This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
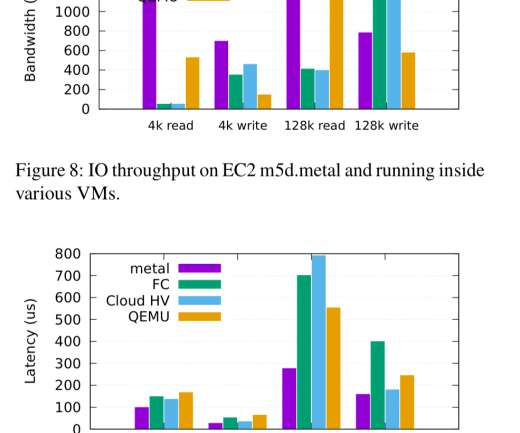
While we understand it’s virtually impossible to achieve a linear increase in throughput as the number of vCPUs grow, a near-linear increase is attainable. Drilling down into “hot” methods and further into the assembly code showed us blocks of code with some instructions exceeding 100 CPI, which is extremely slow.
Microsoft Hyper-V is a virtualization platform that manages virtual machines (VMs) on Windows-based systems. It enables multiple operating systems to run simultaneously on the same physical hardware and integrates closely with Windows-hosted services. This leads to a more efficient and streamlined experience for users.
Infrastructure as code is a way to automate infrastructure provisioning and management. In this blog, I explore how Dynatrace has made cloud automation attainable—and repeatable—at scale by embracing the principles of infrastructure as code. Infrastructure-as-code. In response, Dynatrace introduced Monaco (Monitoring-as-code).
Because container as a service doesn’t rely on a single code language or code stack, it’s platform agnostic. The emergence of Docker and other container services enabled companies to transport code quickly and easily. Instead, enterprises manage individual containers on virtual machines (VMs). CaaS vs. PaaS.
Traditional computing models rely on virtual or physical machines, where each instance includes a complete operating system, CPU cycles, and memory. VMware commercialized the idea of virtual machines, and cloud providers embraced the same concept with services like Amazon EC2, Google Compute, and Azure virtual machines.
They use the same hardware, APIs, tools, and management controls for both the public and private clouds. Amazon Web Services (AWS) Outpost : This offering provides pre-configured hardware and software for customers to run native AWS computing, networking, and services on-premises in a cloud-native manner.
Firecracker is the virtual machine monitor (VMM) that powers AWS Lambda and AWS Fargate, and has been used in production at AWS since 2018. The traditional view is that there is a choice between virtualization with strong security and high overhead, and container technologies with weaker security and minimal overhead.
Function as a service is a cloud computing model that runs code in small modular pieces, or microservices. Cloud providers then manage physical hardware, virtual machines, and web server software management. What is FaaS? FaaS enables developers to create and run a single function in the cloud using a serverless compute model.
Organizations hit this cloud operations wall when replacing static virtual machines with dynamic container orchestration and expanding to multicloud environments. While modern cloud systems simplify tasks — such as deploying apps and provisioning new hardware and servers — cloud environments can be surprisingly complex.
There is no code or configuration change necessary to capture data and detect existing services. Lift & Shift is where you basically just move physical or virtual hosts to the cloud – essentially you just run your host on somebody else’s hardware. For that, it is sufficient to only know host-2-host dependencies.
Then there was the need for separate dev, QA, and production runtime environments, each of which called for their own hardware. One person forcing a hasty code change could upset operations and lead to sizable losses. Since application development and AI both involve writing code, they overestimate the overlap between the two.
Thread dumps allow Java developers to understand which threads execute which code and whether or not certain threads are waiting or locked. A scalable architecture needs to distribute work across many threads in order to facilitate all the CPUs of a physical or virtual machine. At this point, you might want to know the root cause.
On May 8, OReilly Media will be hosting Coding with AI: The End of Software Development as We Know It a live virtual tech conference spotlighting how AI is already supercharging developers, boosting productivity, and providing real value to their organizations. Claude 3.7, and Alibabas QwQ). Machines cant.
On May 8, OReilly Media will be hosting Coding with AI: The End of Software Development as We Know It a live virtual tech conference spotlighting how AI is already supercharging developers, boosting productivity, and providing real value to their organizations. Much of the code ChatGPT was trained on implemented those dark patterns.
When it comes to hardware support to mitigate software security issues, there is a significant gap between what is available in products today and known solutions. Acceleration—Adding hardware support to reduce the runtime overheads of security features. hardware support for malware detection/prevention).
