This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this OpenTelemetry demo series, we’ll take an in-depth look at how to use OpenTelemetry to add observability to a distributed web application that originally didn’t know anything about tracing, telemetry, or observability. These observations and insights are all far beyond what classic logging typically provides.
In the first part of this three-part series, The road to observability with OpenTelemetry demo part 1: Identifying metrics and traces with OpenTelemetry , we talked about observability and how OpenTelemetry works to instrument applications across different languages and platforms. php declare(strict_types=1); require __DIR__.
We also introduced our demo app and explained how to define the metrics and traces it uses. The second part, The road to observability with OpenTelemetry part 2: Setting up OpenTelemetry and instrumenting applications , covers the details of how to set up OpenTelemetry in our demo application and how to instrument the services.
This is the story of the most unbelievable demo I've been given in world of open source. He was kind enough to give me a quick demo anyway. But I _did_ understand these tools, since I had coded similar functionality for my own DTraceToolkit. You can't make this stuff up. This gave performance analysts like myself X-ray vision.
To ensure high standards, it’s essential that your organization establish automated validations in an early phase of the software development process—ideally when code is written. Ensure expected production behavior One Dynatrace team is responsible for the demo applications we use to demonstrate Dynatrace capabilities.
If you want to know more about keptn, I encourage you to check out www.keptn.sh , “What is keptn and how to get started” (blog), “Getting started with keptn” (YouTube) or my slides on Shipping Code like a keptn. Remember that I told you I initially ignored these errors as I thought they are just part of my demo?
They are part of continuous delivery pipelines and examine code to find vulnerabilities. There is another critical element that needs to be addressed: how do you protect applications against attacks exploiting vulnerabilities while DevSecOps teams simultaneously try to resolve those issues in the code ?
Synthetic CI/CD testing simulates traffic to add an outside-in view to the analysis. Synthetic monitors can be created with our innovative web recorder or through MONACO , our Monitoring-As-Code approach. Request your Dynatrace Synthetic Monitoring and Cloud Automation demo, or integrate them into your SDLC directly.
EC2 is ideally suited for large workloads with constant traffic. Lambda is Amazon’s event-driven, functions-as-a-service (FaaS) compute service that runs code when triggered for application and back-end services. Watch demo now! AWS Lambda. AWS monitoring best practices.
Instead, we want to focus on detecting and stopping attacks before they happen: In your applications, in context, at the exact line of code that is vulnerable and in use. In the following sections, we demo the following: Introduce Unguard, our insecure cloud-native microservices demo application.
In other words, where the application code resides. When the SLO status converges to an optimal value of 100%, and there’s substantial traffic (calls/min), BurnRate becomes more relevant for anomaly detection. SLOs must be evaluated at 100%, even when there is currently no traffic. What characterizes a weak SLO?
Developers can use logs, for example, to identify areas of code that are executed more frequently than needed or run for longer durations than expected. When it comes to security, logs can capture attack indicators, such as anomalous network traffic or unusual application activity outside of expected times. Watch webinar now!
Dynatrace Notebooks is an interactive capability that enables users across the organization to collaborate using code, text, and rich media to build, evaluate, and share insights for exploratory analytics. Examples include successful checkouts, newsletter signups, or demo requests.
I selfishly look at my blog posts (like this one) and see whether LinkedIn, or Twitter, drove more traffic! Are these visits impacted by response time or code/application issues? This is my demo dashboard. Which pages are viewed the most, how did they get to that page, and what are they doing after?
Teams are embracing new technologies and continuously deploying code. But what if you could see what’s running in production in real-time, continuously analyzing all services for vulnerabilities, and prioritizing those based on what code is called? They also can’t provide deep insights unless you have source code access.
Unlike other monitoring tools on the market, which don’t provide AI-driven anomaly detection and alerting, Dynatrace delivers real-time data to track the performance of your deployed apps and the characteristics of your client traffic. Dynatrace allows you to quickly check if the new code in the staging slot works as expected. .
