This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With the world’s increased reliance on digital services and the organizational pressure on IT teams to innovate faster, the need for DevOpsmonitoring tools has grown exponentially. But when and how does DevOpsmonitoring fit into the process? And how do DevOpsmonitoring tools help teams achieve DevOps efficiency?
DevOps and security teams managing today’s multicloud architectures and cloud-native applications are facing an avalanche of data. On average, organizations use 10 different tools to monitor applications, infrastructure, and user experiences across these environments.
Manual approaches lack continuous monitoring, making them ill-equipped to prevent issues before they arise. DevSecOps teams can integrate security gates into release processes to prevent the deployment of code or containers with vulnerabilities or compliance issues at runtime. Processes are time-intensive. Reactivity.
HashiCorp’s Terraform is an open-source infrastructure as a code software tool that provides a consistent CLI workflow to manage hundreds of cloud services. With this integration, Dynatrace customers can now leverage Terraform to manage their monitoring infrastructure as code,” said Asad Ali, Senior Director of Sales Engineering at Dynatrace.
Takeaways from this article on DevOps practices: DevOps practices bring developers and operations teams together and enable more agile IT. Still, while DevOps practices enable developer agility and speed as well as better code quality, they can also introduce complexity and data silos. Dynatrace news.
DevOps automation can help to drive reliability across the SDLC and accelerate time-to-market for software applications and new releases. What is DevOps automation? DevOps automation is a set of tools and technologies that perform routine, repeatable tasks that engineers would otherwise do manually.
But to be scalable, they also need low-code/no-code solutions that don’t require a lot of spin-up or engineering expertise. IT leaders know that managing cloud environments through traditional manual monitoring practices will no longer suffice. The low-code/no-code AutomationEngine brings several benefits to customers.
Dynatrace’s OneAgent automatically captures PurePaths and analyzes transactions end-to-end across every tier of your application technology stack with no code changes, from the browser all the way down to the code and database level. Monitoring-as-code requirements at Dynatrace.
As more organizations transition to distributed services, IT teams are experiencing the limitations of traditional monitoring tools, which were designed for yesterday’s monolithic architectures. Where traditional monitoring falls flat. Observability defined. Then teams can leverage and interpret the observable data.
DevOps seeks to accomplish smooth and efficient software creation, delivery, monitoring, and improvement by prioritizing agility and adaptability over rigid, stage-by-stage development. What is DevOps? As DevOps pioneer Patrick Debois first described it in 2009, DevOps is not a specific technology, but a tactical approach.
You have set up a DevOps practice. As we look at today’s applications, microservices, and DevOps teams, we see leaders are tasked with supporting complex distributed applications using new technologies spread across systems in multiple locations. DevOps metrics to help you meet your DevOps goals. Dynatrace news.
As organizations accelerate innovation to keep pace with digital transformation, DevOps observability is becoming a critical key to success for DevOps and DevSecOps teams. This drive for speed has a cost: 22% of leaders admit they’re under so much pressure to innovate faster that they must sacrifice code quality.
Organizations are increasingly adopting DevOps to stay competitive, innovate faster, and meet customer needs. By helping teams release new software more frequently, DevOps practices are an essential component of digital transformation. Thankfully, DevOps orchestration has evolved to address these problems. What is orchestration?
To meet this demand, organizations are adopting DevOps practices , such as continuous integration and continuous delivery, and the related practice of continuous deployment, referred to collectively as CI/CD. When they check in their code, the build management system automatically creates a build and tests it.
To keep up with current demands, DevOps and platform engineering teams need a solution that can fully embrace and understand complexity, delivering precise answers that enable the creation of trustworthy automation. Automation + Synthetic = Perfect match This is why we integrated Synthetic monitoring in Workflows.
As cloud-native, distributed architectures proliferate, the need for DevOps technologies and DevOps platform engineers has increased as well. DevOps engineer tools can help ease the pressure as environment complexity grows. ” What does a DevOps platform engineer do? A DevOps platform engineer is a more recent term.