Instead of diving in arguing about specific points (which I partly did in my earlier post – start from The Future of Performance Testing if you are interested), I decided to talk to people who monetize on these “myths” So here is a virtual interview with Guillaume Betaillouloux , co-founder and Performance Director of OctoPerf.
Defining high availability In general terms, high availability refers to the continuous operation of a system with little to no interruption to end users in the event of hardware or software failures, power outages, or other disruptions. Without enough infrastructure (physical or virtualized servers, networking, etc.),
EPU: Emotion Processing Unit is designed by Emoshape , as the MCU microchip design to enable a true emotional response in AI, robots and consumer electronic devices as a result of a virtually unlimited cognitive process. HPU: Holographic Processing Unit (HPU) is the specific hardware of Microsoft’s Hololens.
Chatbots and virtual assistants Chatbots and virtual assistants are becoming more common on websites and web applications as they provide an efficient and convenient way for users to interact with a business. Developers can easily share and access code and other resources regardless of their location.
Some of the most important elements include: No single point of failure (SPOF): You must eliminate any SPOF in the database environment, including any potential for an SPOF in physical or virtualhardware. Without enough infrastructure (physical or virtualized servers, networking, etc.), there cannot be high availability.
The main change last week is that the committee decided to postpone supporting contracts on virtual functions; work will continue on that and other extensions. The paper also provides std::observable() as a manual way of adding such a checkpoint in code.
The layers of platforms start at the bottom with hardware choices such as which CPU architectures and vendors you want to use. The virtualization and networking platform could be datacenter based, with something like VMware, or cloud based using one of the cloud providers such as AWS EC2.
CLI tools The Cassandra systems were EC2 virtual machine (Xen) instances. The broken Java stacks turned out to be beneficial: They helped group together the os::javaTimeMillis() calls which otherwise might have have been scattered on top of different Java code paths, appearing as thin stacks everywhere. But I'm not completely sure.
Apart from library code, maybe your application doesn't have frame pointers either, in which case everything is broken. Only in extreme circumstances does the cost (in processor time and I-cache footprint) translate to a tangible benefit - circumstances which usually resort to hand-coded assembly anyway.
Last week we saw the benefits of rethinking memory and pointer models at the hardware level when it came to object storage and compression ( Zippads ). The protections are hardware implemented and cannot be forged in software. code is not given access to excessive capabilities. ASPLOS’19. CHERI implementation.
In order to overcome these issues, the concept of paging and segmentation was introduced, where physical address space and virtual address space were designed. Here, memory is divided into equal sizes of partitions where the code of a program resides. A detailed description of these concepts is below.
That pricing won’t be sustainable, particularly as hardware shortages drive up the cost of building infrastructure. The higher percentage of users that are experimenting may reflect OpenAI’s addition of Advanced Data Analysis (formerly Code Interpreter) to ChatGPT’s repertoire of beta features.
In a recent project comparing systems for MariaDB performance, a user had originally been using a tool called sysbench-tpcc to compare hardware platforms before migrating to HammerDB. This is a brief post to highlight the metrics to use to do the comparison using a separate hardware platform for illustration purposes. hammerdbcli auto./scripts/tcl/maria/tprocc/maria_tprocc_build.tcl
Nowadays, hardware and software are designed to conduct eye-tracking studies for marketing , UX , psychological and medical research , gaming , and several other use cases. Another area that has been showing huge potential is eye-tracking in the context of virtual reality. Source: Nielsen Norman Group ) ( Large preview ).
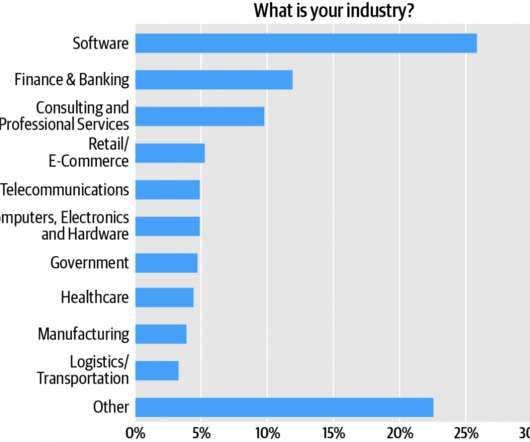
Combined, technology verticals—software, computers/hardware, and telecommunications—account for about 35% of the audience (Figure 2). So it just makes sense to instantiate microservices at the level of the virtual machine (VM), as distinct to that of the container. Figure 2: Respondent industries. Footnotes.
