This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
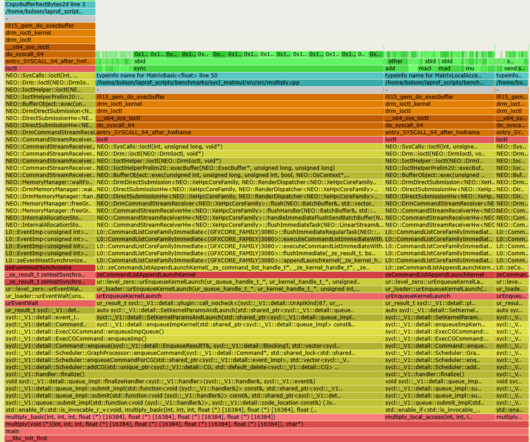
Drilling down into “hot” methods and further into the assembly code showed us blocks of code with some instructions exceeding 100 CPI, which is extremely slow. This is the summary of our findings: Numbered markers from 1 to 6 denote the same code/variables across the sources and vTune assembly view.
Infrastructure as code is a way to automate infrastructure provisioning and management. In this blog, I explore how Dynatrace has made cloud automation attainable—and repeatable—at scale by embracing the principles of infrastructure as code. Infrastructure-as-code. In response, Dynatrace introduced Monaco (Monitoring-as-code).
At Intel we've been creating a new analyzer tool to help reduce AI costs called AI Flame Graphs : a visualization that shows an AI accelerator or GPU hardware profile along with the full software stack, based on my CPU flame graphs. The gray "-" frames just help highlight the boundary between CPU and AI/GPU code.
Because container as a service doesn’t rely on a single code language or code stack, it’s platform agnostic. The emergence of Docker and other container services enabled companies to transport code quickly and easily. In FaaS environments, providers manage all the hardware. The classes of CaaS. CaaS vs. PaaS.
It enables multiple operating systems to run simultaneously on the same physical hardware and integrates closely with Windows-hosted services. Therefore, they experience how the application code functions and how the application operations depend on the underlying hardware resources and the operating system managed by Hyper-V.
Dynatrace has been building automated distributed application instrumentation—without the need to modify source code—for over 15 years already. Dynatrace PurePath technology captures and analyzes transactions end to end across every tier of your application technology stack, from the browser all the way down to the code and database level.
There are a few important details worth unpacking around monolithic observability as it relates to these qualities: The nature of a monolithic application using a single programming language can ensure all code uses the exact same logging standards, location, and internal diagnostics. Just as the code is monolithic, so is the logging.
AWS Lambda is a serverless compute service that can run code in response to predetermined events or conditions and automatically manage all the computing resources required for those processes. Customizing and connecting these services requires code. What is AWS Lambda? Where does Lambda fit in the AWS ecosystem?
By leveraging Dynatrace observability on Red Hat OpenShift running on Linux, you can accelerate modernization to hybrid cloud and increase operational efficiencies with greater visibility across the full stack from hardware through application processes.
Software bugs Software bugs and bad code releases are common culprits behind tech outages. These issues can arise from errors in the code, insufficient testing, or unforeseen interactions among software components. These can be caused by hardware failures, or configuration errors, or external factors like cable cuts.
Indeed, according to one survey, DevOps practices have led to 60% of developers releasing code twice as quickly. But increased speed creates a tradeoff: According to another study, nearly half of organizations consciously deploy vulnerable code because of time pressure. Increased adoption of Infrastructure as code (IaC).
This allows teams to sidestep much of the cost and time associated with managing hardware, platforms, and operating systems on-premises, while also gaining the flexibility to scale rapidly and efficiently. Performing updates, installing software, and resolving hardware issues requires up to 17 hours of developer time every week.
Vulnerabilities or hardware failures can disrupt deployments and compromise application security. For instance, if a Kubernetes cluster experiences a hardware failure during deployment, it can lead to service disruptions and affect the user experience.
