This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The Dynatrace Software Intelligence Platform gives you a complete Infrastructure Monitoring solution for the monitoring of cloud platforms and virtual infrastructure, along with log monitoring and AIOps. Ensure high quality network traffic by tracking DNS requests out-of-the-box. What’s next.
The IT world is rife with jargon — and “as code” is no exception. “As code” means simplifying complex and time-consuming tasks by automating some, or all, of their processes. Today, the composable nature of code enables skilled IT teams to create and customize automated solutions capable of improving efficiency.
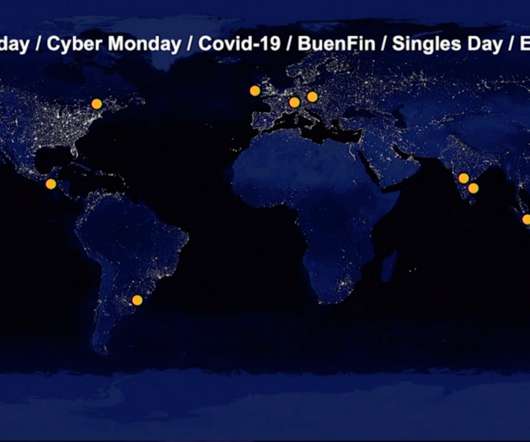
What’s the problem with Black Friday traffic? But that’s difficult when Black Friday traffic brings overwhelming and unpredictable peak loads to retailer websites and exposes the weakest points in a company’s infrastructure, threatening application performance and user experience. These kinds of problems are unacceptable.
Infrastructure as code is a way to automate infrastructure provisioning and management. In this blog, I explore how Dynatrace has made cloud automation attainable—and repeatable—at scale by embracing the principles of infrastructure as code. Infrastructure-as-code. But how does it work in practice?
On average, organizations use 10 different tools to monitor applications, infrastructure, and user experiences across these environments. This enables proactive changes such as resource autoscaling, traffic shifting, or preventative rollbacks of bad code deployment ahead of time.
From business operations to personal communication, the reliance on software and cloud infrastructure is only increasing. Software bugs Software bugs and bad code releases are common culprits behind tech outages. These issues can arise from errors in the code, insufficient testing, or unforeseen interactions among software components.
This modular microservices-based approach to computing decouples applications from the underlying infrastructure to provide greater flexibility and durability, while enabling developers to build and update these applications faster and with less risk. A service mesh can solve these problems, but it can also introduce its own issues.
Think of containers as the packaging for microservices that separate the content from its environment – the underlying operating system and infrastructure. This opens the door to auto-scalable applications, which effortlessly matches the demands of rapidly growing and varying user traffic. What is Docker? Networking.
Central engineering teams enable this operational model by reducing the cognitive burden on innovation teams through solutions related to securing, scaling and strengthening (resilience) the infrastructure. All these micro-services are currently operated in AWS cloud infrastructure.
A unified platform approach to observability and security Dynatrace and its partners offer powerful solutions to complex business resiliency challenges through an observability and security platform that delivers a unified view of applications, infrastructure, and business processes.
This dedicated infrastructure layer is designed to cater to service-to-service communication, offering essential features like load balancing, security, monitoring, and resilience. It comprises a suite of capabilities, such as managing traffic, enabling service discovery, enhancing security, ensuring observability, and fortifying resilience.
Dynatrace Configuration as Code enables complete automation of the Dynatrace platform’s configuration, ensuring that software is secure and reliable. With Configuration as Code, developers can manage their observability and security tasks with config files that can be developed alongside source code conveniently and at scale.
Generally speaking, cloud migration involves moving from on-premises infrastructure to cloud-based services. In cloud computing environments, infrastructure and services are maintained by the cloud vendor, allowing you to focus on how best to serve your customers. However, it can also mean migrating from one cloud to another.
For today’s highly dynamic and exceedingly complex production environments, performance problems that are evident at the service level (for example, slow response times or failed requests) are often the result of underlying (cloud) infrastructure issues. Enrich OpenTelemetry instrumentation with high-fidelity data provided by OneAgent.
To remain competitive in today’s fast-paced market, organizations must not only ensure that their digital infrastructure is functioning optimally but also that software deployments and updates are delivered rapidly and consistently. Ultimately, quality gates safeguard code viability as it advances through the delivery pipeline.
Let’s dive into how these metrics and DevOps KPIs can help your team perform better and deliver better code. Lead time for changes measures the amount of time it takes for committed code to get into production. To gain visibility into this metric, you need to track all defects found in your released code and software.
Organizations are doing their best to monitor what they can, often using disparate tools for logs, infrastructure, and digital experience. The webinar begins with an overview of Kubernetes, emphasizing its popularity and the technical simplicity that underscores the value of infrastructure as code.
More than half of CIOs confirmed that they often make tradeoffs among code quality, security, and reliability to meet the need for rapid software delivery. Traffic This SLO measures the amount of traffic or workload an application receives, either in terms of requests per second or data transfer rate. The Apdex score of 0.85
For example, an organization might use security analytics tools to monitor user behavior and network traffic. Security analytics solutions are designed to handle modern applications that rely on dynamic code and microservices. Infrastructure type In most cases, legacy SIEM tools are on-premises.
For example, to handle traffic spikes and pay only for what they use. These functions are executed by a serverless platform or provider (such as AWS Lambda, Azure Functions or Google Cloud Functions) that manages the underlying infrastructure, scaling and billing. Scale automatically based on the demand and traffic patterns.
According to the 2022 CISO Research Report , only 25% of respondents’ security teams “can access a fully accurate, continuously updated report of every application and code library running in production in real-time.” Undetected, the compromised code could allow attackers to access data they’re not authorized to have.
