This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It enables multiple operating systems to run simultaneously on the same physical hardware and integrates closely with Windows-hosted services. Firstly, managing virtual networks can be complex as networking in a virtual environment differs significantly from traditional networking.
They may stem from software bugs, cyberattacks, surges in demand, issues with backup processes, network problems, or human errors. Software bugs Software bugs and bad code releases are common culprits behind tech outages. Software bugs Software bugs and bad code releases are common culprits behind tech outages.
Because container as a service doesn’t rely on a single code language or code stack, it’s platform agnostic. The emergence of Docker and other container services enabled companies to transport code quickly and easily. IaaS provides direct access to compute resources such as servers, storage, and networks.
There are a few important details worth unpacking around monolithic observability as it relates to these qualities: The nature of a monolithic application using a single programming language can ensure all code uses the exact same logging standards, location, and internal diagnostics. Just as the code is monolithic, so is the logging.
CPU consumption in Unix/Linux operating systems is studied using eight different metrics: User CPU time, System CPU time, nice CPU time, Idle CPU time, Waiting CPU time, Hardware Interrupt CPU time, Software Interrupt CPU time, Stolen CPU time. User CPU time is the amount of time the processor spends in running your application code.
They can also develop proactive security measures capable of stopping threats before they breach network defenses. For example, an organization might use security analytics tools to monitor user behavior and network traffic. If the code doesn’t carry a known signature, it may gain access even if it contains malicious payloads.
The IBM Z platform is a range of mainframe hardware solutions that are quite frequently used in large computing shops. Typically, these shops run the z/OS operating system, but more recently, it’s not uncommon to see the Z hardware running special versions of Linux distributions. Disk measurements with per-disk resolution.
Container technology is very powerful as small teams can develop and package their application on laptops and then deploy it anywhere into staging or production environments without having to worry about dependencies, configurations, OS, hardware, and so on. Networking. In production, containers are easy to replicate.
AWS Lambda is a serverless compute service that can run code in response to predetermined events or conditions and automatically manage all the computing resources required for those processes. Customizing and connecting these services requires code. What is AWS Lambda? Where does Lambda fit in the AWS ecosystem?
Indeed, according to one survey, DevOps practices have led to 60% of developers releasing code twice as quickly. But increased speed creates a tradeoff: According to another study, nearly half of organizations consciously deploy vulnerable code because of time pressure. Increased adoption of Infrastructure as code (IaC).
Open Connect Open Connect is Netflix’s content delivery network (CDN). video streaming) takes place in the Open Connect network. The network devices that underlie a large portion of the CDN are mostly managed by Python applications. If any of this interests you, check out the jobs site or find us at PyCon. are you logged in?
Function as a service is a cloud computing model that runs code in small modular pieces, or microservices. Cloud providers then manage physical hardware, virtual machines, and web server software management. In a FaaS model, developers can write code functions on demand, without being hindered by dependencies on existing applications.
We had some fun getting hardware figured out, and I used a 3D printer to make some cases, but the whole project was interrupted by the delivery of the iPhone by Apple in late 2007. I wonder if any of my code is still present in todays Netflixapps?) The code is still up on github.
The IBM Z platform is a range of mainframe hardware solutions that are quite frequently used in large computing shops. Typically, these shops run the z/OS operating system, but more recently, it’s not uncommon to see the Z hardware running special versions of Linux distributions. Disk measurements with per-disk resolution.
A log is a detailed, timestamped record of an event generated by an operating system, computing environment, application, server, or network device. Logs can include data about user inputs, system processes, and hardware states. “Logging” is the practice of generating and storing logs for later analysis.
They use the same hardware, APIs, tools, and management controls for both the public and private clouds. Amazon Web Services (AWS) Outpost : This offering provides pre-configured hardware and software for customers to run native AWS computing, networking, and services on-premises in a cloud-native manner.
This is especially the case with microservices and applications created around multiple tiers, where cheaper hardware alternatives play a significant role in the infrastructure footprint. Here are details of the capabilities included in this release of OneAgent for Linux on the ARM platform: Deep-code monitoring.
