This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A production bug is the worst; besides impacting customer experience, you need special access privileges, making the process far more time-consuming. It also makes the process risky as production servers might be more exposed, leading to the need for real-time production data. This cumbersome process should not be the norm.
What developers want Developers want to own their code in a distributed, ephemeral, cloud, microservices-based environment. This ownership starts with understanding how their code behaves in all environments, resolving issues, and writing and optimizing code in a high-quality, secure, and timely manner.
Processes are time-intensive. Slow processes introduce risk. Continuous visibility and assessment provide platform engineering, DevSecOps, DevOps, and SRE teams with the ability to track, validate, and remediate potential compliance-relevant findings and create the necessary evidence for the auditing process. Reactivity.
But to be scalable, they also need low-code/no-code solutions that don’t require a lot of spin-up or engineering expertise. With the Dynatrace modern observability platform, teams can now use intuitive, low-code/no-code toolsets and causal AI to extend answer-driven automation for business, development and security workflows.
Carefully planning and integrating new processes and tools is critical to ensuring compliance without disrupting daily operations. Visibility of all business processes starting from the back end and ending with customer experience is perhaps the biggest challenge.
Back during Perform 2019, we introduced the next generation of the Dynatrace AI causation engine , also known as Davis. becomes the default causation engine and will replace the previous version as the default for all new environments. as the default AI engine. AI causation engine. All existing Davis 1.0
Life of a Netflix Partner Engineer?—?The The case of the extra 40 ms By: John Blair , Netflix Partner Engineering The Netflix application runs on hundreds of smart TVs, streaming sticks and pay TV set top boxes. The role of a Partner Engineer at Netflix is to help device manufacturers launch the Netflix application on their devices.
In response to this shift, platform engineering is growing in popularity. The practice of platform engineering has evolved alongside the increasing complexity of cloud environments. Platform engineers design and implement these platforms, as well as ensure their security, scalability, and reliability.
Process Automation is defined as “a centerpiece of digitalization efforts” – where workflow engines are used as “a vital building block in modern architectures.” We also dive deep into Robotic Process Automation, how organizations are finding success with it, the risks involved, and why he considers it as a "short-term painkiller".
Platform engineering is on the rise. According to leading analyst firm Gartner, “80% of software engineering organizations will establish platform teams as internal providers of reusable services, components, and tools for application delivery…” by 2026.
Today, speed and DevOps automation are critical to innovating faster, and platform engineering has emerged as an answer to some of the most significant challenges DevOps teams are facing. It needs to be engineered properly as a product or service, and it needs automation, observability, and security in itself.”
As cloud-native, distributed architectures proliferate, the need for DevOps technologies and DevOps platform engineers has increased as well. DevOps engineer tools can help ease the pressure as environment complexity grows. ” What does a DevOps platform engineer do? .” What are DevOps engineer tools and platforms.
Site reliability engineering first emerged to address cloud computing’s new performance needs. Today, the platform engineer role is gaining speed as the newest byproduct of scaling DevOps in the emerging but complex cloud-native world. Understanding the platform engineer role DevOps is a constantly evolving discipline.
What is site reliability engineering? Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Dynatrace news. SRE focuses on automation.
We are proud to s hare Dynatrace has been named the winner in the “ Best Overall AI-based Analytics Company ” category, recognized for our innovation and the business-driving impact of our AI engine, Davis. . The post Dynatrace wins AI Breakthrough Award for Davis AI engine appeared first on Dynatrace blog.
This powerful tool can be leveraged across various environments, including production, to enhance development processes and ensure robust application performance. Following are some of the coolest things weve seen engineers do with Live Debugger. Live snapshot includes variables, process, stack trace, and tracing information.
The VS Code extension Dynatrace Apps is here to streamline your development process and simplify app building. Now you can easily query live data directly within VS Code using the Dynatrace Query Language (DQL). Sound familiar? This aids in effectively handling execution, loading, and error states.
Planned effort Site Reliability Engineering (SRE) effort and time allocation planning typically fall into two domains: Operations Management (50%) Operations Management includes on-call responsibilities, post-mortem assessments, addressing other interruptions, and buffer time. Streamlining the CI/CD process to ensure optimal efficiency.
As organizations look to expand DevOps maturity, improve operational efficiency, and increase developer velocity, they are embracing platform engineering as a key driver. As a result, teams can focus on writing code and building features rather than dealing with infrastructure nuances. “It makes them more productive.
But because of the complexity involved in executing and analyzing test results of dynamic systems, performance engineering is difficult to scale — especially with lean staff or resources. How can organizations address this process bottleneck and run more tests in less time? Current challenges with performance testing.
Future blogs will provide deeper dives into each service, sharing insights and lessons learned from this process. The Netflix video processing pipeline went live with the launch of our streaming service in 2007. The Netflix video processing pipeline went live with the launch of our streaming service in 2007.
When it comes to platform engineering, not only does observability play a vital role in the success of organizations’ transformation journeys—it’s key to successful platform engineering initiatives. The various presenters in this session aligned platform engineering use cases with the software development lifecycle.
Hence, having a dedicated dashboard tile visualizing the key parameters of each SLO simplifies the process of evaluating them. To implement SLOs in your software delivery cycle and consistently add observability measures from the beginning, Dynatrace “configuration as code” (Monaco and Dynatrace Terraform) will soon support the new API.
HashiCorp’s Terraform is an open-source infrastructure as a code software tool that provides a consistent CLI workflow to manage hundreds of cloud services. With this integration, Dynatrace customers can now leverage Terraform to manage their monitoring infrastructure as code,” said Asad Ali, Senior Director of Sales Engineering at Dynatrace.
