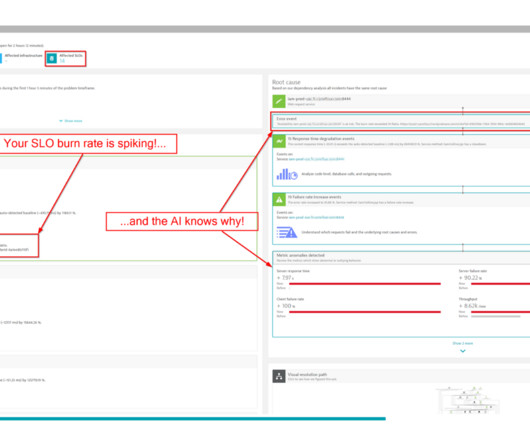
SLO monitoring and alerting on SLOs using error-budget burn rates are critical capabilities that can help organizations achieve that goal. SLOs are specifically processed metrics that help businesses balance breakthroughs with reliability. What is SLO monitoring? And what is an error budget burn rate?
Even the best baseline approaches come with a tiny percentage of false-positive alerts, the number being directly proportional to the number of components you’re monitoring. Save time by directly analyzing code-level information. Beyond traceability: From root cause to code-level context in a single click.
Teams are using concepts from site reliability engineering to create SLO metrics that measure the impact to their customers and leverage error budgets to balance innovation and reliability. Nobl9 integrates with Dynatrace to gather SLI metrics for your infrastructure and applications using real-time monitoring or synthetics.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content