Without a real return code, how can they know if it is safe to retry or not? But, with that prework, when the time comes, the kernel can easily construct the packet and get it out the (preconfigured) network interface as things come crashing down. You are practically constructing the UDP packet for the kernel.
Snap: a microkernel approach to host networking Marty et al., This paper describes the networking stack, Snap , that has been running in production at Google for the last three years+. Once the whole fleet has turned over, the code for the now unused version(s) can be removed. SOSP’19. It reminds me of ZeroMQ.
And we’re talking about accessing the details of so many crashes, that even our most demanding customers like international banking institutes, global car manufacturers, multi-national retail chains or world-spanning recreational networks can cover the timeframes that matter to their businesses. See what your users see.
There is no code or configuration change necessary to capture data and detect existing services. While most of our cloud & platform partners have their own dependency analysis tooling, most of them focus on basic dependency detection based on network connection analysis between hosts. Where to reduce data transfer in general?
Complementing the hardware is the software on the RAE and in the cloud, and bridging the software on both ends is a bi-directional control plane. When a new hardware device is connected, the Local Registry detects and collects a set of information about it, such as networking information and ESN.
Real-time flight data monitoring setup using ADS-B (using OpenTelemetry) and Dynatrace The hardware We’ll delve into collecting ADS-B data with a Raspberry Pi, equipped with a software-defined radio receiver ( SDR ) acting as our IoT device, which is a RTL2832/R820T2 based dongle , running an ADS-B decoder software ( dump1090 ).
Reducing CPU Utilization to now only consume 15% of initially provisioned hardware. In most cases, I’ve seen it’s either through bad coding, incorrect use of data access frameworks, or simply architecture that has grown over the years into something that became overly complex in terms of participating components and services.
This has not only led to AI acceleration being incorporated into common chip architectures such as CPUs, GPUs, and FPGAs but also mushroomed a class of dedicated hardware AI accelerators specifically designed to accelerate artificial neural networks and machine learning applications.
It requires purchasing, powering, and configuring physical hardware, training and retaining the staff capable of servicing and securing the machines, operating a data center, and so on. They need enough hardware to serve their anticipated volume and keep things running smoothly without buying too much or too little. Reduced cost.
Its concurrency mechanism makes it easy to write programs that maximize the use of multicore and network machines, and its innovative type system enables flexible and modular program construction. Go compiles quickly to machine code, but with the convenience of garbage collection and the power of runtime reflection.
As such, it’s quite often a network-shared mount point that multiple hosts use to store third party software and libraries. You can also easily choose an existing network zone or host group. The /opt directory is typically used for deployment of additional software running on the Unix system.
Cloud application security practices enable organizations to follow secure coding practices, monitor and log activities for detection and response, comply with regulations, and develop incident response plans. It also entails secure development practices, security monitoring and logging, compliance and governance, and incident response.
The reason is because mobile networks are, as a rule, high latency connections. Application runtime: It’s kind of obvious really, but the time it takes to run your actual application code is going to be a large contributor to your TTFB. Database queries: Pages that require data from a database will incur a cost when searching over it.
Photo by Freepik Part of the answer is this: You have a lot of control over the design and code for the pages on your site, plus a decent amount of control over the first and middle mile of the network your pages travel over. For a myriad of reasons, older hardware can't always accommodate faster speeds. After DOCSIS 4.0
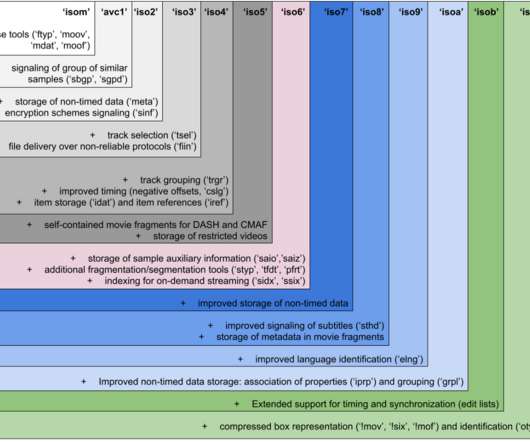
In all these cases, prior to being delivered through our content delivery network Open Connect , our award-winning TV shows, movies and documentaries like The Crown need to be packaged to enable crucial features for our members. Figure 1?—?Simplified Figure 2?—?Illustrating Illustrating the complexity of the 6th edition of ISOBMFF.
