This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Migrating Critical Traffic At Scale with No Downtime — Part 1 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Hundreds of millions of customers tune into Netflix every day, expecting an uninterrupted and immersive streaming experience. This approach has a handful of benefits.
Migrating Critical Traffic At Scale with No Downtime — Part 2 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Picture yourself enthralled by the latest episode of your beloved Netflix series, delighting in an uninterrupted, high-definition streaming experience. This is where large-scale system migrations come into play.
This gives fascinating insights into the network topography of our visitors, and how much we might be impacted by high latency regions. Round-trip-time (RTT) is basically a measure of latency—how long did it take to get from one endpoint to another and back again? What is RTT? RTT isn’t a you-thing, it’s a them-thing.
Organizations can customize quality gate criteria to validate technical service-level objectives (SLOs) and business goals, ensuring early detection and resolution of code deficiencies. Ultimately, quality gates safeguard code viability as it advances through the delivery pipeline. But how do they function in practice?
Continuous Instrumentation of the Linux Scheduler To ensure the reliability of our workloads that depend on low latency responses, we instrumented the run queue latency for each container, which measures the time processes spend in the scheduling queue before being dispatched to the CPU.
To ensure high standards, it’s essential that your organization establish automated validations in an early phase of the software development process—ideally when code is written. While the first guardian validates the traffic, the second guardian checks the business transactions generated during the observation period.
More than half of CIOs confirmed that they often make tradeoffs among code quality, security, and reliability to meet the need for rapid software delivery. Note : you might hear the term latency used instead of response time. Both latency and response time are critical to ensure reliability. The Apdex score of 0.85
First, it helps to understand that applications and all the services and infrastructure that support them generate telemetry data based on traffic from real users. Latency is the time that it takes a request to be served. So how can teams start implementing SLOs? This telemetry data serves as the basis for establishing meaningful SLOs.
On the Android team, while most of our time is spent working on the app, we are also responsible for maintaining this backend that our app communicates with, and its orchestration code. Image taken from a previously published blog post As you can see, our code was just a part (#2 in the diagram) of this monolithic service.
SREs use Service-Level Indicators (SLI) to see the complete picture of service availability, latency, performance, and capacity across various systems, especially revenue-critical systems. While this empowers teams to frequently deliver new features, the overall business, security, and quality objectives must be maintained.
At the lowest level, SLIs provide a view of service availability, latency, performance, and capacity across systems. Automation also enables tools to move into developers’ hands so they can make decisions about deploying code without needing to involve operations teams.
Dynatrace Configuration as Code enables complete automation of the Dynatrace platform’s configuration, ensuring that software is secure and reliable. With Configuration as Code, developers can manage their observability and security tasks with config files that can be developed alongside source code conveniently and at scale.
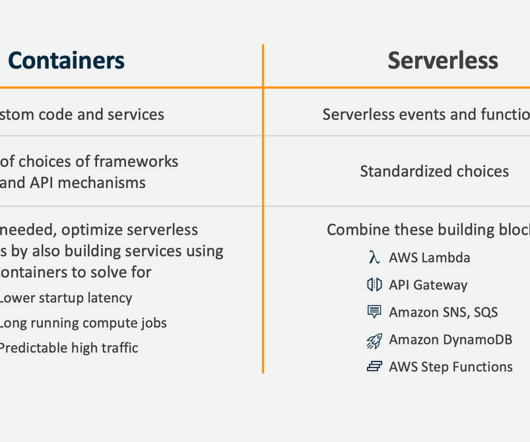
For example, to handle traffic spikes and pay only for what they use. Scale automatically based on the demand and traffic patterns. Higher latency and cold start issues due to the initialization time of the functions. and GoLang to reduce the necessary boilerplate code to a minimum.
Many cloud providers offer a shared security model of data security and compliance in which the cloud provider bears the responsibility for securing the underlying infrastructure, and the customer is responsible for the security of their data, code, and related workloads. For example, as traffic increases, costs will too.
MQTT is an OASIS standard messaging protocol for the Internet of Things (IoT) and was designed as a highly lightweight yet reliable publish/subscribe messaging transport that is ideal for connecting remote devices with a small code footprint and minimal network bandwidth.
More than half of CIOs confirmed that they often make tradeoffs among code quality, security, and reliability to meet the need for rapid software delivery. Note : you might hear the term latency used instead of response time. Both latency and response time are critical to ensure reliability. The Apdex score of 0.85
This architecture shift greatly reduced the processing latency and increased system resiliency. We expanded pipeline support to serve our studio/content-development use cases, which had different latency and resiliency requirements as compared to the traditional streaming use case. This testing stage took about two weeks.
Leveraging code-level insights and transaction analysis, teams can detect and thwart malicious activity. It detects regressions and deviations from previously observed behavior, including latency, traffic, error rates, saturation, security coverage, vulnerability risk levels, and memory consumption.
We also highlight interesting broader events such as regional traffic evacuations and nearby deployments , information that is vital to understanding health holistically. Regional traffic evacuations. For example, a latency increase is less critical than error rate increase and some error codes are less critical than others.
For example, consider an e-commerce website that automatically sends personalized discount codes to customers who abandon their shopping carts. This event-driven automation triggers the action of sending the discount code only when the customer abandons the cart abandonment, minimizing revenue loss and increasing conversion rates.
However, this method limited us to instrumenting the code manually and collecting specific sets of data we defined upfront. The other sections on that page (such as Disk analysis) provide further information and charts on topics such as available disk space, latency, dropped network packets, refused connections, and more.
