This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction With big data streaming platform and event ingestion service Azure Event Hubs , millions of events can be received and processed in a single second. Any real-time analytics provider or batching/storage adaptor can transform and store data supplied to an event hub.
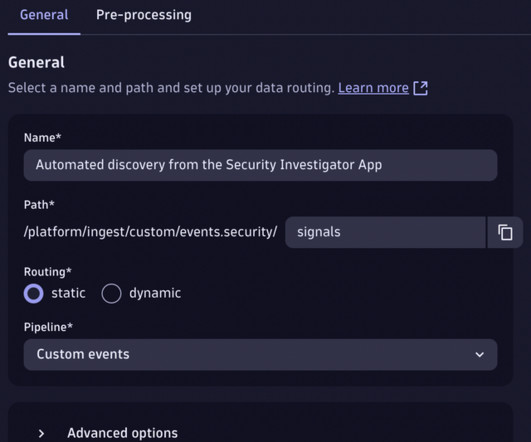
You now want to detect such events automatically by creating a custom Dynatrace security event. Ingest query results as security events The simplest way to do this is to use Dynatrace OpenPipeline. Set up a custom pipeline The best way to set up a security event ingestion to Dynatrace is via Dynatrace OpenPipeline.
Business events: Delivering the best data It’s been two years since we introduced business events , a special class of events designed to support even the most demanding business use cases. Business event ingestion and analysis with log files. OpenPipeline: Simplify access and unify business events from anywhere.
But to be scalable, they also need low-code/no-code solutions that don’t require a lot of spin-up or engineering expertise. With the Dynatrace modern observability platform, teams can now use intuitive, low-code/no-code toolsets and causal AI to extend answer-driven automation for business, development and security workflows.
This lets you build your SLOs around the indicators that matter to you and your customers—critical metrics related to availability, failure rates, request response times, or select logs and business events. Are you experiencing an increase or degradation in certain events that indicate a rising problem?
You can select any trigger thats available for standard workflows, including schedules, problem triggers, customer event triggers, or on-demand triggers. Here, you can select a specific event or a timed trigger like a cronjob. You can learn more about event triggers in Dynatrace Documentation. Its as simple as that!
The first part of this blog post briefly explores the integration of SLO events with AI. Consequently, the AI is founded upon the related events, and due to the detection parameters (threshold, period, analysis interval, frequent detection, etc), an issue arose. In other words, where the application code resides.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
Business events powered by our new Grail™ data lakehouse and by other Dynatrace platform technologies ensures the real-time precision that business and IT teams need to make data-driven decisions and improve business outcomes. Business events deliver the industry’s broadest, deepest, and easiest access to your critical business data.
To close these critical gaps, Dynatrace has defined a new class of events called business events. Dynatrace OneAgent ® prioritizes business events over observability metrics to ensure the lossless precision you need to support demanding business use cases.
Business events are a special class of events, new to Business Analytics; together with Grail, our data lakehouse, they provide the precision and advanced analytics capabilities required by your most important business use cases. What are business events? This diagram shows a few examples of business events.
It should also be possible to analyze data in context to proactively address events, optimize performance, and remediate issues in real time. This enables proactive changes such as resource autoscaling, traffic shifting, or preventative rollbacks of bad code deployment ahead of time.
They need event-driven automation that not only responds to events and triggers but also analyzes and interprets the context to deliver precise and proactive actions. These initial automation endeavors paved the way for greater advancements, leading to the next evolution of event-driven automation.
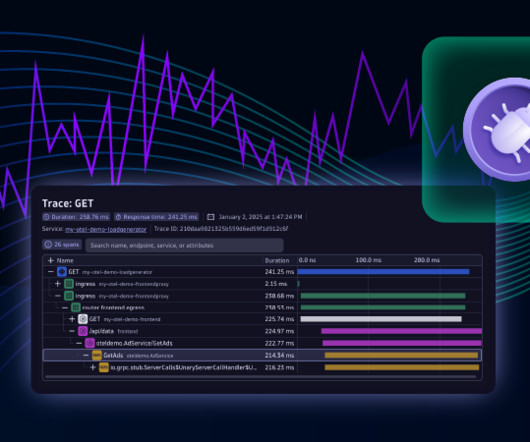
On the other hand, deploying new code on the backend is complex and offers no such transparency. With Dynatrace Live Debugger, you can set a non-breaking breakpoint and instantly see if new code is following the intended new paths, if any new arguments are being considered, and if input and output arguments are aligned with expectations.
