This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Business events: Delivering the best data It’s been two years since we introduced business events , a special class of events designed to support even the most demanding business use cases. Business event ingestion and analysis with log files. OpenPipeline: Simplify access and unify business events from anywhere.
This lets you build your SLOs around the indicators that matter to you and your customers—critical metrics related to availability, failure rates, request response times, or select logs and business events. Are you experiencing an increase or degradation in certain events that indicate a rising problem?
This is achieved, in part, by establishing actionable statistical accuracy —not necessarily precise accuracy —through practical levels of metric sampling, aggregation, and extrapolation. To close these critical gaps, Dynatrace has defined a new class of events called business events.
Your teams want to iterate rapidly but face multiple hurdles: Increased complexity: Microservices and container-based apps generate massive logs and metrics. You can select any trigger thats available for standard workflows, including schedules, problem triggers, customer event triggers, or on-demand triggers. Its as simple as that!
The release candidate of OpenTelemetry metrics was announced earlier this year at Kubecon in Valencia, Spain. Since then, organizations have embraced OTLP as an all-in-one protocol for observability signals, including metrics, traces, and logs, which will also gain Dynatrace support in early 2023.
In IT and cloud computing, observability is the ability to measure a system’s current state based on the data it generates, such as logs, metrics, and traces. DevSecOps teams can tap observability to get more insights into the apps they develop, and automate testing and CI/CD processes so they can release better quality code faster.
But to be scalable, they also need low-code/no-code solutions that don’t require a lot of spin-up or engineering expertise. With the Dynatrace modern observability platform, teams can now use intuitive, low-code/no-code toolsets and causal AI to extend answer-driven automation for business, development and security workflows.
The first part of this blog post briefly explores the integration of SLO events with AI. Consequently, the AI is founded upon the related events, and due to the detection parameters (threshold, period, analysis interval, frequent detection, etc), an issue arose. In other words, where the application code resides.
Business events powered by our new Grail™ data lakehouse and by other Dynatrace platform technologies ensures the real-time precision that business and IT teams need to make data-driven decisions and improve business outcomes. Business events deliver the industry’s broadest, deepest, and easiest access to your critical business data.
It should also be possible to analyze data in context to proactively address events, optimize performance, and remediate issues in real time. This enables proactive changes such as resource autoscaling, traffic shifting, or preventative rollbacks of bad code deployment ahead of time.
In many cases, events are generated as these workloads go through different phases of their life cycles. For instance, events appear when the scheduler performs actions to bring workloads back to a desired state. For better or worse, every Kubernetes user learns about the CrashLoopBackOff and ImagePullBackOff events.
Dynatrace has recently extended its Kubernetes operator by adding a new feature, the Prometheus OpenMetrics Ingest , which enables you to import Prometheus metrics in Dynatrace and build SLO and anomaly detection dashboards with Prometheus data. Here we’ll explore how to collect Prometheus metrics and what you can achieve with them.
Business events are a special class of events, new to Business Analytics; together with Grail, our data lakehouse, they provide the precision and advanced analytics capabilities required by your most important business use cases. What are business events? This diagram shows a few examples of business events.
There’s no lack of metrics, logs, traces, or events when monitoring your Kubernetes (K8s) workloads. If you take a closer look at the screenshot above it’s easy to spot the root cause; it was an unhandled error condition in the code that was waiting and processing feedback from the MongoDB instance. Dynatrace news.
They need event-driven automation that not only responds to events and triggers but also analyzes and interprets the context to deliver precise and proactive actions. These initial automation endeavors paved the way for greater advancements, leading to the next evolution of event-driven automation.
Save time by directly analyzing code-level information. With the unique code-level capabilities of Davis, we’ve reduced the number of clicks required to reach and understand code-level findings. Beyond traceability: From root cause to code-level context in a single click. We opened up the Davis 2.0
I never thought I’d write an article in defence of DOMContentLoaded , but here it is… For many, many years now, performance engineers have been making a concerted effort to move away from technical metrics such as Load , and toward more user-facing, UX metrics such as Speed Index or Largest Contentful Paint. Or are they…?
Amazon Bedrock , equipped with Dynatrace Davis AI and LLM observability , gives you end-to-end insight into the Generative AI stack, from code-level visibility and performance metrics to GenAI-specific guardrails. Send unified data to Dynatrace for analysis alongside your logs, metrics, and traces.
Loosely defined, observability is the ability to understand what’s happening inside a system from the knowledge of the external data it produces, which are usually logs, metrics, and traces. Logs, metrics, and traces make up the bulk of all telemetry data. The data life cycle has multiple steps from start to finish.
Welcome back to the second part of our blog series on how easy it is to get enterprise-grade observability at scale in Dynatrace for your OpenTelemetry custom metrics. In Part 1 , we announced our new OpenTelemetry custom-metric exporters that provide the broadest language coverage on the market, including Go , .NET record(value); }.
With Dynatrace, you can also validate your findings against Real User Monitoring data or even drill down to the code level to pinpoint the root cause of a change in performance. Recently introduced improvements to Visually complete and new web performance metrics for Real User Monitoring are now available for Synthetic Monitoring as well.
Automatic detection of service health and performance incidences, which are synchronized into the Event Management Dashboard. . Prioritize event entries . With ServiceNow capturing event alert data from Dynatrace, you get complete visibility, including code level metrics and tracing, to eliminate service outages.
A natural solution is to make flows configurable using configuration files, so variants can be defined without changing the code. Unlike parameters, configs can be used more widely in your flow code, particularly, they can be used in step or flow level decorators as well as to set defaults for parameters.