Although IT teams are thorough in checking their code for any errors, an attacker can always discover a loophole to exploit and damage applications, infrastructure, and critical data. Typically, organizations might experience abnormal scanning activity or an unexpected traffic influx that is coming from one specific client.
Because of its matrix of cloud services across multiple environments, AWS and other multicloud environments can be more difficult to manage and monitor compared with traditional on-premises infrastructure. EC2 is Amazon’s Infrastructure-as-a-service (IaaS) compute platform designed to handle any workload at scale. Amazon EC2.
Today we’re proud to announce the new Dynatrace Operator, designed from the ground up to handle the lifecycle of OneAgent, Kubernetes API monitoring, OneAgent traffic routing, and all future containerized componentry such as the forthcoming extension framework. Dynatrace Operator for OneAgent, API monitoring, routing, and more.
Continuously monitoring application behavior, network traffic, and system logs allows teams to identify abnormal or suspicious activities that could indicate a security breach. During the development stage, vulnerabilities can arise when developers use third-party open-source code or make an error in application logic.
An easy, though imprecise, way of thinking about Netflix infrastructure is that everything that happens before you press Play on your remote control (e.g., Various software systems are needed to design, build, and operate this CDN infrastructure, and a significant number of them are written in Python. are you logged in?
On the Android team, while most of our time is spent working on the app, we are also responsible for maintaining this backend that our app communicates with, and its orchestration code. Image taken from a previously published blog post As you can see, our code was just a part (#2 in the diagram) of this monolithic service.
How site reliability engineering affects organizations’ bottom line SRE applies the disciplines of software engineering to infrastructure management, both on-premises and in the cloud. There are now many more applications, tools, and infrastructure variables that impact an application’s performance and availability.
Automatically identify connection leaks in your application code. Automatically identify connection leaks in your application code. A traffic spike can be another root cause (for example, if a new marketing promotion drives lots of new customer traffic to your site). Automatically detect undersized connection pools.
Dynatrace Synthetic Monitoring helps you quickly verify if your application is delivering the expected end user experience by offering an outside-in view of all your applications and services, independent of real traffic. You have full control over each request and can configure HTTP headers, valid status codes, as well response validation.
The key information displayed on the standard Dynatrace Problems app and the Infrastructure and Operations App became the basis of their team’s remediation plan. The problem card helped them identify the affected application and actions, as well as the expected traffic during that period.
DevOps monitoring is an observability practice that creates a real-time view of the status of applications, services, and infrastructure in pre-production and production environments. The process involves monitoring various components of the software delivery pipeline, including applications, infrastructure, networks, and databases.
All-traffic monitoring, analysis on demand—network performance management started to grow as an independent engineering discipline. Real-time network performance analysis capabilities, including SSL decryption, enabled precise reconstruction of end user application states through the analysis of network traffic.
Just copy and paste your code, make changes to the “green” version, and deploy “green” alongside “blue.” A “deployment” no longer means a “release” Using feature flags, “deploying” code no longer means “releasing code to end users.” After all, if you know that by default, no one gets the new code, your deployment is safe.
This is due to a number of factors, including the rise of cloud infrastructure, automation, and an abundance of prebuilt open-source libraries and third-party/supply-chain products. Traffic lights on a busy stretch of road could go dark. Ensuring secure applications amid rising complexity is a crucial part of this journey.
The first step is determining whether the problem originates from the application or the underlying infrastructure. Learn how Linux kernel instrumentation can improve your infrastructure observability with deeper insights and enhanced monitoring. One issue that often complicates this process is the "noisy neighbor" problem.
Do we have the ability (process, frameworks, tooling) to quickly deploy new services and underlying IT infrastructure and if we do, do we know that we are not disrupting our end users? Dynatrace as a managed AWS workload, and as an option, have the network traffic to Dynatrace run over PrivateLink so that traffic never leaves AWS.
At Dynatrace, where we provide a software intelligence platform for hybrid environments (from infrastructure to cloud) we see a growing need to measure how mainframe architecture and the services running on it contribute to the overall performance and availability of applications. Full-stack and cloud-infrastructure monitoring modes.
Infrastructure Optimization: 100% improvement in Database Connectivity. In most cases, I’ve seen it’s either through bad coding, incorrect use of data access frameworks, or simply architecture that has grown over the years into something that became overly complex in terms of participating components and services.
For example, consider an e-commerce website that automatically sends personalized discount codes to customers who abandon their shopping carts. This event-driven automation triggers the action of sending the discount code only when the customer abandons the cart abandonment, minimizing revenue loss and increasing conversion rates.
But its underlying goal is quite humble and straightforward: it wants to enable you to observe an IT system (for example, a web application, infrastructure, or services) and gain insight to its behavior, such as performance, error rates, hot spots of executed instructions in code, and more.
That’s tremendous, especially when you see four of the six hours were introduced by customer code,” said Auer. First, he pointed to the infrastructure monitoring capabilities as critical to understanding the impact of hardware failures. You can see the traffic reaching each milestone of an online shopping journey.
Solving custom API observability with OpenTelemetry Because the bank group needed complete coverage for all API traffic, it wanted to standardize tracing on all API calls. They also wanted to normalize trace data from their custom APIs to simplify ingestion and provide complete end-to-end visibility.
That’s why we added to Dynatrace AutomationEngine , to run workflows, or use code to automate,” Greifeneder explained. “It With this process, DevOps teams can identify whether code includes a high-priority bug that has to be fixed immediately. Both are possible, tied to business or technical value–It’s all there,” he said.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content