This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
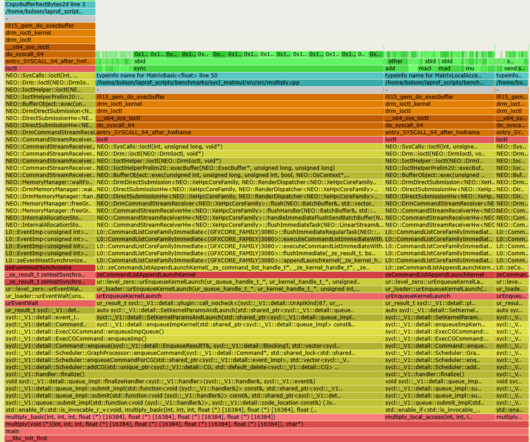
At Intel we've been creating a new analyzer tool to help reduce AI costs called AI Flame Graphs : a visualization that shows an AI accelerator or GPU hardware profile along with the full software stack, based on my CPU flame graphs. The gray "-" frames just help highlight the boundary between CPU and AI/GPU code.
You may also like: How to Properly Plan JVM Performance Tuning. While Performance Tuning an application both Code and Hardware running the code should be accounted for. Reduce the amount of code in critical sections. Thread Contention.
The IBM Z platform is a range of mainframe hardware solutions that are quite frequently used in large computing shops. Typically, these shops run the z/OS operating system, but more recently, it’s not uncommon to see the Z hardware running special versions of Linux distributions. Stay tuned for more announcements on this topic.
This allows teams to sidestep much of the cost and time associated with managing hardware, platforms, and operating systems on-premises, while also gaining the flexibility to scale rapidly and efficiently. Performing updates, installing software, and resolving hardware issues requires up to 17 hours of developer time every week.
This gives you deep visibility into your code running in Azure Functions, and, as a result, an understanding of its impact on overall application performance and user experience. Code-level visibility continues to be supported for.NET-based functions running in an App Service plan. Optimize your code with code-level visibility.
Compare ease of use across compatibility, extensions, tuning, operating systems, languages and support providers. Oracle requires more complex ongoing administration, as all database configurations must evolve in conjunction with the data schemas and custom code. Compare Ease of Use. So Which Is Best?
Container technology is very powerful as small teams can develop and package their application on laptops and then deploy it anywhere into staging or production environments without having to worry about dependencies, configurations, OS, hardware, and so on. The time and effort saved with testing and deployment are a game-changer for DevOps.
The IBM Z platform is a range of mainframe hardware solutions that are quite frequently used in large computing shops. Typically, these shops run the z/OS operating system, but more recently, it’s not uncommon to see the Z hardware running special versions of Linux distributions. Stay tuned for more announcements on this topic.
This gives you deep visibility into your code running in Azure Functions, and, as a result, an understanding of its impact on overall application performance and user experience. Code-level visibility continues to be supported for.NET-based functions running in an App Service plan. Optimize your code with code-level visibility.
This is especially the case with microservices and applications created around multiple tiers, where cheaper hardware alternatives play a significant role in the infrastructure footprint. Here are details of the capabilities included in this release of OneAgent for Linux on the ARM platform: Deep-code monitoring.
Limits of a lift-and-shift approach A traditional lift-and-shift approach, where teams migrate a monolithic application directly onto hardware hosted in the cloud, may seem like the logical first step toward application transformation. Likewise, refactoring and rewriting code takes a lot of time and effort.
The agencies resisted adopting the tool because it required significant time to configure and tune collected metrics into valuable information. The obvious costs of tool sprawl can quickly add up, including licensing, support, maintenance, training, hardware, and often additional headcount. Ultimately, Zbojniewicz has saved $1.4M
Such applications track the inventory of our network gear: what devices, of which models, with which hardware components, located in which sites. One example is the Spectator Python client library, a library for instrumenting code to record dimensional time series metrics. We use Python to help generate TLS certificates using Lemur.
Logs can include data about user inputs, system processes, and hardware states. Log analysis can reveal potential bottlenecks and inefficient configurations so teams can fine-tune system performance. “Logging” is the practice of generating and storing logs for later analysis. Optimized system performance.