In order for a service to talk to another, it needs to know two things: the name of the destination service, and whether or not the traffic should be secure. The ability to run in a degraded but available state during an outage is still a marked improvement over completely stopping traffic flow.
Then they tried to scale it to cope with high traffic and discovered that some of the state transitions in their step functions were too frequent, and they had some overly chatty calls between AWS lambda functions and S3. When you are exploring how to construct something, building a prototype in a few days or weeks is a good approach.
There is no code or configuration change necessary to capture data and detect existing services. Resource consumption & traffic analysis. What is the network traffic going to be between services we migrate and those that have to stay in the current data center? Step 3: Detailed Traffic Dependency Analysis.
In this fast-paced ecosystem, two vital elements determine the efficiency of this traffic: latency and throughput. LATENCY: THE WAITING GAME Latency is like the time you spend waiting in line at your local coffee shop. All these moments combined represent latency – the time it takes for your order to reach your hands.
Developers rely on the functionality of the relational database (not the application code) to enforce the schema and preserve the referential integrity of the data within the database. The purpose of DynamoDB is to provide consistent single-digit millisecond latency for any scale of workloads.
Nonetheless, we found a number of limitations that could not satisfy our requirements e.g. stalling the processing of log events until a dump is complete, missing ability to trigger dumps on demand, or implementations that block write traffic by using table locks. Blocking write traffic by locking tables. Writing events to any output.
Nonetheless, we found a number of limitations that could not satisfy our requirements e.g. stalling the processing of log events until a dump is complete, missing ability to trigger dumps on demand, or implementations that block write traffic by using table locks. Blocking write traffic by locking tables. Writing events to any output.
Key Takeaways Critical performance indicators such as latency, CPU usage, memory utilization, hit rate, and number of connected clients/slaves/evictions must be monitored to maintain Redis’s high throughput and low latency capabilities. <code> 127.0.0.1:6379> cmdstat_append:calls=797,usec=4480,usec_per_call=5.62
This approach often leads to heavyweight high-latency analytical processes and poor applicability to realtime use cases. This process is illustrated in the following code snippet: class LinearCounter { BitSet mask = new BitSet(m) // m is a design parameter void add(value) { int position = hash(value) // map the value to the range 0.m
Server-generated assets, since client-side generation would require the retrieval of many individual images, which would increase latency and time-to-render. To reduce latency, assets should be generated in an offline fashion and not in real time. First, the fields can be coded by hand.
There is no way to model how much more traffic you can send to that system before it exceeds it’s SLA. Every opportunity for delay due to more work than the best case or more time waiting than the best case increases the latency and they all add up and create a long tail. Mu is the mean of each component, the latency.
Applications are packaged into a single, lightweight container with their dependencies, typically including the application’s code, customizations, libraries, and runtime environment. Applications can be horizontally scaled with Kubernetes by adding or deleting containers based on resource allocation and incoming traffic demands.
Normally this solution requires a full code redesign and could be quite difficult to achieve when it is injected after the initial code architecture definition. As illustrated above, ProxySQL allows us to set up a common entry point for the application and then redirect the traffic on the base of identified sharding keys.
A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. Since instances of both CentOS and Ubuntu were running in parallel, I could collect flame graphs at the same time (same time-of-day traffic mix) and compare them side by side. But I'm not completely sure. in total.
In such a situation I’d expect to see unusually high latencies, but normal throughput). I was only partially right (there is a steady-state queue involved)… Plus, although it’s not described, the performance degradation observed in this case would almost certainly be poor latency and poor throughput. Hence convoys will occur.
Monitoring of page load time, page length, response time, and request code can also be observed with the traditional HTTP monitoring. Network latency. Network Latency. Network latency can be affected due to. It’s very common for a website to have an increase in traffic after a marketing campaign. Wi-Fi usage.
That was until we went to production with our highest traffic customer. It can be hosted on a CDN like Vercel or Netlify, which results in lower latency. The code you write visualizes instantly in your browser and productivity goes through the sky. Lint And Format Your Code. Challenges. Developing with Next.js
For vertical scaling, Memcached allows augmenting existing servers with additional CPU cores and memory, thereby enhancing the capacity of the caching pool to manage higher traffic volumes and larger data loads. Redis and Memcached offer user-friendly interfaces that can seamlessly integrate into applications with minimal coding.
Serverless computing can be a huge benefit to organizations that don’t have the necessary resources or teams to manage physical resources, like servers/hardware, and all the maintenance and licensing that goes along with that, allowing them to focus on developing their code and applications. Benefits of a Serverless Model. Scalability.
It increases our visibility and enables us to draw a steady stream of organic (or “free”) traffic to our site. While paid marketing strategies like Google Ads play a part in our approach as well, enhancing our organic traffic remains a major priority. The higher our organic traffic, the more profitable we become as a company.
What makes in-memory computing unique and powerful is its two-fold ability to host fast-changing data in memory and run analytics code within a few milliseconds after new data arrives. Unlike manual or automatic log queries, in-memory computing can continuously run analytics code on all incoming data and instantly find issues.
Meanwhile, on Android, the #2 and #3 sources of web traffic do not respect browser choice. On Android today and early iOS versions, WebViews allow embedders to observe and modify all network traffic (regardless of encryption). However, producing a complete and competitive WebView-based browser requires additional UI and glue code.
Rather than buying racks and racks of servers that need to handle the maximum potential traffic and be idle most of the time, it seems that serverless’ method of paying by compute is proving to be beneficial to the bottom lines of organizations. Writing code for one vendor platform does not make it portable or simple to move elsewhere.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content