There is also a wide network of Oracle partners available to help you negotiate a discount , typically ranging from 15%-30%, though larger discounts of up to 40%-60% are available for larger accounts. Oracle support for hardware and software packages is typically available at 22% of their licensing fees. So Which Is Best?
HPU: Holographic Processing Unit (HPU) is the specific hardware of Microsoft’s Hololens. They use the graph as the basic representation for many AI-related algorithms, including neural network, Bayesian network, Markov Field, and some other emerging methods. HPU1 with TSMC 28nm process was announced in HOTCHIPS’17.
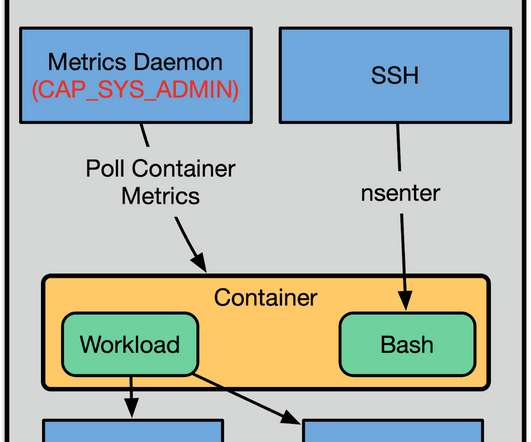
In addition to the default Docker namespaces (mount, network, UTS, IPC, and PID), we employ user namespaces for added layers of isolation. Let’s go back to that kernel code example earlier. Unfortunately, these default namespace boundaries are not sufficient to prevent container escape, as seen in CVEs like CVE-2015–2925.
An open-source benchmark suite for microservices and their hardware-software implications for cloud & edge systems Gan et al., The paper examines the implications of microservices at the hardware, OS and networking stack, cluster management, and application framework levels, as well as the impact of tail latency.
Defining high availability In general terms, high availability refers to the continuous operation of a system with little to no interruption to end users in the event of hardware or software failures, power outages, or other disruptions. Without enough infrastructure (physical or virtualized servers, networking, etc.),
Amazon SageMaker training supports powerful container management mechanisms that include spinning up large numbers of containers on different hardware with fast networking and access to the underlying hardware, such as GPUs. This can all be done without touching a single line of code.
This approach puts some limitations on packing efficiency, and also necessitates a container trade-off between security and code compatibility based on the types of syscalls containers are allowed to make. Approaches such as unikernels can help with this, but once again the AWS requirement to be able to run unmodified code rules these out.
Some of the most important elements include: No single point of failure (SPOF): You must eliminate any SPOF in the database environment, including any potential for an SPOF in physical or virtual hardware. Without enough infrastructure (physical or virtualized servers, networking, etc.), there cannot be high availability.
Lots can go wrong: a network request fails, a third-party library breaks, a JavaScript feature is unsupported (assuming JavaScript is even available), a CDN goes down, a user behaves unexpectedly (they double-click a submit button), the list goes on. How To Build Resilient JavaScript UIs. Callum Hart. 2021-08-03T11:00:00+00:00.
” Each step has been a twist on “what if we could write code to interact with a tamper-resistant ledger in real-time?” Doubly so as hardware improved, eating away at the lower end of Hadoop-worthy work. Mental contortions led to code contortions led to frustration. And, often, to giving up.
The homepage needs to load in a reasonable amount of time, even in poor network conditions. However, it would be cost-inefficient to leverage this same hardware for lightweight and more consistent traffic patterns that an asset management service requires. First, the fields can be coded by hand.
0] would be easy to call “obvious” in hindsight, but it’s far from the only option and this paper’s analysis shows a thorough consideration of alternatives, including their effects on existing and future code and future language evolution. Seeing only the end result of T.[0] This is that library. You can check out the diff in these | commits.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content