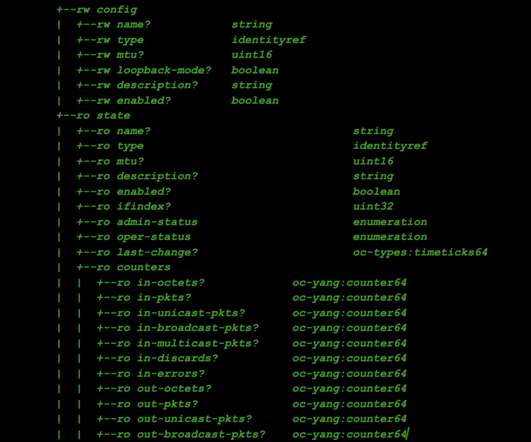
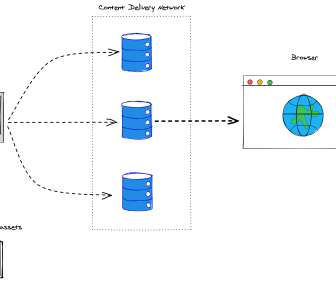
Introducing gnmi-gateway: a modular, distributed, and highly available service for modern network telemetry via OpenConfig and gNMI By: Colin McIntosh, Michael Costello Netflix runs its own content delivery network, Open Connect , which delivers all streaming traffic to our members.
In such circumstances, it’s challenging to investigate the reasons for unexpected behavior or traffic between pods. Dynatrace is the only Kubernetes monitoring solution that provides continuous automation and full-stack automated observability without changing code, container images, or deployments. A new Node.js
Watch a demo and learn how Etleap can save you on engineering hours and decrease your time to value for your Amazon Redshift analytics projects. Take Triplebyte's multiple-choice quiz (system design and coding questions) to see if they can help you scale your career faster. Register for the webinar today. Advertise your event here!
Watch a demo and learn how Etleap can save you on engineering hours and decrease your time to value for your Amazon Redshift analytics projects. Take Triplebyte's multiple-choice quiz (system design and coding questions) to see if they can help you scale your career faster. Register for the webinar today. Advertise your event here!
Watch a demo and learn how Etleap can save you on engineering hours and decrease your time to value for your Amazon Redshift analytics projects. Take Triplebyte's multiple-choice quiz (system design and coding questions) to see if they can help you scale your career faster. Register for the webinar today. Advertise your event here!
End-to-end code-level tracing. Instead of presenting you with a handful of random screenshots from our demo environment I reached out to Robert, a close friend of mine, who leads a development team with the current task to re-architect and re-platform their multi-tenant SaaS-based eCommerce platform. . #2 Full-stack observability.
But this allows us to decouple content from code, by moving content to a Content Management System (CMS) we can update information in a few seconds, regardless of how big our application is. It is not possible to ship code incrementally. You can check both versions deployed to Netlify: With On-Demand Builder: code , live.
This is the story of the most unbelievable demo I've been given in world of open source. He was kind enough to give me a quick demo anyway. But I _did_ understand these tools, since I had coded similar functionality for my own DTraceToolkit. You can't make this stuff up. This gave performance analysts like myself X-ray vision.
Using the AWS Toolkit for Visual Studio , you can now deploy your.NET applications to AWS Elastic Beanstalk directly from your Visual Studio environment without changing any code. For a hands-on demo on how to deploy.NET applications on Elastic Beanstalk with Amazon RDS for SQL Server, visit the AWS Elastic Beanstalk Developer Guide.
There is no way to model how much more traffic you can send to that system before it exceeds it’s SLA. The code is written using the R statistics language and I downloaded a free copy of RStudio to run the examples below. > For this demo on an old MacBook (2.7 The initial loglik value is higher but trends to the same result.
WordPress Theme Development Tips Add favicon – A WordPress hook will help you to insert custom code. To achieve a user-friendly interface, you may: Start with mockups – When you hire developers for custom WordPress theme development, they may start coding right away without planning about the features and thinking about them.