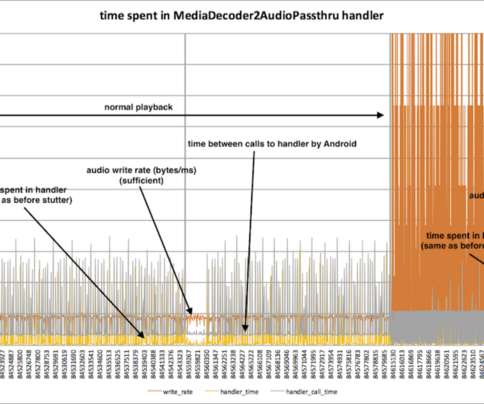
Next I started reading the Ninja source code. I wanted to find the precise code that delivers the audio data. I recognized a lot, but I started to lose the plot in the playback code and I needed help. I wanted to answer this question: where is the extra time?
CPU consumption in Unix/Linux operating systems is studied using eight different metrics: User CPU time, System CPU time, nice CPU time, Idle CPU time, Waiting CPU time, Hardware Interrupt CPU time, Software Interrupt CPU time, Stolen CPU time. User CPU time is the amount of time the processor spends in running your application code.
Sustainable memory bandwidth using multi-threaded code has closely followed the peak DRAM bandwidth, typically delivering best case throughput of 75%-85% of the peak DRAM bandwidth in each generation. Yes, but (on these Intel processors) only if the L2 hardware prefetchers are disabled. The same is true for software prefetches.)
The IBM Z platform is a range of mainframe hardware solutions that are quite frequently used in large computing shops. Typically, these shops run the z/OS operating system, but more recently, it’s not uncommon to see the Z hardware running special versions of Linux distributions.
We had some fun getting hardware figured out, and I used a 3D printer to make some cases, but the whole project was interrupted by the delivery of the iPhone by Apple in late 2007. I wonder if any of my code is still present in todays Netflixapps?) The code is still up on github.
This gives you deep visibility into your code running in Azure Functions, and, as a result, an understanding of its impact on overall application performance and user experience. Code-level visibility continues to be supported for.NET-based functions running in an App Service plan. Optimize your code with code-level visibility.
They use the same hardware, APIs, tools, and management controls for both the public and private clouds. Amazon Web Services (AWS) Outpost : This offering provides pre-configured hardware and software for customers to run native AWS computing, networking, and services on-premises in a cloud-native manner.
Instead of worrying about infrastructure management functions, such as capacity provisioning and hardware maintenance, teams can focus on application design, deployment, and delivery. Using a low-code visual workflow approach, organizations can orchestrate key services, automate critical processes, and create new serverless applications.
Function as a service is a cloud computing model that runs code in small modular pieces, or microservices. Cloud providers then manage physical hardware, virtual machines, and web server software management. In a FaaS model, developers can write code functions on demand, without being hindered by dependencies on existing applications.
Security analytics solutions are designed to handle modern applications that rely on dynamic code and microservices. If the code doesn’t carry a known signature, it may gain access even if it contains malicious payloads. Infrastructure type In most cases, legacy SIEM tools are on-premises.
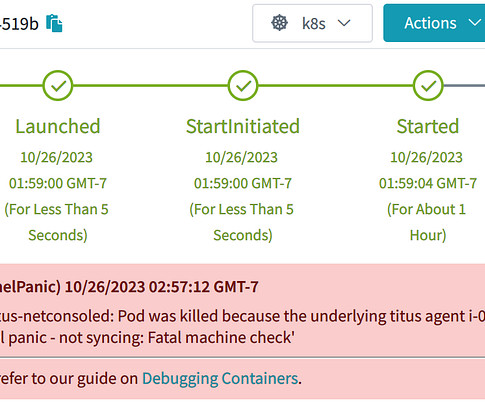
Without a real return code, how can they know if it is safe to retry or not? nil { klog.Errorf("Error deleting node %s: %s", node.Name, err) } else { klog.Infof("Deleted panicked node %s", node.Name) } } } With that code in place, as soon as a kernel panic is detected, the pods and nodes immediately go away.
2% : of sales spent by consumer packaged goods companies on R&D (14% for tech); 272 million : metric tons of plastic are produced each year around the globe; 100+ fp s: Google's Edge TPU; 6,000 : bugs per million lines of code; 2.2 They'll learn a lot and love you forever.
Container technology is very powerful as small teams can develop and package their application on laptops and then deploy it anywhere into staging or production environments without having to worry about dependencies, configurations, OS, hardware, and so on. The time and effort saved with testing and deployment are a game-changer for DevOps.
For one Dynatrace customer, a hardware and software provider, introducing automation into DevOps processes was a game-changer. Today, with greater focus on DevOps and developer observability, engineers spend 70%-75% of their time writing code and increasing product innovation.