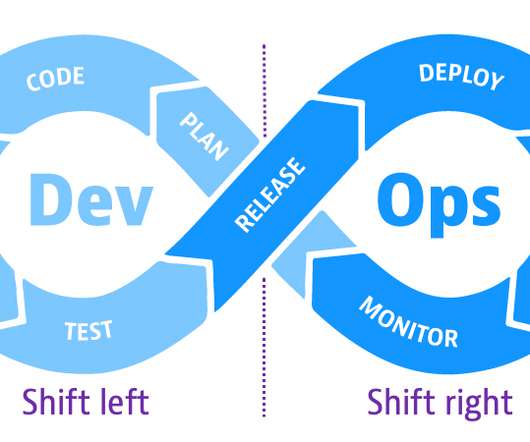
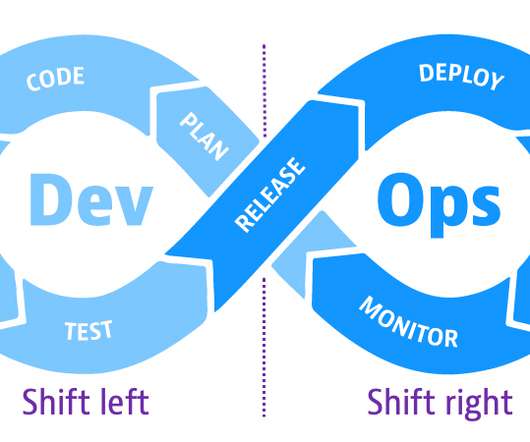
The DevOps approach to developing software aims to speed applications into production by releasing small builds frequently as code evolves. As part of the continuous cycle of progressive delivery, DevOps teams are also adopting shift-left and shift-right principles to ensure software quality in these dynamic environments.
Just as organizations have increasingly shifted from on-premises environments to those in the cloud, development and operations teams now work together in a DevOps framework rather than in silos. But as digital transformation persists, new inefficiencies are emerging and changing the future of DevOps.
The IT world is rife with jargon — and “as code” is no exception. “As code” means simplifying complex and time-consuming tasks by automating some, or all, of their processes. Today, the composable nature of code enables skilled IT teams to create and customize automated solutions capable of improving efficiency.
The DevOps approach to developing software aims to speed applications into production by releasing small builds frequently as code evolves. As part of the continuous cycle of progressive delivery, DevOps teams are also adopting shift-left and shift-right principles to ensure software quality in these dynamic environments.
It gives you visibility into which components are monitored and which are not and helps automate time-consuming compliance configuration checks. Discovery & Coverage helps prevent unexpected outages by detecting and remediating monitoring coverage gaps across your entire enterprise.
When it comes to site reliability engineering (SRE) initiatives adopting DevOps practices, developers and operations teams frequently find themselves at odds with one another. Developers want to write high-quality code and deploy it quickly. Too many SLOs create complexity for DevOps. Limits of scripting for DevOps and SRE.
DevOps and platform engineering are essential disciplines that provide immense value in the realm of cloud-native technology and software delivery. Observability of applications and infrastructure serves as a critical foundation for DevOps and platform engineering, offering a comprehensive view into system performance and behavior.
Organizations can now accelerate innovation and reduce the risk of failed software releases by incorporating on-demand synthetic monitoring as a metrics provider for automatic, continuous release-validation processes. Dynatrace combines Synthetic Monitoring with automatic release validation for continuous quality assurance across the SDLC.
For executives, these directives present several challenges, including compliance complexity, resource allocation for continuous monitoring, and incident reporting. Runtime Security integrates seamlessly with static code analyzers, container scanners, and application security testing tools.
That’s especially true of the DevOps teams who must drive digital-fueled sustainable growth. All of these factors challenge DevOps maturity. Data scale and silos present challenges to DevOps maturity DevOps teams often run into problems trying to drive better data-driven decisions with observability and security data.
Log monitoring, log analysis, and log analytics are more important than ever as organizations adopt more cloud-native technologies, containers, and microservices-based architectures. What is log monitoring? Log monitoring is a process by which developers and administrators continuously observe logs as they’re being recorded.
We are pleased to announce Atlassian has selected Dynatrace as a launch partner for its Open DevOps initiative, which combines Atlassian products and best-in-class solutions from key partners to deliver full lifecycle value to customers. Visit the Atlassian Marketplace to explore the integrations today.
To accomplish this, organizations have widely adopted DevOps , which encompasses significant changes to team culture, operations, and the tools used throughout the continuous development lifecycle. Key components of GitOps are declarative infrastructure as code, orchestration, and observability.
