This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Here’s how Dynatrace can help automate up to 80% of technical tasks required to manage compliance and resilience: Understand the complexity of IT systems in real time Proactively prevent, prioritize, and efficiently manage performance and security incidents Automate manual and routine tasks to increase your productivity 1.
DevOps and security teams managing today’s multicloud architectures and cloud-native applications are facing an avalanche of data. Clearly, continuing to depend on siloed systems, disjointed monitoring tools, and manual analytics is no longer sustainable.
Takeaways from this article on DevOps practices: DevOps practices bring developers and operations teams together and enable more agile IT. Still, while DevOps practices enable developer agility and speed as well as better code quality, they can also introduce complexity and data silos. Dynatrace news.
Over the past decade, DevOps has emerged as a new tech culture and career that marries the rapid iteration desired by software development with the rock-solid stability of the infrastructure operations team. As of August 2019, there are currently over 50,000 LinkedIn DevOps job listings in the United States alone.
With the world’s increased reliance on digital services and the organizational pressure on IT teams to innovate faster, the need for DevOps monitoring tools has grown exponentially. But when and how does DevOps monitoring fit into the process? And how do DevOps monitoring tools help teams achieve DevOps efficiency?
But to be scalable, they also need low-code/no-code solutions that don’t require a lot of spin-up or engineering expertise. With the Dynatrace modern observability platform, teams can now use intuitive, low-code/no-code toolsets and causal AI to extend answer-driven automation for business, development and security workflows.
As organizations accelerate innovation to keep pace with digital transformation, DevOps observability is becoming a critical key to success for DevOps and DevSecOps teams. This drive for speed has a cost: 22% of leaders admit they’re under so much pressure to innovate faster that they must sacrifice code quality.
You have set up a DevOps practice. As we look at today’s applications, microservices, and DevOps teams, we see leaders are tasked with supporting complex distributed applications using new technologies spread across systems in multiple locations. DevOps metrics to help you meet your DevOps goals.
To meet this demand, organizations are adopting DevOps practices , such as continuous integration and continuous delivery, and the related practice of continuous deployment, referred to collectively as CI/CD. When they check in their code, the build management system automatically creates a build and tests it.
As cloud-native, distributed architectures proliferate, the need for DevOps technologies and DevOps platform engineers has increased as well. DevOps engineer tools can help ease the pressure as environment complexity grows. ” What does a DevOps platform engineer do? A DevOps platform engineer is a more recent term.
Whether it means jumping between multiple windows, sifting through extensive logs to track down bugs, trying to reproduce locally, or requesting additional redeployments from DevOps, debugging poses significant challenges and a resource drain. With a single click, developers can access the necessary and relevant data without adding new code.
Organizations are increasingly adopting DevOps to stay competitive, innovate faster, and meet customer needs. By helping teams release new software more frequently, DevOps practices are an essential component of digital transformation. Thankfully, DevOps orchestration has evolved to address these problems. What is orchestration?
Just as organizations have increasingly shifted from on-premises environments to those in the cloud, development and operations teams now work together in a DevOps framework rather than in silos. But as digital transformation persists, new inefficiencies are emerging and changing the future of DevOps.
DevOps and platform engineering are essential disciplines that provide immense value in the realm of cloud-native technology and software delivery. Observability of applications and infrastructure serves as a critical foundation for DevOps and platform engineering, offering a comprehensive view into system performance and behavior.
When it comes to site reliability engineering (SRE) initiatives adopting DevOps practices, developers and operations teams frequently find themselves at odds with one another. Developers want to write high-quality code and deploy it quickly. Operations teams want to make sure the system doesn’t break.
Many organizations that have integrated their software development and operations into DevOps practices struggle with efficiency because they’re juggling disparate DevOps tools, or their tools aren’t meeting their needs. The status quo of the DevOps toolchain. How to approach transforming your DevOps processes.