After 20 years of neck-in-neck competition, often starting from common code lineages, there just isn't that much left to wring out of the system. Now in development in WebKit after years of radio silence, WebXR APIs provide Augmented Reality and Virtual Reality input and scene information to web applications. Compression Streams.
Mobiles have different models, screen resolutions, operating systems, network types, hardware configurations, etc. Also, how to test the hardware of the mobile phone itself, is it supporting all the software as it should? Let us have a look at the most popular types of mobile testing for applications and hardware.
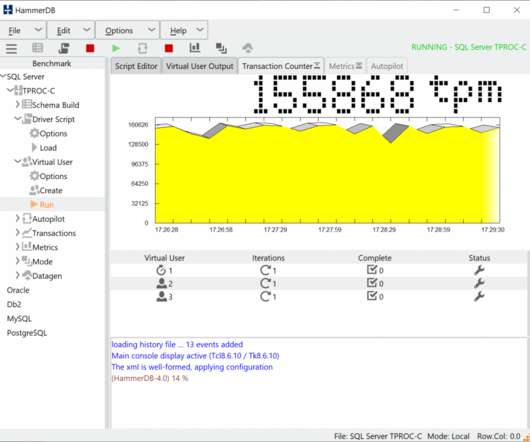
To benchmark a database we introduce the concept of a Virtual User. We could use processes, however given we may want to create hundreds or thousands of virtual users multithreading is the best approach to implement a Virtual User. Basic Benchmarking Concepts. The Python GIL. Tcl Multithreading in parallel.
HA in PostgreSQL databases delivers virtually continuous availability, fault tolerance, and disaster recovery. Also, in general terms, a high availability PostgreSQL solution must cover four key areas: Infrastructure: This is the physical or virtualhardware database systems rely on to run. there cannot be high availability.
halt (); Some sort of very early exception handler; better to sit busy in an infinite loop than run off and destroy hardware or corrupt data, I suppose. Jann Horn gets back to me first: Can you use QEMU to look at the hardware frame (which contains values pushed by the hardware in response to the page fault) in early_idt_handler_common?
These systems can include physical servers, containers, virtual machines, or even a device, or node, that connects and communicates with the network. Software and hardware components are autonomous and execute tasks concurrently. State is distributed through the system. Concurrency. Heterogeneity. Fault Tolerance.
It uses a Solaris Porting Layer (SPL) to provide a Solaris-kernel interface on Linux, so that unmodified ZFS code can execute. There's also a ZFS send/recv code path that should try to use the TASK_INTERRUPTIBLE flag (as suggested by a coworker), to avoid a kernel hang (can't kill -9 the process). LTS (April 2016).
It enables the user to measure database performance and make comparative judgements about database hardware and software. These factors meant that often when looking for database performance information, the results for a particular combination of software and hardware were not available. What is HammerDB? Why HammerDB was developed.
Nowadays, the source code to old operating systems can also be found online. Linux is also hard coding the 1, 5, and 15 minute constants. This state is used by code paths that want to avoid interruptions by signals, which includes tasks blocked on disk I/O and some locks. This, too, was a dead end. They aren't idle.
Before booting a compiled Linux kernel image on actual hardware, it can save us time and potential headache to do a quick boot in a virtual machine like QEMU. 1.144949 ] Hardware name: QEMU Standard PC ( i440FX + PIIX, 1996 ) , BIOS 1.10.2-1ubuntu1 Typically, when we modify a program, we’d like to run it to verify our changes.
A wide range of users with different operating systems, browsers, hardware configurations and other variables provides a wide sample size that helps developers discover as many issues as possible. This helps developers decide when to increase server disk space and power or whether or not using a virtual cloud server is optimal.
Here are the three big directional bets that align with the three main areas cited by the authors: We will train in the cloud , where its possible to take advantage of managed infrastructure well suited to large amounts of data, spiky resource usage, and access to the latest hardware. It was a surprise to me too when that penny dropped.
Exceptions What happens when programming exceptions occur in message processing code? Even with the most robust code possible, exceptions can still happen. Unfortunately it makes ordered delivery virtually impossible to support. For simplicity of the code we'll use two flags. As developers, this is not unfamiliar to us.
Byte-addressable non-volatile memory,) NVM will fundamentally change the way hardware interacts, the way operating systems are designed, and the way applications operate on data. Traditional pointers address a memory location (often virtual of course). At least, the nature of pointers that we want to make persistent.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content