Infrastructure as code is a way to automate infrastructure provisioning and management. In this blog, I explore how Dynatrace has made cloud automation attainable—and repeatable—at scale by embracing the principles of infrastructure as code. Infrastructure-as-code. In response, Dynatrace introduced Monaco (Monitoring-as-code).
Findings from various stages of the Software Development Lifecycle (SDLC) are mixed in: code scans, build scans, and runtime. Add context to AWS Security Hub findings The Dynatrace platform, powered by OpenPipeline , provides unified security event ingest and analysis across tools and cloud environments.
Upon detecting a high CPU load, Davis AI generates a problem event and populates it with a direct link to Live Debugger. This link allows us to open Live Debugger and dive into the code level of the AdService (example service) without requiring code changes or application redeployments.
Save time by directly analyzing code-level information. With the unique code-level capabilities of Davis, we’ve reduced the number of clicks required to reach and understand code-level findings. Beyond traceability: From root cause to code-level context in a single click. We opened up the Davis 2.0
Load and DOMContentLoaded are internal browser events—your users have no idea what a Load time even is. Equally, both DOMContentLoaded and Load aren’t just meaningless browser events, and once you understand what they actually signify, you can get some real insights as to your site’s runtime behaviour from each of them. That’s late!
Leveraging code-level insights and transaction analysis, Dynatrace Runtime Application Protection automatically detects attacks on applications in your environment. Workflows can be triggered manually, on a schedule, or by events in Dynatrace, such as anomalies detected by Davis AI.
Similar to the observability desired for a request being processed by your digital services, it’s necessary to comprehend the metrics, traces, logs, and events associated with a code change from development through to production. Code : The branch for the new feature in a GitHub repository is merged into the main branch.
As a Java Developer, we need to cover a lot of scenarios to ensure the quality of our software and catch bugs as soon as possible when introducing a new code. The answer which the community provided works well, but it is a lot of boilerplate code to just assert your log events. So the LogCaptor library came into life.
T he testing stage plays a crucial role in ensuring the quality of newly built code through the execution of automated test cases. Testing includes integration tests, which assess whether the code functions as intended when interacting with other services and application functionalities.
Amazon Bedrock , equipped with Dynatrace Davis AI and LLM observability , gives you end-to-end insight into the Generative AI stack, from code-level visibility and performance metrics to GenAI-specific guardrails. Any error codes or guardrail triggers. Temperature setting and max token limits.
Deploy stage In the deployment stage, the application code is typically deployed in an environment that mirrors the production environment. This step is crucial as this environment is used for the final validation and testing phase before the code is released into production. This approach effectively combats configuration drift.
During this event, we generate a timestamp and store it in an eBPF hash map using the process ID as the key. Each event includes a run queue latency sample with a cgroup ID, which we associate with running containers on the host. ' They let us identify when a process is ready to run and is waiting for CPU time.
As recent events have demonstrated, major software outages are an ever-present threat in our increasingly digital world. Software bugs Software bugs and bad code releases are common culprits behind tech outages. These issues can arise from errors in the code, insufficient testing, or unforeseen interactions among software components.
Harper lays out his current workflows and tools with detailed examples for both greenfield code and legacy code that make it easy for others to learn from what hes done. Its a great model for the kind of information sharing we hope to engender with the upcoming event and others that will follow.
Years later, a few configuration management solutions came into play that required heavy amounts of coding, but proved that the industry was moving toward compartmentalized automation solutions. These evaluations that I hard-coded into a script were now embedded into the back-end of Ansible’s modular approach.
Code changes are often required to refine observability data. This results in site reliability engineers nudging development teams to add resource attributes, endpoints, and tokens to their source code. Kubernetes workload pages offer resource analysis, lists of services, pods, events, and logs.