In this post, we will discuss some important kernel parameters that can affect database server performance and how these should be tuned. child process exited with exit code 1 Similarly, you can get an error when starting the PostgreSQL server using the pg_ctl command. SHMMAX / SHMALL. Until version 9.2, vm.dirty_ratio / dirty_bytes.
Complementing the hardware is the software on the RAE and in the cloud, and bridging the software on both ends is a bi-directional control plane. When a new hardware device is connected, the Local Registry detects and collects a set of information about it, such as networking information and ESN.
Thread dumps allow Java developers to understand which threads execute which code and whether or not certain threads are waiting or locked. Ideally, all CPUs would execute code all the time and never be idle. More work means more coordination and more locks, which in turn means less code executed at any given time.
Amazon SageMaker training supports powerful container management mechanisms that include spinning up large numbers of containers on different hardware with fast networking and access to the underlying hardware, such as GPUs. This can all be done without touching a single line of code. Post-training model tuning and rich states.
On May 8, OReilly Media will be hosting Coding with AI: The End of Software Development as We Know It a live virtual tech conference spotlighting how AI is already supercharging developers, boosting productivity, and providing real value to their organizations. Claude 3.7, and Alibabas QwQ). Machines cant. AlphaGo doesnt want to play Go.
assigning to a specific CPU) is a manageable resource, represented by the concept of “virtual CPU” as a term that includes CPU cores, hyperthreads, hardware threads, and so forth. Then we need to see IF implementing the tuning will work or not. It is possible to do more tuning in the case that ETL is too compromised.
You can tailor the database to meet your precise requirements by modifying the source code, adding extensions, or customizing configurations. Resource allocation: Personnel, hardware, time, and money The migration to open source requires careful allocation (and knowledge) of the resources available to you. And finally… budgets.
Even with cloud-based foundation models like GPT-4, which eliminate the need to develop your own model or provide your own infrastructure, fine-tuning a model for any particular use case is still a major undertaking. That pricing won’t be sustainable, particularly as hardware shortages drive up the cost of building infrastructure.
The thrust of the argument is that there’s a chain of inter-linked assumptions / dependencies from the hardware all the way to the programming model, and any time you step outside of the mainstream it’s sufficiently hard to get acceptable performance that researchers are discouraged from doing so. a research paper.
” Each step has been a twist on “what if we could write code to interact with a tamper-resistant ledger in real-time?” Doubly so as hardware improved, eating away at the lower end of Hadoop-worthy work. Mental contortions led to code contortions led to frustration. And, often, to giving up.
We built DynamoDB as a fully-managed service because we wanted to enable our customers, both internal and external, to focus on their application rather than being distracted by undifferentiated heavy lifting like dealing with hardware and software maintenance. Expanding the freedom to invent.
0] would be easy to call “obvious” in hindsight, but it’s far from the only option and this paper’s analysis shows a thorough consideration of alternatives, including their effects on existing and future code and future language evolution. Seeing only the end result of T.[0] This is that library. You can check out the diff in these | commits.
<code> 127.0.0.1:6379> cmdstat_command:calls=796,usec=8578,usec_per_call=10.78 </code> Redis groups its various commands into connection, server, cluster, generic, etc. . <code> <code> 127.0.0.1:6379> <code>127.0.0.1:6379> 6379> info stats # Stats.
Once the whole fleet has turned over, the code for the now unused version(s) can be removed. The ability to rapidly deploy new versions of Pony Express significantly aided development and tuning of congestion control. The little engine that could.
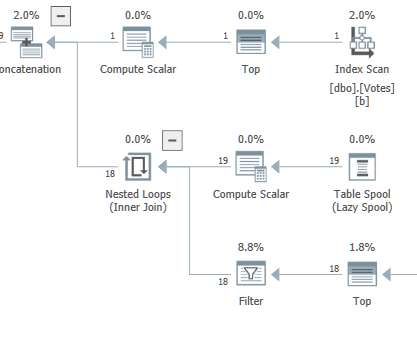
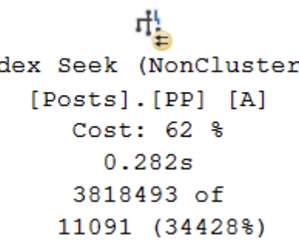
Back in 2014, I wrote an article called Performance Tuning the Whole Query Plan. Implementing the current requirement using that technique is quite straightforward, though the code is necessarily longer than anything we have seen up to this point: WITH R AS. ( The code may be easier to read and understand than the recursive CTE.