This gives you deep visibility into your code running in Azure Functions, and, as a result, an understanding of its impact on overall application performance and user experience. Code-level visibility continues to be supported for.NET-based functions running in an App Service plan. Optimize your code with code-level visibility.
The division by a power of two ( / (2 N )) can be implemented as a right shift if we are working with unsigned integers, which compiles to single instruction: that is possible because the underlying hardware uses a base 2. I make my benchmarking code available. uint32_t fastmod ( uint32_t n ) {. LLVM’s clang, GNU GCC).
The IBM Z platform is a range of mainframe hardware solutions that are quite frequently used in large computing shops. Typically, these shops run the z/OS operating system, but more recently, it’s not uncommon to see the Z hardware running special versions of Linux distributions.
In these modern environments, every hardware, software, and cloud infrastructure component and every container, open-source tool, and microservice generates records of every activity. Observability relies on telemetry derived from instrumentation that comes from the endpoints and services in your multi-cloud computing environments.
Limits of a lift-and-shift approach A traditional lift-and-shift approach, where teams migrate a monolithic application directly onto hardware hosted in the cloud, may seem like the logical first step toward application transformation. Likewise, refactoring and rewriting code takes a lot of time and effort.
A decade ago, while working for a large hosting provider, I led a team that was thrown into turmoil over the purchasing of server and storage hardware in preparation for a multi-million dollar super-bowl ad campaign. Take a look at the GKE cluster I instrumented in Las Vegas to see how tracing works without any special code commits.
It requires purchasing, powering, and configuring physical hardware, training and retaining the staff capable of servicing and securing the machines, operating a data center, and so on. They need enough hardware to serve their anticipated volume and keep things running smoothly without buying too much or too little. Reduced cost.
In fact, according to the recent Dynatrace survey, “ The state of AI 2024 ,” 95% of technology leaders are concerned that using generative AI to create code could result in data leakage and improper or illegal use of intellectual property. In this blog, Carolyn Ford recaps her discussion with Tracy Bannon about AI in the workplace.
I’ve been playing around with an Arduino Uno recently, something new to me since I’ve always only used Raspberry Pi hardware. To develop and push code to an Arduino you need to use the Arduino Desktop IDE. In this tutorial I’m going to walk you through configuring Visual Studio Code for Arduino development.
This allows you to quickly see if there’s a specific hardware configuration or software version in your customer group that is affected or if the problem affects all your users. You’ll now find breakdowns for all relevant properties right on top of the crash-group page so that you can see patterns at a glance.
This has not only led to AI acceleration being incorporated into common chip architectures such as CPUs, GPUs, and FPGAs but also mushroomed a class of dedicated hardware AI accelerators specifically designed to accelerate artificial neural networks and machine learning applications.
This is especially the case with microservices and applications created around multiple tiers, where cheaper hardware alternatives play a significant role in the infrastructure footprint. Here are details of the capabilities included in this release of OneAgent for Linux on the ARM platform: Deep-code monitoring.
Reducing CPU Utilization to now only consume 15% of initially provisioned hardware. In most cases, I’ve seen it’s either through bad coding, incorrect use of data access frameworks, or simply architecture that has grown over the years into something that became overly complex in terms of participating components and services.
That’s tremendous, especially when you see four of the six hours were introduced by customer code,” said Auer. First, he pointed to the infrastructure monitoring capabilities as critical to understanding the impact of hardware failures. More still, very little of that downtime was related to the SAP cloud platform.
While modern cloud systems simplify tasks — such as deploying apps and provisioning new hardware and servers — cloud environments can be surprisingly complex. “This facilitates what’s known as configuration as code or monitoring as code. ” Foundational observability paves the way for proactive cloud operations.
The obvious costs of tool sprawl can quickly add up, including licensing, support, maintenance, training, hardware, and often additional headcount. Their staff spends more time on code development rather than spending time on triage and bug fixes. Ultimately, Zbojniewicz has saved $1.4M annually when starting with Dynatrace.
Such applications track the inventory of our network gear: what devices, of which models, with which hardware components, located in which sites. One example is the Spectator Python client library, a library for instrumenting code to record dimensional time series metrics. We currently provide Python and Ruby libraries for Prism.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content