This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Infrastructure as code is a way to automate infrastructure provisioning and management. In this blog, I explore how Dynatrace has made cloud automation attainable—and repeatable—at scale by embracing the principles of infrastructure as code. Transparency and scalability. Infrastructure-as-code.
But to be scalable, they also need low-code/no-code solutions that don’t require a lot of spin-up or engineering expertise. And operations teams need to forecast cloud infrastructure and compute resource requirements, then automatically provision resources to optimize digital customer experiences.
To solve this problem , Dynatrace offers a fully automated approach to infrastructure and application observability including Kubernetes control plane, deployments, pods, nodes, and a wide array of cloud-native technologies. None of this complexity is exposed to application and infrastructure teams.
HashiCorp’s Terraform is an open-source infrastructure as a code software tool that provides a consistent CLI workflow to manage hundreds of cloud services. Per HashiCorp, this codification allows infrastructure changes to be automated while keeping the definition human readable. What is monitoring as code?
One of the promises of container orchestration platforms is to make i t easier for the developers to accelerate the deployment of their app lication s without having to worry about scalability and infrastructure dependencies. If nodes run out of resources, Kubernetes may start killing pods or throttle applications.
In the coming weeks and months, we will add to the current collection of templates for synthetic monitoring, digital experience management measures, Kubernetes resource optimization, and infrastructure monitoring. At the same time, dedicated configuration-as-code support in Monaco and Terraform will provide a scalable, automated solution.
Site reliability engineering (SRE) plays a vital role in ensuring Java applications' high availability, performance, and scalability. This discipline merges software engineering and operations, aiming to create a robust infrastructure that supports seamless user experiences.
Data engineering projects often require the setup and management of complex infrastructures that support data processing, storage, and analysis. IaC enables treating infrastructure setups as version-controlled code, allowing for automated provisioning, deployment, and configuration management.
Central engineering teams enable this operational model by reducing the cognitive burden on innovation teams through solutions related to securing, scaling and strengthening (resilience) the infrastructure. All these micro-services are currently operated in AWS cloud infrastructure.
IT infrastructure is the heart of your digital business and connects every area – physical and virtual servers, storage, databases, networks, cloud services. We’ve seen the IT infrastructure landscape evolve rapidly over the past few years. What is infrastructure monitoring? . Dynatrace news.
However, this category requires near-immediate access to the current count at low latencies, all while keeping infrastructure costs to a minimum. Eventually Consistent : This category needs accurate and durable counts, and is willing to tolerate a slight delay in accuracy and a slightly higher infrastructure cost as a trade-off.
that offers security, scalability, and simplicity of use. focused on technology coverage, building on the flexibility of JMX for Java and Python-based coded extensions for everything else. Python code also carries limited scalability and the burden of governing its security in production environments and lifecycle management.
The scalability, agility, and continuous delivery offered by microservices architecture make it a popular option for businesses today. Various factors, such as network communication, inter-service dependencies, external dependencies, and scalability issues, can contribute to outages.
As a popular open-source MQTT broker, EMQX provides high scalability, reliability, and security for MQTT messaging. By using Terraform, a widespread Infrastructure as Code (IaC) tool, you can automate the deployment of EMQX MQTT Broker on AWS, making it easy to set up and manage your MQTT infrastructure.
The containerization craze has continued for enterprises, with benefits such as portability, efficiency, and scalability. Because container as a service doesn’t rely on a single code language or code stack, it’s platform agnostic. Easy scalability. million in 2020. The classes of CaaS. Process portability.
The development of internal platform teams has taken off in the last three years, primarily in response to the challenges inherent in scaling modern, containerized IT infrastructures. The old saying in the software development community, “You build it, you run it,” no longer works as a scalable approach in the modern cloud-native world.
Serverless architecture is a way of building and running applications without the need to manage infrastructure. You write your code, and the cloud provider handles the rest - provisioning, scaling, and maintenance. Scalability: Serverless services automatically scale with the application's needs.
In these modern environments, every hardware, software, and cloud infrastructure component and every container, open-source tool, and microservice generates records of every activity. Metrics can originate from a variety of sources, including infrastructure, hosts, services, cloud platforms, and external sources.
From business operations to personal communication, the reliance on software and cloud infrastructure is only increasing. Software bugs Software bugs and bad code releases are common culprits behind tech outages. These issues can arise from errors in the code, insufficient testing, or unforeseen interactions among software components.
If you're tired of managing your infrastructure manually, ArgoCD is the perfect tool to streamline your processes and ensure your services are always in sync with your source code. Say goodbye to the headaches of manual infrastructure management and hello to a more efficient and scalable approach with ArgoCD!
These methods improve the software development lifecycle (SDLC), but what if infrastructure deployment and management could also benefit? Development teams use GitOps to specify their infrastructure requirements in code. Known as infrastructure as code (IaC), it can build out infrastructure automatically to scale.
Before an organization moves to function as a service, it’s important to understand how it works, its benefits and challenges, its effect on scalability, and why cloud-native observability is essential for attaining peak performance. Infrastructure as a service (IaaS) handles compute, storage, and network resources. What is FaaS?
With growing multicloud complexity and the need for organization-wide scalability, self-service and automation capabilities have become increasingly essential for developer productivity. A platform encompasses a set of tools, services, and infrastructure that enables developers to build, test, and deploy software applications.
Instead of worrying about infrastructure management functions, such as capacity provisioning and hardware maintenance, teams can focus on application design, deployment, and delivery. Scalability. Finally, there’s scalability. Why use a serverless architecture? Simplicity. The first benefit is simplicity.
