This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Business events: Delivering the best data It’s been two years since we introduced business events , a special class of events designed to support even the most demanding business use cases. Business event ingestion and analysis with log files. OpenPipeline: Simplify access and unify business events from anywhere.
This lets you build your SLOs around the indicators that matter to you and your customers—critical metrics related to availability, failure rates, request response times, or select logs and business events. Are you experiencing an increase or degradation in certain events that indicate a rising problem?
Traditional monitoring approaches often require manual scripting and integration to get alerted about production-threatening issues in pre-production environments. You can select any trigger thats available for standard workflows, including schedules, problem triggers, customer event triggers, or on-demand triggers.
On average, organizations use 10 different tools to monitor applications, infrastructure, and user experiences across these environments. Clearly, continuing to depend on siloed systems, disjointed monitoring tools, and manual analytics is no longer sustainable.
But to be scalable, they also need low-code/no-code solutions that don’t require a lot of spin-up or engineering expertise. IT leaders know that managing cloud environments through traditional manual monitoring practices will no longer suffice. The low-code/no-code AutomationEngine brings several benefits to customers.
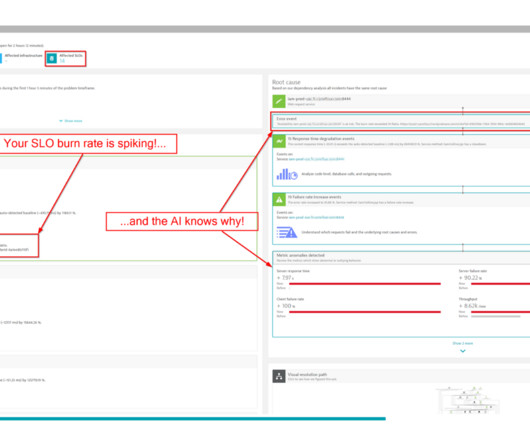
The first part of this blog post briefly explores the integration of SLO events with AI. Consequently, the AI is founded upon the related events, and due to the detection parameters (threshold, period, analysis interval, frequent detection, etc), an issue arose. In other words, where the application code resides.
Business events powered by our new Grail™ data lakehouse and by other Dynatrace platform technologies ensures the real-time precision that business and IT teams need to make data-driven decisions and improve business outcomes. Business events deliver the industry’s broadest, deepest, and easiest access to your critical business data.
Synthetic monitoring enhances observability by enabling proactive testing and monitoring systems to identify potential issues before they quickly impact users. Returning to the Jenga metaphor, synthetic monitoring observes the tower from a distance, from the end user’s perspective, and triggers instability warnings immediately.
In many cases, events are generated as these workloads go through different phases of their life cycles. For instance, events appear when the scheduler performs actions to bring workloads back to a desired state. For better or worse, every Kubernetes user learns about the CrashLoopBackOff and ImagePullBackOff events.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
Synthetic monitoring can help to confirm your applications are performing as intended and, in the event they’re not, help you quickly figure out what’s going on. Here’s a look at what synthetic monitoring is, how it’s different from real-user monitoring, and why it matters to your business.
But are observability platforms—born from the collision between the demands of cloud computing and the limitations of APM and infrastructure monitoring—the best solution for managing business analytics? Observability fault lines The monitoring of complex and dynamic IT systems includes real-time analysis of baselines, trends, and anomalies.
Findings from various stages of the Software Development Lifecycle (SDLC) are mixed in: code scans, build scans, and runtime. Add context to AWS Security Hub findings The Dynatrace platform, powered by OpenPipeline , provides unified security event ingest and analysis across tools and cloud environments.
Business events are a special class of events, new to Business Analytics; together with Grail, our data lakehouse, they provide the precision and advanced analytics capabilities required by your most important business use cases. What are business events? This diagram shows a few examples of business events.
It gives you visibility into which components are monitored and which are not and helps automate time-consuming compliance configuration checks. Discovery & Coverage helps prevent unexpected outages by detecting and remediating monitoring coverage gaps across your entire enterprise.
Monitoring Kubernetes is an important aspect of Day 2 o perations and is often perceived as a significant challenge. A container with inefficient code might affect critical workloads and practically make the whole node unusable , or worse, because of replication, it can impact the whole cluster. Node and w orkload health .
With the pace of digital transformation continuing to accelerate, organizations are realizing the growing imperative to have a robust application security monitoring process in place. What are the goals of continuous application security monitoring and why is it important?
Dynatrace broadens its Digital Experience Monitoring capabilities by adding Flutter support. With the release of Flutter support in Dynatrace, we’re filling a gap that no other solution in the market has addressed, enabling you to leverage the full power of Dynatrace Digital Experience Monitoring for Flutter apps.
Recent platform enhancements in the latest Dynatrace, including business events powered by Grail™, make accessing the goldmine of business data flowing through your IT systems easier than ever. Business events can come from many sources, including OneAgent®, external business systems, RUM sessions, or log files.
Log monitoring, log analysis, and log analytics are more important than ever as organizations adopt more cloud-native technologies, containers, and microservices-based architectures. A log is a detailed, timestamped record of an event generated by an operating system, computing environment, application, server, or network device.
Dynatrace has offered a Lambda code module for Node.js This has led to the recent release of our new Lambda monitoring extension supporting Node.js, Java, and Python. exports.handler = async function(event, context) { console.log("EVENT: n" + JSON.stringify(event, null, 2)); return context.logStreamName; }.