DevOps and site reliability engineering (SRE) teams aim to deliver software faster and with higher quality. What these steps have in common is that monitoring tools are not in sync with new changes in code or topology and this observability data is often siloed within different tools and teams. Automation presents a solution.
As a result, API monitoring has become a must for DevOps teams. So what is API monitoring? What is API Monitoring? API monitoring is the process of collecting and analyzing data about the performance of an API in order to identify problems that impact users. The need for API monitoring. Ways to monitor APIs.
IT, DevOps, and SRE teams are racing to keep up with the ever-expanding complexity of modern enterprise cloud ecosystems and the business demands they are designed to support. Observability is the new standard of visibility and monitoring for cloud-native architectures. Requirements to achieve multicloud observability and monitoring.
Service-level objectives (SLOs) are a great tool to align business goals with the technical goals that drive DevOps (Speed of Delivery) and Site Reliability Engineering (SRE) (Ensuring Production Resiliency). Dynatrace’s Real User Monitoring (RUM) offering provides observability to every end-user that uses your mobile or web applications.
Infrastructure as code is a way to automate infrastructure provisioning and management. In this blog, I explore how Dynatrace has made cloud automation attainable—and repeatable—at scale by embracing the principles of infrastructure as code. Infrastructure-as-code. But how does it work in practice? Transparency and scalability.
Monitoring and observability are important topics for any developer, architect, or Site Reliability Engineer (SRE), and this holds true independent of the language or runtime of choice. In my role as Developer and DevOps Advocate, I have the luxury of interacting with many different people on a daily basis. Dynatrace news.
And with today’s increasing financial, availability, performance and innovation requirements meaning applications need to be geographically dispersed to constantly changing dynamic powerhouses, it has become simply not possible to provision, update, monitor and decommissions them by only leveraging manual processes.
Centralization of platform capabilities improves efficiency of managing complex, multi-cluster infrastructure environments According to research findings from the 2023 State of DevOps Report , “36% of organizations believe that their team would perform better if it was more centralized.” All important health signals are highlighted.
Traditional monitoring approaches often require manual scripting and integration to get alerted about production-threatening issues in pre-production environments. If you ever need more advanced capabilitieslike custom code, multi-step logic, or conditional tasksyou can seamlessly upgrade to standard workflows with just a few clicks.
In the coming weeks and months, we will add to the current collection of templates for synthetic monitoring, digital experience management measures, Kubernetes resource optimization, and infrastructure monitoring. However, all of these can be created today using DQL queries.
Not just infrastructure connections, but the relationships and dependencies between containers, microservices , and code at all network layers. Comprehensive observability is also essential for digital experience monitoring (DEM). DevOps teams can also benefit from full-stack observability. Why full-stack observability matters.
And that includes infrastructure monitoring. Rather than just “keeping the lights on,” the modern I&O team must evolve to become responsible for building and maintaining the cloud platform, empowering DevOps teams to build, deploy and run applications themselves. Able to provide answers, not just data. Automatic and easy.
The DevOps playbook has proven its value for many organizations by improving software development agility, efficiency, and speed. This method known as GitOps would also boost the speed and efficiency of practicing DevOps organizations. Development teams use GitOps to specify their infrastructure requirements in code.
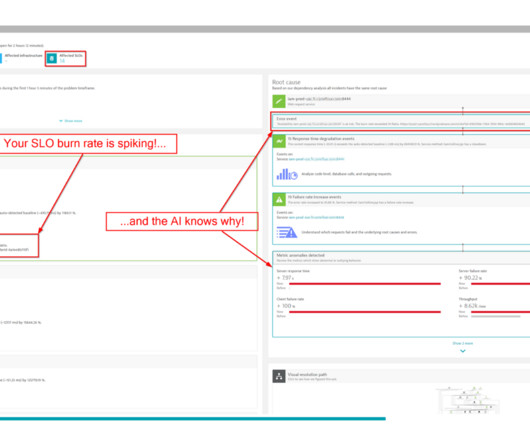
SLO monitoring and alerting on SLOs using error-budget burn rates are critical capabilities that can help organizations achieve that goal. SLOs are pivotal for development, DevOps, and SRE teams because they provide a common language for discussing system reliability. What is SLO monitoring?
Release validation is a critical DevOps practice to help ensure that code released into production is successful. DevOps practices have become key for organizations looking to scale, stay competitive, and keep up with customer demand. This can become a complicated step if the application or code is complex.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content