The Dynatrace platform establishes context across all observability data sources – metrics, events, logs, traces, user sessions, synthetic probes, runtime security vulnerabilities, and more. Q: Do we help with our customers’ entire environments?
We turned to JVM-specific profiling, starting with the basic hotspot stats, and then switching to more detailed JFR (Java Flight Recorder) captures to compare the distribution of the events. This is the summary of our findings: Numbered markers from 1 to 6 denote the same code/variables across the sources and vTune assembly view.
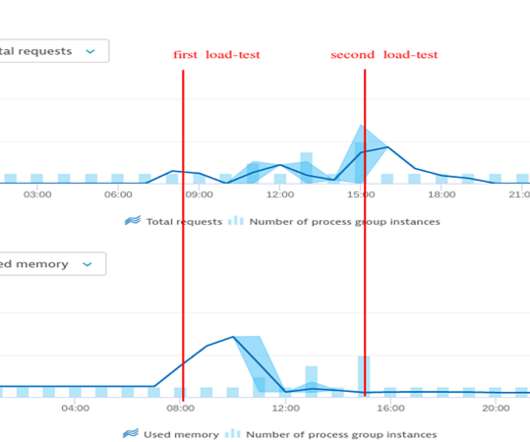
We want to share how Dynatrace helped us identify and fix memory leaks in one of the most central and critical components within Keptn: our event broker. For that reason, we started a simple load-test scenario where we flooded our event-based system with 100 cloud-events per minute. It happened in June 2020. Can we fix it?
Dynatrace Configuration as Code enables complete automation of the Dynatrace platform’s configuration, ensuring that software is secure and reliable. With Configuration as Code, developers can manage their observability and security tasks with config files that can be developed alongside source code conveniently and at scale.
Still, while DevOps practices enable developer agility and speed as well as better code quality, they can also introduce complexity and data silos. More seamless handoffs between tasks in the toolchain can improve DevOps efficiency, software development innovation, and better code quality. They need automated DevOps practices.
A natural solution is to make flows configurable using configuration files, so variants can be defined without changing the code. Unlike parameters, configs can be used more widely in your flow code, particularly, they can be used in step or flow level decorators as well as to set defaults for parameters.
Since becoming General Availability in the fall of 2019 , GitHub Actions has helped teams automate continuous integration and continuous delivery (CI/CD) workflows for code builds, tests, and deployments. Example #1 – Deploy application code to Kubernetes. Component levels information events such as releases and configuration changes.
Every automated workflow consists of easy configuration, extensive trigger options, out-of-the-box actions and integrations, and unprecedented extensibility by leveraging webhooks, JavaScript code, and application actions powered by AppEngine. Example workflow for event-driven vulnerability reporting and escalation.
Amazon compute solutions are designed to streamline resource provisioning and container management with two services: AWS Lambda : Lambda provides serverless compute infrastructure that lets you run code in response to predetermined events or conditions and automatically manage all compute resources required for these processes.
Logs and events play an essential role in this mix; they include critical information which can’t be found anywhere else, like details on transactions, processes, users and environment changes. Without user transactions and experience data, in relation to the underlying components and events, you miss critical context.
The occurrence of an exception during the execution of code can result in unexpected behavior unless the exception is properly handled in the code. Moving further, we would discuss how to handle exceptions elegantly and use exception handling to write clean code which is more maintainable. What is an Exception?
Perform is our company’s event once a year in Las Vegas, where our customers and partners visit us to learn more about our product and industry. However, it was my first time at Perform, and although I knew I would learn a thing or two in the next week, I was unaware of how beneficial taking part in this event would be.
Additionally, predictions based on historical data are reactive, solely relying on past information to anticipate future events, and can’t prevent all new or emerging issues. Automatic root cause detection Modern, complex, and distributed environments generate a substantial number of events.
Log files and APIs are the most common business data sources, and software agents may offer a simpler no-code option. Dynatrace business process observability leverages key platform capabilities, including: Business events , which provide easy access to business data, are automatically enriched with IT context.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content