DevOps and platform engineering are essential disciplines that provide immense value in the realm of cloud-native technology and software delivery. Observability of applications and infrastructure serves as a critical foundation for DevOps and platform engineering, offering a comprehensive view into system performance and behavior.
Smartscape topology visualizes the relationships between applications, services, processes, hosts, and data centers, highlighting problems and vulnerabilities. Leveraging code-level insights and transaction analysis, Dynatrace Runtime Application Protection automatically detects attacks on applications in your environment.
Developers are increasingly responsible for ensuring the quality and security of code throughout the software lifecycle. Developer-first observability Adding Rookout to the Dynatrace platform will provide developers with increased code-level observability of Kubernetes-hosted production environments.
by Jun He , Yingyi Zhang , and Pawan Dixit Incremental processing is an approach to process new or changed data in workflows. The key advantage is that it only incrementally processes data that are newly added or updated to a dataset, instead of re-processing the complete dataset.
When we discuss code profiling with a team of developers, they often say, "We don't have time to profile our code: that's why we have performance testers ," or, "If your application or system runs very slowly, the developers and performance testers may suggest the infra team to simply add another server to the server farm."
Infrastructure as code is a way to automate infrastructure provisioning and management. In this blog, I explore how Dynatrace has made cloud automation attainable—and repeatable—at scale by embracing the principles of infrastructure as code. Infrastructure-as-code. But how does it work in practice? Transparency and scalability.
Most of these leverage the unique capability of Dynatrace OneAgent® to extract business data from in-flight application payloads — without writing any code. Dynatrace OpenPipeline is a new stream processing technology that ingests and contextualizes data from any source. Business process monitoring and optimization.
Modern infrastructure needs to be elastic and GitOps approaches are used to automate the provisioning of infrastructure and applications using Git, an open-source control system that provides the change processes including reviews and approvals. Key components of GitOps are declarative infrastructure as code, orchestration, and observability.
This process involves: Identifying Stakeholders: Determine who is impacted by the issue and whose input is crucial for a successful resolution. In this context, were focused on developing systems that ensure successful title launches, build trust between content creators and our brand, and reduce engineering operational overhead.
Findings from various stages of the Software Development Lifecycle (SDLC) are mixed in: code scans, build scans, and runtime. Workflows serves as the automation engine to efficiently process and triage the security findings, create working tickets for your DevSecOps teams, and send notifications to the relevant stakeholders.
Broken Apache Struts 2: Technical Deep Dive into CVE-2024-53677The vulnerability allows attackers to manipulate file upload parameters, possibly leading to remote code execution. This blog post dissects the vulnerability, explains how Struts processes file uploads, details the exploit mechanics, and outlines mitigation strategies.
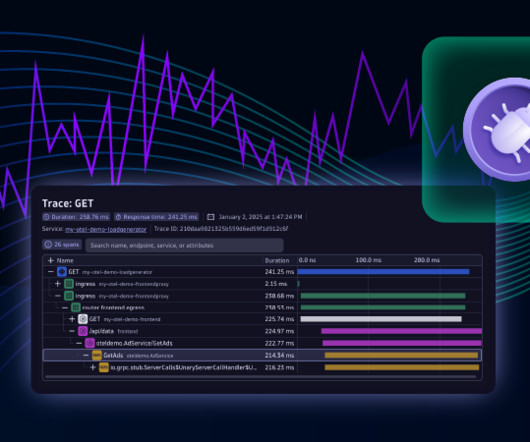
This link allows us to open Live Debugger and dive into the code level of the AdService (example service) without requiring code changes or application redeployments. We use the automatically populated filter for AdService and its corresponding source code repository, then select Done to go to Live Debugger.
A natural solution is to make flows configurable using configuration files, so variants can be defined without changing the code. Unlike parameters, configs can be used more widely in your flow code, particularly, they can be used in step or flow level decorators as well as to set defaults for parameters.
To pinpoint the exact requests that are failing, the e-commerce team filters by excluding successful HTTP 200 status codes. The team filters further by the “/cart/checkout endpoint” attribute value. This refinement reveals that only a few requests are failing. The team can now dive deeper to find out why.
Today, development teams suffer from a lack of automation for time-consuming tasks, the absence of standardization due to an overabundance of tool options, and insufficiently mature DevSecOps processes. Treating an Internal Developer Platform (IDP) as a product is an emerging paradigm within platform engineering communities.
However, you can simplify the process by automating guardians in the Site Reliability Guardian (SRG) to trigger whenever there are AWS tag changes, helping teams improve compliance and effectively manage system performance. tag.change” ` ` ` You should see log entries confirming the successful execution of your guardian process.
This process, known as auto-adaptive thresholding, eliminates the need to define a static threshold upfront. A key element in platform engineering is the establishment of fast feedback cycles regarding the quality and security measures of new software releases.
One of the main reasons this feature exists is just like with food samples, to give you “a taste” of the production quality ETL code that you could encounter inside the Netflix data ecosystem. " , country_code STRING COMMENT "Country code of the playback session." This is one way to build trust with our internal user base.
In the last blog post of this series, we delved into how Dynatrace, functioning as a deploy-stage orchestrator, solves the challenges confronted by Site Reliability Engineers (SREs) during the early of automating CI/CD processes. This slow feedback and time spent rerunning tests can hinder the overall software deployment process.
” Junior developers are trained to think that if the code solves the problem, the job is finished. We no longer need to spend loads of time training developers; we can train them to be “prompt engineers” (which makes me think of developers who arrive on time), and they will ask the AI for the code, and it will deliver.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content