The broken Java stacks turned out to be beneficial: They helped group together the os::javaTimeMillis() calls which otherwise might have have been scattered on top of different Java code paths, appearing as thin stacks everywhere. Without NMI, some kernel code paths (interrupts disabled) can't be profiled. But I'm not completely sure.
million lines of C code. That's about the same amount of code you'd find in a high-end smartphone operating system. This allows NASA's engineers to fine-tune every aspect of the rover's behavior, optimizing for reliability rather than rapid development or ease of use. That's essentially what NASA does.
We don’t need to violate any physical laws to increase single-core bandwidth — we just need the design support the very high levels of memory parallelism we need, and provide us with a way of generating that parallelism from application codes. Stay tuned! On a VE20B (8 cores, 1.6
It uses a Solaris Porting Layer (SPL) to provide a Solaris-kernel interface on Linux, so that unmodified ZFS code can execute. There's also a ZFS send/recv code path that should try to use the TASK_INTERRUPTIBLE flag (as suggested by a coworker), to avoid a kernel hang (can't kill -9 the process). LTS (April 2016).
FSD has a sense of purpose, a planning capability, has real time agency and responds to its environment via an ego model, predicting the behavior of pedestrians and other road users, and is being tuned to drive in a very human way, so that other road users interact with it as a predicable normal driver.
Serverless computing can be a huge benefit to organizations that don’t have the necessary resources or teams to manage physical resources, like servers/hardware, and all the maintenance and licensing that goes along with that, allowing them to focus on developing their code and applications. Benefits of a Serverless Model. Scalability.
GHz 4th Generation Intel Xeon Scalable processors (code-named Sapphire Rapids) Up to 20% higher compute performance than z1d instances Up to 50 Gbps of networking speed Up to 40 Gbps of bandwidth to the Amazon Elastic Block Store (EBS) We can also verify these capabilities by running some simple benchmarks on the different subsystems.
Mainstream hardware – many kinds of parallelism: What’s the relationship among multi-core CPUs, hardware threads , SIMD vector units (Intel SSE and AVX , ARM Neon ), and GPGPU (general-purpose computation on GPUs, which I covered at C++ and Beyond 2011 )? This isn’t just cool stuff – it’s important and useful in production code today.
Operations and execution matter to the bottom line, but ultimately dance to the tune called by finance. Virtual data centers, real-time algorithmic pricing, and new media are simply larger versions of that same phenomenon. Production isn't what it used to be.
Not all back-end errors affect the user experience, but keeping track of them can prove helpful when tuning your app. Source: Google Keep in mind that not all code errors are noticeable to users. Back-end error tracking is relatively straightforward since all server-side code runs in the same place.
This can make it difficult to draw sound performance-tuning conclusions. This uses hardware, typically a crystal oscillator, that produces ticks at a very high constant rate regardless of processor speed, power settings, or anything of that nature. SQL Server uses the high-precision QueryPerformanceCounter API to capture timing data.
A data pipeline is a software which runs on hardware. The software is error-prone and hardware failures are inevitable. If tuned for performance, there is a good change reliability is compromised - and vice versa. A data pipeline can process data in a different order than they were received.
A peculiar throughput limitation on Intel’s Xeon Phi x200 (Knights Landing) Introduction: In December 2017, my colleague Damon McDougall (now at AMD) asked for help in porting the fused multiply-add example code from a Colfax report ( [link] ) to the Xeon Phi x200 (Knights Landing) processors here at TACC.
Introduction: In December 2017, my colleague Damon McDougall (now at AMD) asked for help in porting the fused multiply-add example code from a Colfax report ( [link] ) to the Xeon Phi x200 (Knights Landing) processors here at TACC. of the “adjusted peak performance”, there is no longer a significant upside to performance tuning.
Edit the load testing script and add the following code section after tab0 variable initialized: Tab.SetRequestHeader(“loadtest”,”x-dynatrace”); Execute the EveryStep Script load test script several times (single user). Verify hardware sizing. Make application tuning much easier. Replay the Browser based script.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content