DevOps and site reliability engineering (SRE) teams aim to deliver software faster and with higher quality. What these steps have in common is that monitoring tools are not in sync with new changes in code or topology and this observability data is often siloed within different tools and teams. The role of observability within DevOps.
The IT world is rife with jargon — and “as code” is no exception. “As code” means simplifying complex and time-consuming tasks by automating some, or all, of their processes. Today, the composable nature of code enables skilled IT teams to create and customize automated solutions capable of improving efficiency.
In the world of DevOps and SRE, DevOps automation answers the undeniable need for efficiency and scalability. Though the industry champions observability as a vital component, it’s become clear that teams need more than data on dashboards to overcome persistent DevOps challenges.
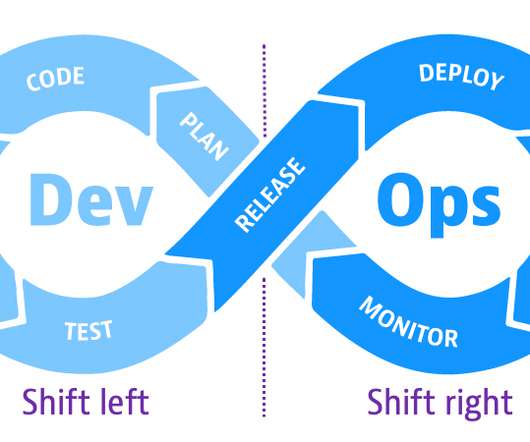
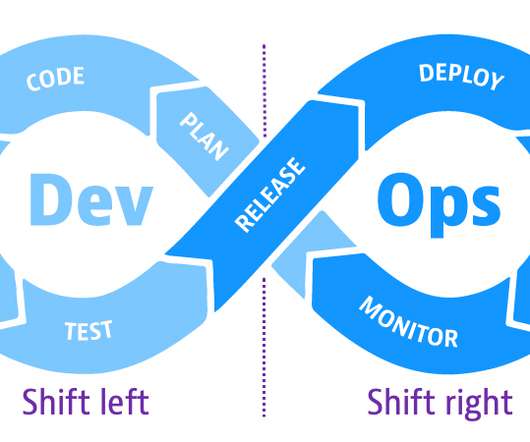
The DevOps approach to developing software aims to speed applications into production by releasing small builds frequently as code evolves. As part of the continuous cycle of progressive delivery, DevOps teams are also adopting shift-left and shift-right principles to ensure software quality in these dynamic environments.
That’s especially true of the DevOps teams who must drive digital-fueled sustainable growth. All of these factors challenge DevOps maturity. Data scale and silos present challenges to DevOps maturity DevOps teams often run into problems trying to drive better data-driven decisions with observability and security data.
The DevOps approach to developing software aims to speed applications into production by releasing small builds frequently as code evolves. As part of the continuous cycle of progressive delivery, DevOps teams are also adopting shift-left and shift-right principles to ensure software quality in these dynamic environments.
Log management is an organization’s rules and policies for managing and enabling the creation, transmission, analysis, storage, and other tasks related to IT systems’ and applications’ log data. In short, log management is how DevOps professionals and other concerned parties interact with and manage the entire log lifecycle.
Dynatrace Delivers Software Intelligence as Code. With this announcement, Dynatrace delivers software intelligence as code, including broad and deep observability, application security, and advanced AIOps (or AI for operations) capabilities. They’re really getting more of a system.”?. Learn more!
To accomplish this, organizations have widely adopted DevOps , which encompasses significant changes to team culture, operations, and the tools used throughout the continuous development lifecycle. Key components of GitOps are declarative infrastructure as code, orchestration, and observability.
As the new standard of monitoring, observability enables I&O, DevOps, and SRE teams alike to gain critical insights into the performance of today’s complex cloud-native environments. An AI-powered solution can rapidly establish and adjust performance baselines and automatically detect anomalies across distributed systems.
Artisan Crafted Images In the Netflix full cycle DevOps culture the team responsible for building a service is also responsible for deploying, testing, infrastructure, and operation of that service. We now have the software and instance configuration as code. This means changes can be tracked and reviewed like any other code change.