On the other hand, deploying new code on the backend is complex and offers no such transparency. With Dynatrace Live Debugger, you can set a non-breaking breakpoint and instantly see if new code is following the intended new paths, if any new arguments are being considered, and if input and output arguments are aligned with expectations.
Monitoring business processes is one thing organizations can do to help improve the key business processes that enable them to provide great customer experiences. Business process monitoring refers to continuously tracking and analyzing key performance indicators (KPIs) from relevant process milestones.
Observability is the new standard of visibility and monitoring for cloud-native architectures. It’s powered by vast amounts of collected telemetry data such as metrics, logs, events, and distributed traces to measure the health of application performance and behavior. Observability brings multicloud environments to heel.
It’s not uncommon to see different teams use different monitoring solutions to monitor different features—this makes it a real challenge to achieve end-to-end visibility of application requests. Follow transactions from one monitoring environment to another with cross-environmental tracing (Preview). Limitations.
Infrastructure as code is a way to automate infrastructure provisioning and management. In this blog, I explore how Dynatrace has made cloud automation attainable—and repeatable—at scale by embracing the principles of infrastructure as code. Infrastructure-as-code. In response, Dynatrace introduced Monaco (Monitoring-as-code).
This is why we’re proud to announce fully automated and AI-powered full-stack monitoring for OpenShift 4.0 Traditional monitoring systems cannot keep up with the speed of change in those highly dynamic large-scale container environments. Automated distributed tracing, deep monitoring and AI-powered answers for OpenShift 4.0
Despite its benefits, serverless computing introduces additional monitoring challenges for developers and IT Operations, particularly in understanding dependencies and identifying issues in the end-to-end traces that flow through a complex mix of dynamic and hybrid on-premise/cloud environments. Azure Functions in a nutshell.
These resources generate vast amounts of data in various locations, including containers, which can be virtual and ephemeral, thus more difficult to monitor. These challenges make AWS observability a key practice for building and monitoring cloud-native applications. AWS monitoring best practices. What is AWS observability?
Load and DOMContentLoaded are internal browser events—your users have no idea what a Load time even is. I’m willing to bet you still monitor TTFB , even though you know your customers will have no concept of a first byte whatsoever. The DOMContentLoaded event fires once all of your deferred JavaScript has finished running.
Dynatrace Digital Experience Monitoring , as part of the Dynatrace Software Intelligence Platform, connects front-end monitoring and the outside-in user perspective with application performance to understand the impact of performance issues across your full stack on user experience and business outcomes. Virginia (Azure), N.
Dynatrace is proud to provide deep monitoring support for Azure Linux as a container host operating system (OS) platform for Azure Kubernetes Services (AKS) to enable customers to operate efficiently and innovate faster. Why monitor Azure Linux container host for AKS? How Can Dynatrace Monitor Azure Linux container host for AKS?
Dynatrace Synthetic Monitoring allows you to proactively monitor the availability of your public as well as your internal web applications and API endpoints from locations around the globe or important internal locations such as branch offices. Synthetic monitors help you find issues before they affect your customers.
According to InfoQ , Kubernetes monitoring offers substantial benefits for container management, but it’s not a complete platform in and of itself. “You need to understand and detect non-performing code or where and how exceptions happen — which user or transaction triggered it, its context, its backtrace, and its metadata.
Department of Veterans Affairs (VA) is packaging application code along with its libraries and dependencies within an executable software unit. Dynatrace container monitoring supports customers as they collect metrics, traces, logs, and other observability-enabled data to improve the health and performance of containerized applications.
Similar to the observability desired for a request being processed by your digital services, it’s necessary to comprehend the metrics, traces, logs, and events associated with a code change from development through to production. Code : The branch for the new feature in a GitHub repository is merged into the main branch.
Even the best baseline approaches come with a tiny percentage of false-positive alerts, the number being directly proportional to the number of components you’re monitoring. Save time by directly analyzing code-level information. Beyond traceability: From root cause to code-level context in a single click.
Years later, a few configuration management solutions came into play that required heavy amounts of coding, but proved that the industry was moving toward compartmentalized automation solutions. These evaluations that I hard-coded into a script were now embedded into the back-end of Ansible’s modular approach.
The Dynatrace Software Intelligence Platform provides you with so much more monitoring functionality. This means that your entire IT infrastructure can be monitored within minutes. OneAgent monitors the full technology stack of each host. You name it, and we have it! Automate and save time! And even Digital business analytics.
Every software development team grappling with Generative AI (GenAI) and LLM-based applications knows the challenge: how to observe, monitor, and secure production-level workloads at scale. Production performance monitoring: Service uptime, service health, CPU, GPU, memory, token usage, and real-time cost and performance metrics.
SLO monitoring and alerting on SLOs using error-budget burn rates are critical capabilities that can help organizations achieve that goal. Without implementing robust SLO monitoring, anomaly detection, and alerting on SLOs, teams can miss issues that breach defined quality targets. What is SLO monitoring?
Many organizations also adopt an observability solution to help them detect and analyze the significance of events to their operations, software development life cycles, application security, and end-user experiences. What is the difference between monitoring and observability? Is observability really monitoring by another name?
The Dynatrace platform establishes context across all observability data sources – metrics, events, logs, traces, user sessions, synthetic probes, runtime security vulnerabilities, and more. For the CrowdStrike issue, one can use both monitored Windows System logs and the Dynatrace entity model to find out what servers are impacted.
T he testing stage plays a crucial role in ensuring the quality of newly built code through the execution of automated test cases. Testing includes integration tests, which assess whether the code functions as intended when interacting with other services and application functionalities.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content