In many ways, the shift to cloud computing and the adoption of cloud-native architectures have enabled organizations to realize greater resiliency alongside scalability. By integrating with continuous integration and continuous delivery (CI/CD) pipelines, Dynatrace helps ensure that only high-quality code reaches production.
Many organizations today rely on cloud-native applications for their scalability and agility, among other benefits. Serverless benefits include the following: Dynamic scalability. Code development also benefits from a serverless approach. No infrastructure to maintain. However, not all cloud strategies are the same.
34% of CIOs say they sacrifice code security to deliver innovation quicker. Dynatrace provides powerful AI-based observability, putting all your infrastructure, applications, and events in context. 249% increase in code base coverage on average. reduction in critical severity vulnerabilities for enterprise customers.
For AWS Lambda, the largest contributor to startup latency is the time spent initializing an execution environment, which includes loading function code and initializing dependencies. With SnapStart enabled, function code is initialized once when a function version is published. Built for enterprise scalability. What is Lambda?
As a popular open-source MQTT broker, EMQX provides high scalability, reliability, and security for MQTT messaging. By using Terraform, a widespread Infrastructure as Code (IaC) tool, you can automate the deployment of EMQX MQTT Broker on Azure, making it easy to set up and manage your MQTT infrastructure.
Dynatrace Configuration as Code enables complete automation of the Dynatrace platform’s configuration, ensuring that software is secure and reliable. With Configuration as Code, developers can manage their observability and security tasks with config files that can be developed alongside source code conveniently and at scale.
Think of containers as the packaging for microservices that separate the content from its environment – the underlying operating system and infrastructure. This opens the door to auto-scalable applications, which effortlessly matches the demands of rapidly growing and varying user traffic. What is Docker? Here are some examples.
matthew_d_green : I spent the year before Heartbleed visiting important people in DC trying to convince them OpenSSL was a mess, and they should fund it as “critical infrastructure” They laughed and told me that term referred to dams and power plants. So many more quotes.
To do so we have successfully established AI-based White box load and resiliency testing with JMeter and Dynatrace, helping identify and resolve major performance and scalability problems in recent projects before deploying to production. Each step is automated from provisioning infrastructure to problem analysis.
As someone who has worked deep in the coding trenches with developers my whole life, I’ve hand-picked the top three mistakes you can make when moving to Kubernetes. Kubernetes was made for the Configuration as Code paradigm, and all those YAML files belong in a Git repo. Easy scalability. Using GitOps tools such as Flux.
Operational Efficiency: The majority of the changes require metadata configuration files and library code changes, usually taking days of testing and service release to adopt the updates. Besides, the mixed-use of the metadata files and business logic code adds another layer of maintenance complexity.
IT operations, application, infrastructure, and development teams all look to the topic of observability as the silver bullet to solve their problems. Neglecting the front-end perspective potentially skews or even misrepresents the understanding of how your applications and infrastructure are performing in the real world, to real users.
Advanced observability can eliminate blind spots surrounding application performance, health, and behavior for these critical applications and the infrastructure that supports them. Infrastructure monitoring automatically analyzes key health metrics and discovers performance problems caused by infrastructure bottlenecks or changes.
GKE Autopilot empowers organizations to invest in creating elegant digital experiences for their customers in lieu of expensive infrastructure management. Dynatrace’s collaboration with Google addresses these needs by providing simple, scalable, and innovative data acquisition for comprehensive analysis and troubleshooting.
Dynatrace has been building automated application instrumentation—without the need to modify source code—for over 15 years already. Driving the implementation of higher-level APIs—also called “typed spans”—to simplify the implementation of semantically strong tracing code. What are the benefits of the Dynatrace contribution?
Generally speaking, cloud migration involves moving from on-premises infrastructure to cloud-based services. In cloud computing environments, infrastructure and services are maintained by the cloud vendor, allowing you to focus on how best to serve your customers. Increased scalability. Benefits of migrating to the cloud.
Based on IDC’s research, 83% of enterprises are rationalizing, or optimizing, their technology infrastructure. According to IBM , application modernization takes existing legacy applications and modernizes their platform infrastructure, internal architecture, or features. What is application modernization?
Because of its matrix of cloud services across multiple environments, AWS and other multicloud environments can be more difficult to manage and monitor compared with traditional on-premises infrastructure. EC2 is Amazon’s Infrastructure-as-a-service (IaaS) compute platform designed to handle any workload at scale. Amazon EC2.
Observability of applications and infrastructure serves as a critical foundation for DevOps and platform engineering, offering a comprehensive view into system performance and behavior. AI-driven insights optimize resource allocation, bolster internal developer platform scalability, and introduce autonomous operations for platform engineers.
Federal Register : In this final rule, the Librarian of Congress adopts exemptions to the provision of the Digital Millennium Copyright Act (“DMCA”) that prohibits circumvention of technological measures that control access to copyrighted works, codified in the United States Code. A lot more quotes async and await you.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































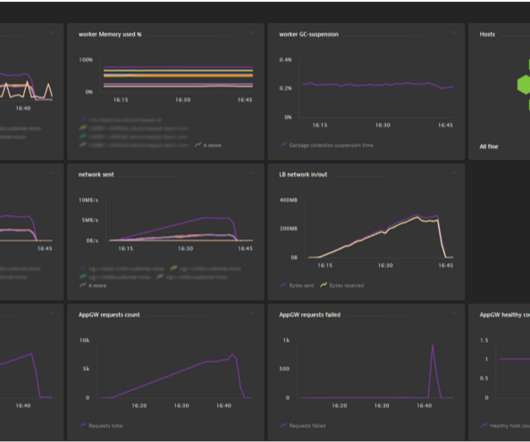
















Let's personalize your content