This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Did you always want to know more about instrumentation, metrics, and your options for coding with open standards? Are you a Java developer and looking for a working example to get started instrumenting your applications and services?
Code coverage is a software quality metric commonly used during the development process that let’s you determine the degree of code that has been tested (or executed). To achieve optimal code coverage, it is essential that the test implementation (or test suites) tests a majority percent of the implemented code.
The release candidate of OpenTelemetry metrics was announced earlier this year at Kubecon in Valencia, Spain. Since then, organizations have embraced OTLP as an all-in-one protocol for observability signals, including metrics, traces, and logs, which will also gain Dynatrace support in early 2023.
Cloud-native technologies and microservice architectures have shifted technical complexity from the source code of services to the interconnections between services. Deep-code execution details. Dynatrace news. Always-on profiling in transaction context. Upgrade OpenTracing instrumentation with high-fidelity data provided by OneAgent.
Considering all aspects and needs of current enterprise development, it is C++ and Java which outscore the other in terms of speed. So much for my blog title :-) So when these titans are pit against each other in real-time, considering all aspects of memory and execution time — Java is floored. JAVA SOLUTION (Will Be Uploaded Later).
One of these solutions is Micrometer which provides 17+ pre-instrumented JVM-based frameworks for data collection and enables instrumentation code with a vendor-neutral API. Micrometer is used for instrumenting both out-of-the-box and custom metrics from Spring Boot applications. That’s a large amount of data to handle.
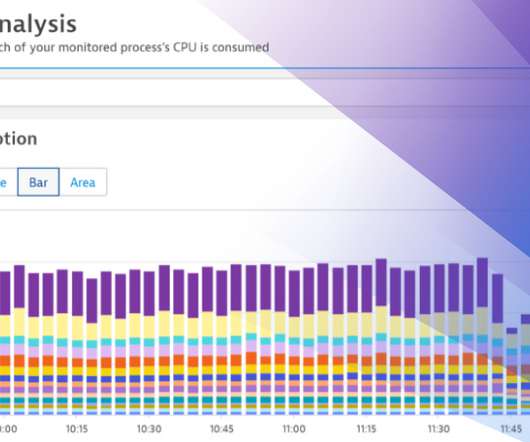
This first step clearly shows that the code that powers getFamilyCondition is using a lot of CPU – much more than any other of the top services combined! It can be your own code, 3 rd party code or your runtime that executes for certain tasks such as Garbage Collection. So – we found the culprit!
That is, relying on metrics, logs, and traces to understand what software is doing and where it’s running into snags. While classic logging is an essential tool in debugging issues, it often lacks context and only provides snapshot information of one specific location in your code/application.
Loosely defined, observability is the ability to understand what’s happening inside a system from the knowledge of the external data it produces, which are usually logs, metrics, and traces. Logs, metrics, and traces make up the bulk of all telemetry data. The data life cycle has multiple steps from start to finish.
To ensure observability, the open source CNCF project OpenTelemetry aims at providing a standardized, vendor-neutral way of pre-instrumenting libraries and platforms and annotating UserLAnd code. New OpenTelemetry metrics exporters provide the broadest language support on the market.
Java Memory Management, with its built-in garbage collection, is one of the language’s finest achievements. However, garbage collection is one of the main sources of performance and scalability issues in any modern Java application. Optimize your code by finding and fixing the root cause of garbage collection problems.
Welcome back to the second part of our blog series on how easy it is to get enterprise-grade observability at scale in Dynatrace for your OpenTelemetry custom metrics. In Part 1 , we announced our new OpenTelemetry custom-metric exporters that provide the broadest language coverage on the market, including Go , .NET record(value); }.
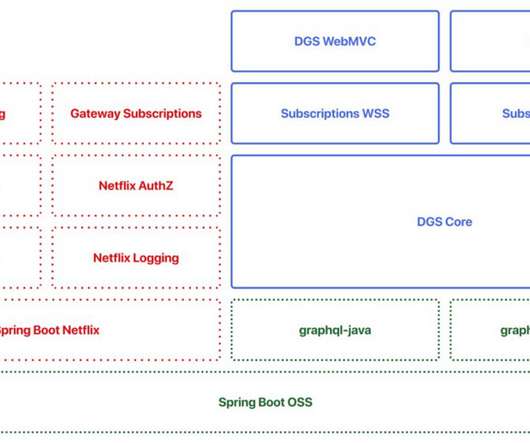
By open-sourcing the project, we hope to contribute to the Java and GraphQL communities and learn from and collaborate with everyone who will be using the framework to make it even better in the future. The transition to the new federated architecture meant that many of our backend teams needed to adopt GraphQL in our Java ecosystem.