To emit a run queue latency metric, we leveraged three eBPF hooks: sched_wakeup, sched_wakeup_new, and sched_switch. During this event, we generate a timestamp and store it in an eBPF hash map using the process ID as the key. ' They let us identify when a process is ready to run and is waiting for CPU time.
Similar to the observability desired for a request being processed by your digital services, it’s necessary to comprehend the metrics, traces, logs, and events associated with a code change from development through to production. Code : The branch for the new feature in a GitHub repository is merged into the main branch.
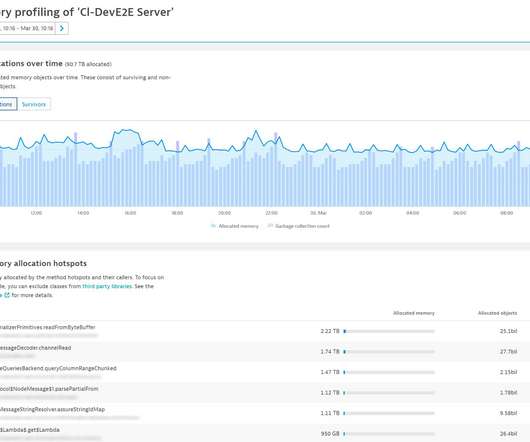
Optimize your code by finding and fixing the root cause of garbage collection problems. These details arm you with the knowledge necessary to find the respective code and remove unnecessary allocations. Any significant reduction in allocations will inevitably speed up your code. You can even look at the source code directly. .
The Dynatrace ® unified observability and security platform addresses the needs of enterprise-edge scenarios by managing the health and performance of containerized applications and multi-cloud infrastructures with metrics, traces, and logs in one place. The following illustrations outline a typical Red Hat Device Edge and Dynatrace setup.
Every service and component exposes observability data (metrics, logs, and traces) that contains crucial information to drive digital businesses. Logs and events play an essential role in this mix; they include critical information which can’t be found anywhere else, like details on transactions, processes, users and environment changes.
To provide automated feedback for developers, the concept of quality gates for static code analysis in continuous integration is widely adopted throughout the industry. The developer must pause their current engineering work to address the reported issue and consider the code changes they worked on a few days or weeks prior.
Telemetry data, such as traces and metrics, allow you to analyze the end-to-end performance of your deployed applications. Dynatrace Operator consumes DynaKubes with cloud-native full-stack configuration and deploys the following resources: Dynatrace OneAgent, deployed as a DaemonSet, collects host metrics from Kubernetes nodes.
Log files and APIs are the most common business data sources, and software agents may offer a simpler no-code option. Process health is determined through calculated metrics and process-specific KPIs such as throughput, revenue, cycle time, and exception rate.
Dynatrace has offered a Lambda code module for Node.js exports.handler = async function(event, context) { console.log("EVENT: n" + JSON.stringify(event, null, 2)); return context.logStreamName; }. This has led to the recent release of our new Lambda monitoring extension supporting Node.js, Java, and Python.
From a cost perspective, internal customers waste valuable time sending tickets to operations teams asking for metrics, logs, and traces to be enabled. A team looking for metrics, traces, and logs no longer needs to file a ticket to get their app monitored in their own environments. This approach is costly and error prone.
Observability Observability is the ability to determine a system’s health by analyzing the data it generates, such as logs, metrics, and traces. There are three main types of telemetry data: Metrics. Metrics are typically aggregated and stored in time series databases for monitoring and alerting purposes.
To make this possible, the application code should be instrumented with telemetry data for deep insights, including: Metrics to find out how the behavior of a system has changed over time. Logs represent event data in plain-text, structured or binary format. Traces help find the flow of a request through a distributed system.
Additionally, predictions based on historical data are reactive, solely relying on past information to anticipate future events, and can’t prevent all new or emerging issues. Automatic root cause detection Modern, complex, and distributed environments generate a substantial number of events.
Spring also introduced Micrometer, a vendor-agnostic metric API with rich instrumentation options. Soon after, Dynatrace built a registry for exporting Micrometer metrics. Our data APIs, which ingest millions of metrics, traces, and logs per second, are reconciled using Micrometer-based metrics.
Problems API v2 now includes event evidence data as part of the event details. Custom events for alerting using the Build tab and advanced query mode now apply the same metric dimension limits that are applied to Code -tab-based configurations. Events API v2 has been updated. Local self-monitoring metrics.
The Visual Resolution Path offers a chronological overview of events detected by Dynatrace across all components linked to the underlying issue. Additionally, align the action’s validation window with the timeframe derived from the recently completed test events. Configure an action for the Site Reliability Guardian in the workflow.
However, understanding the performance of different application types requires an emphasis on different performance metrics, that is, key performance metrics. For many traditional web applications , User action duration is considered the best metric available for web-performance optimization.
We wanted to expand and provide business process metrics (# of total orders per restaurant, orders canceled ratios, time per order, ingredients in or out of stock …) to quickly react to any issues and also get automatically alerted on anomalies. Rejections and Cancellation of Orders (our Code Red): 30% faster MTTR and 50% better visibility.
The Dynatrace platform establishes context across all observability data sources – metrics, events, logs, traces, user sessions, synthetic probes, runtime security vulnerabilities, and more. Q: Do we help with our customers’ entire environments?
When American Family Insurance took the multicloud plunge, they turned to Dynatrace to automate Amazon Web Services (AWS) event ingestion, instrument compute and serverless cloud technologies, and create a single workflow for unified event management. Step 1: Automate AWS metrics ingestion with Dynatrace.
In cloud-native environments, there can also be dozens of additional services and functions all generating data from user-driven events. Metrics, logs , and traces make up three vital prongs of modern observability. As a result, logging tools record large event volumes in real time. What else did the initial event affect?
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content