That’s not all, the global mobile traffic is expected to increase sevenfold between 2017 and 2022. With this, let’s look at some of the best approaches & tools that can help in building a rock-solid mobile website testing strategy: Validation of HTML and CSS Code. Book a demo. Critical, Severe, Medium, and Low).
SUS209 — there was no talk with this code. SUS304 to SUS311 No talks with these codes. It includes a demo of AWS Twinmaker and a discussion of lithium battery production and recycling by Northvolt in Sweden, who are using serverless on AWS to build factories-as-code. STP213 Scaling global carbon footprint management.
In addition to allowing you to create web applications without the need for a server, this tool supports all of the advanced features you’d expect from a modern IDE like code hinting and completion. Eclipse PDT Though originally intended for Java coding, Eclipse can be extended to support PHP with the PDT plugin.
You can monitor, tweak, and retry traffic from any application or network device, with no need to write your own code. Click here to schedule a demo/conversation. It just works. Apica allows you to script real world scenarios to truly represent your customer journeys. Want to learn more about Apica Ascent?
It is also one of the four golden signals of monitoring, which also includes traffic, error, and saturation. The metrics measured could be monitoring HTTP (Hypertext Transfer Protocol) requests, response codes, user metrics, etc. This also includes latency, or the time it takes for data or a request to get through a network.
However, the above table is not actually representative of total traffic, and that’s another point to note about this data. The BrowserLeaks demo above actually cheats, by loading that data in an iframe rather than in the main document, to get around this.
You should expect one-time implementation cost (depending CMS and business requirements it can cost 200,000 USD to 3M USD) and yearly hosting infrastructure cost (proportional to load and traffic but typically 30,000 USD - 300,000 USD per year). Due to strong templating support, a website managed by SSG can be truly modular.
Traffic shaping / canary deployment was pre-announced at Serverless Conf NYC in October, and this is now available. Like Lambda, API Gateway now supports canary deployment / traffic shaping. A much bigger update is the new integration with CodeDeploy to support Traffic Shaping and Canary Releases. But we’re keeping an open mind.
It uses a Solaris Porting Layer (SPL) to provide a Solaris-kernel interface on Linux, so that unmodified ZFS code can execute. There's also a ZFS send/recv code path that should try to use the TASK_INTERRUPTIBLE flag (as suggested by a coworker), to avoid a kernel hang (can't kill -9 the process). LTS (April 2016).
Plan in suitable buffer time for traffic issues, etc. For the purposes of this article, I built a series of reduced demos showing how each of the LCP types behave. The initial demos can be found at: ??. ?? In our demo, it is actually flagged as being the much smaller element. Set appropriate alarms. Block-level.
It’s happening because of new features being added and the fact that we sometimes don’t have a second thought on packages that we constantly add and update, or think about the complexity of our code. This saves clients traffic — sometimes traffic which the client is paying for. The script was finished with a non-zero code.
Our demo project on a not-so-hot-anymore framework that we want to migrate. However, as a possibly better alternative, we could refactor this code to make the two components independent from each other and satisfy the requirement of independence: index.js. From now on, we’re directing HTTP traffic to our React subfolder.
Have we optimized enough with tree-shaking, scope hoisting, code-splitting, and all the fancy loading patterns with intersection observer, progressive hydration, clients hints, HTTP/3, service workers and — oh my — edge workers? It’s much easier to reach performance goals when the code base is fresh or is just being refactored.
Is it worth exploring tree-shaking, scope hoisting, code-splitting, and all the fancy loading patterns with intersection observer, server push, clients hints, HTTP/2, service workers and — oh my — edge workers? It’s much easier to reach performance goals when the code base is fresh or is just being refactored.
Is it worth exploring tree-shaking, scope hoisting, code-splitting, and all the fancy loading patterns with intersection observer, server push, clients hints, HTTP/2, service workers and — oh my — edge workers? The first render tends to warm up a bunch of lazily compiled code, which a larger tree can benefit from when it scales.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content