For this blog post I want to focus on how you can leverage Dynatrace to get a lot of insight into your plugin code. Part 1 – The code as it stood. The Juniper plugin is an ActiveGate Plugin written in Python, it consists of a script that connects to a Juniper Networks device and collects some facts and metrics about it.
focused on technology coverage, building on the flexibility of JMX for Java and Python-based coded extensions for everything else. While Python code can address most data acquisition and ingest requirements, it comes at the cost of complexity in implementation and use-case modeling. Comprehensive metrics support Extensions 2.0
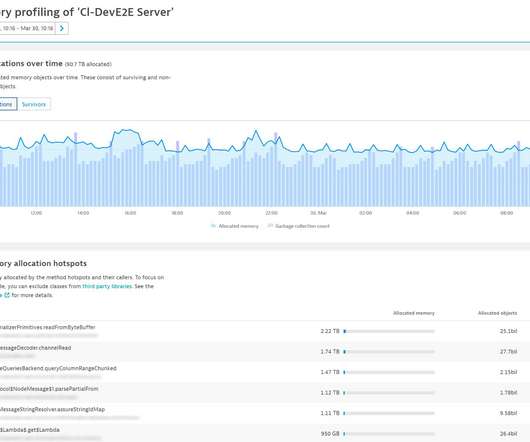
While memory allocation analysis can show wasteful or inefficient code, it can also reveal different problems, one of which we’ll examine in this blog post. We recently extended the pre-shipped code-level API definitions to group logical parts of our code so they’re consistently highlighted in all code-level views.
The Dynatrace ® unified observability and security platform addresses the needs of enterprise-edge scenarios by managing the health and performance of containerized applications and multi-cloud infrastructures with metrics, traces, and logs in one place. The following illustrations outline a typical Red Hat Device Edge and Dynatrace setup.
Fully automated code-level visibility. Apart from its best-in-class observability capabilities like distributed traces, metrics, and logs, Dynatrace OneAgent additionally provides automatic deep code-level insights for Java,NET, Node.js, PHP, and Golang, without the need to change any application code or configuration.
Manual and configuration-heavy approaches to putting telemetry data into context and connecting metrics, traces, and logs simply don’t scale. With PurePath ® distributed tracing and analysis technology at the code level, Dynatrace already provides the deepest possible insights into every transaction. How to get started.
Managing Auto-Instrumentation in Pods The Operator automatically injects and configures auto-instrumentation for your applications, which enables you to collect telemetry data without modifying your source code. Instrumentation Instrumentation is the process of adding code to software to generate telemetry signalslogs, metrics, and traces.
This means, you don’t need to change even a single line of code in the serverless functions themselves. Full integration with existing Dynatrace capabilities for AWS Lambda (for example, metric ingestion via AWS Cloud Watch). In upcoming sprints, additional improvements will include: Support for Java-based functions.
Dynatrace has offered a Lambda code module for Node.js This has led to the recent release of our new Lambda monitoring extension supporting Node.js, Java, and Python. In theory, an existing code module or agent can be used to monitor a Lambda function if there’s a way to load it into the running Lambda process.
OpenTelemetry has become a standard for collecting traces, metrics, and logs. Given the prevalence of Python in AI model development, OpenTelemetry serves as a robust standard for collecting observability data, including traces, metrics, and logs. Maintained under the Apache 2.0 However, Python models are trickier.
In the first part, I've introduced Cyclomatic Complexity ( CYC ) metrics in the previous part. So CYC has no intention to be a readability codemetric. Cognitive Complexity Metric. Cognitive Complexity (CC) attempts to count the cognitive effort required to understand the code's flow.
One of these solutions is Micrometer which provides 17+ pre-instrumented JVM-based frameworks for data collection and enables instrumentation code with a vendor-neutral API. Micrometer is used for instrumenting both out-of-the-box and custom metrics from Spring Boot applications. That’s a large amount of data to handle.
One of these solutions is Micrometer which provides 17+ pre-instrumented JVM-based frameworks for data collection and enables instrumentation code with a vendor-neutral API. Micrometer is used for instrumenting both out-of-the-box and custom metrics from Spring Boot applications. That’s a large amount of data to handle.