Dynatrace’s OneAgent automatically captures PurePaths and analyzes transactions end-to-end across every tier of your application technology stack with no code changes, from the browser all the way down to the code and database level. Monitoring-as-code requirements at Dynatrace.
Infrastructure as code is a way to automate infrastructure provisioning and management. In this blog, I explore how Dynatrace has made cloud automation attainable—and repeatable—at scale by embracing the principles of infrastructure as code. Infrastructure-as-code. But how does it work in practice? Cloud Automation use cases.
At this year’s Google Cloud Next conference, xMatters introduced Flow Designer , a visual designer that enables users to resolve issues without writing a single line of code. As a first use case, let’s explore how your DevOps teams can prevent a process crash from taking down services across an organization—in five easy steps.
At Dynatrace we believe that monitoring and performance should both be automated processes that can be treated as code without the need for any manual intervention. And, applying the “Everything as Code” principles can greatly help achieve that. Treating these different processes as code will ensure that best practices are followed.
DevSecOps is a cross-team collaboration framework that integrates security into DevOps processes from the start rather than waiting to address security in a separate silo. How is it different from DevOps, and what’s next for the relationship between development, security, and operations within enterprises?
To orchestrate the different logging services, you use Fluent Bit to forward these logs to your centralized logging system, like Dynatrace. This caused you to lose complete visibility of your containers logs, performance, and error data, and you could not tell if the system was down or not.
The DevOps playbook has proven its value for many organizations by improving software development agility, efficiency, and speed. This method known as GitOps would also boost the speed and efficiency of practicing DevOps organizations. Development teams use GitOps to specify their infrastructure requirements in code.
As organizations become cloud-native and their environments more complex, DevOps teams are adapting to new challenges. Today, the platform engineer role is gaining speed as the newest byproduct of scaling DevOps in the emerging but complex cloud-native world. What is this new discipline, and is it a game-changer or just hype?
GPT (generative pre-trained transformer) technology and the LLM-based AI systems that drive it have huge implications and potential advantages for many tasks, from improving customer service to increasing employee productivity. GPTs can also help quickly onboard team members to new development platforms and toolsets.
Not just infrastructure connections, but the relationships and dependencies between containers, microservices , and code at all network layers. DevOps teams can also benefit from full-stack observability. With improved diagnostic and analytic capabilities, DevOps teams can spend less time troubleshooting. Watch webinar now!
Centralization of platform capabilities improves efficiency of managing complex, multi-cluster infrastructure environments According to research findings from the 2023 State of DevOps Report , “36% of organizations believe that their team would perform better if it was more centralized.” Ensure that you get the most out of your product.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. SRE applies DevOps principles to developing systems and software that help increase site reliability and performance.
Indeed, according to one survey, DevOps practices have led to 60% of developers releasing code twice as quickly. But increased speed creates a tradeoff: According to another study, nearly half of organizations consciously deploy vulnerable code because of time pressure. Increased adoption of Infrastructure as code (IaC).
Here’s what we discussed so far: In Part 1 we explored how DevOps teams can prevent a process crash from taking down services across an organization. Let’s assume your team has just pushed new code and it passed pre-deployment testing. Step 1 — The Dynatrace Davis AI-engine identifies the root cause. Dynatrace Davis in action.
That’s why many organizations are turning to generative AI—which uses its training data to create text, images, code, or other types of content that reflect its users’ natural language queries—and platform engineering to create new efficiencies and opportunities for innovation. No one will be around who fully understands the code.
SRE is becoming an essential discipline in organizations that use DevOps (the combination of development and operations) and agile methodologies. The report uncovers six site reliability engineering trends that will help organizations get the most from DevOps practices. SRE adoption is growing, yet gaps remain.
The article, titled “ K8s celebrates KuberTENes: A decade of working together ,” applauds the collective efforts of more than 88,000 members of a committed community who have offered code and insight to improve Kubernetes.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content