We decided to move one of our Java microservices?—?let’s We turned to JVM-specific profiling, starting with the basic hotspot stats, and then switching to more detailed JFR (Java Flight Recorder) captures to compare the distribution of the events. The problem It started off as a routine migration. let’s call it GS2?—?to
To emit a run queue latency metric, we leveraged three eBPF hooks: sched_wakeup, sched_wakeup_new, and sched_switch. When a cgroup ID correlates with a container, we emit a percentile timer Atlas metric (runq.latency) for that container. ' They let us identify when a process is ready to run and is waiting for CPU time.
Spring also introduced Micrometer, a vendor-agnostic metric API with rich instrumentation options. Soon after, Dynatrace built a registry for exporting Micrometer metrics. Our data APIs, which ingest millions of metrics, traces, and logs per second, are reconciled using Micrometer-based metrics.
Observability Observability is the ability to determine a system’s health by analyzing the data it generates, such as logs, metrics, and traces. There are three main types of telemetry data: Metrics. Metrics are typically aggregated and stored in time series databases for monitoring and alerting purposes.
When an incident occurs, developers need to know what data to look at, where the incident occurred, and other relevant metrics. But developers need code-level visibility and code-level data.” That’s not how I envision code-level observability,” Laifenfeld said. KubeCon North America is this week.
Dynatrace monitors your full stack and offers you thousands of metrics with almost zero configuration. Just a single OneAgent per host is required to collect all relevant monitoring data, all the way down to specific lines of code. This article we help distinguish between process metrics, external metrics and PurePaths (traces).
It affects only those extensions that use native libraries called from Python code distributed with the extension. Symptoms : Metrics provided by affected extensions may stop working, such that no data is provided for affected metrics on dashboards, alerts, and custom device pages populated by the affected extension metrics.
In particular, the following capabilities are included in this release of OneAgent for Linux on Z platform: Deep-code monitoring. OneAgent for IBM Z platform comes with several deep-code monitoring modules: Java, Apache/IHS, and IIB/MQ (read more about this announcement in our blog post about IBM Integration Bus monitoring ).
Open source code, for example, has generated new threat vectors for attackers to exploit. Considering open source software (OSS) libraries now account for more than 70% of most applications’ code base, this threat is not going anywhere anytime soon. Spring4Shell vulnerabilities expose Java Spring Framework apps to exploitation.
On the Android team, while most of our time is spent working on the app, we are also responsible for maintaining this backend that our app communicates with, and its orchestration code. Image taken from a previously published blog post As you can see, our code was just a part (#2 in the diagram) of this monolithic service. Java…Script?
Modernize the application, containerize the application, and refactor the code. Figure 5 shows the service flow of a Java-based application hosted on VMware. A service flow of a Java-based application hosted on VMware. Repurchase. Migrate to SaaS or marketplace products. Migrate to the same architecture in a different location.
I have been using it at my current tour through different conferences ( Devoxx , Confitura ) and meetups, ( Cloud Native , KraQA , Trojmiasto Java UG ) where I’ve promoted keptn. Automated Metric Anomaly Detection. Prometheus is a great open source monitoring solution in the cloud-native space that gives me a lot of metrics.
Making applications observable—relying on metrics, logs, and traces to understand what software is doing and how it’s performing—has become increasingly important as workloads are shifting to multicloud environments. We also introduced our demo app and explained how to define the metrics and traces it uses.
This real-time visibility, as well as proven code-level analysis from cloud to the mainframe, gives enterprises a huge competitive advantage—they can eliminate inefficiencies and consequently, innovate at a faster rate. Easily achieve a cost-effective IBM Z configuration by monitoring relevant infrastructure metrics.
Symptoms : No data is provided for affected metrics on dashboards, alerts, and custom device pages populated by the affected extension metrics. Impact : This issue affects only those extensions that use native libraries called from Python code distributed with the extension. Extension logs display errors. x – 2.12.x.
Cloud-native observability for Google’s fully managed GKE Autopilot clusters demands new methods of gathering metrics, traces, and logs for workloads, pods, and containers to enable better accessibility for operations teams. Managed Kubernetes clusters on GKE Autopilot have gained unprecedented momentum among enterprises.
Users can add the APIs manually to their code to define exactly what needs to be measured and monitored continuously after the code is deployed for maintenance purposes. The reference architecture works with C++,NET, Erlang/Elixir, Go, Java, PHP, Python, Ruby, Rust, and Swift — with support for additional languages to come.
Loosely defined, Observability boils down to inferring the internal health and state of a system by looking at the external data it produces, which most commonly are logs, metrics, and traces. The answer is in the data collection, and more specifically, how the logs, metrics, traces are collected. Java, Python, .Net,
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content