This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Manual approaches lack continuous monitoring, making them ill-equipped to prevent issues before they arise. DevSecOps teams can integrate security gates into release processes to prevent the deployment of code or containers with vulnerabilities or compliance issues at runtime. Processes are time-intensive. Reactivity.
Histograms are commonly used to define and monitor service-level objectives (SLOs). Moreover, the OpenTelemetry Collector can measure service span durations, categorized by span names, span kinds, and status codes. Histograms also enhance the self-monitoring capabilities of the Collector.
It gives you visibility into which components are monitored and which are not and helps automate time-consuming compliance configuration checks. Discovery & Coverage helps prevent unexpected outages by detecting and remediating monitoring coverage gaps across your entire enterprise.
In this OpenTelemetry demo series, we’ll take an in-depth look at how to use OpenTelemetry to add observability to a distributed web application that originally didn’t know anything about tracing, telemetry, or observability. These observations and insights are all far beyond what classic logging typically provides.
Synthetic monitoring can help to confirm your applications are performing as intended and, in the event they’re not, help you quickly figure out what’s going on. Here’s a look at what synthetic monitoring is, how it’s different from real-user monitoring, and why it matters to your business.
In the first part of this three-part series, The road to observability with OpenTelemetry demo part 1: Identifying metrics and traces with OpenTelemetry , we talked about observability and how OpenTelemetry works to instrument applications across different languages and platforms. php declare(strict_types=1); require __DIR__.
We also introduced our demo app and explained how to define the metrics and traces it uses. The second part, The road to observability with OpenTelemetry part 2: Setting up OpenTelemetry and instrumenting applications , covers the details of how to set up OpenTelemetry in our demo application and how to instrument the services.
Dynatrace broadens its Digital Experience Monitoring capabilities by adding Flutter support. With the release of Flutter support in Dynatrace, we’re filling a gap that no other solution in the market has addressed, enabling you to leverage the full power of Dynatrace Digital Experience Monitoring for Flutter apps.
These resources generate vast amounts of data in various locations, including containers, which can be virtual and ephemeral, thus more difficult to monitor. These challenges make AWS observability a key practice for building and monitoring cloud-native applications. AWS monitoring best practices. What is AWS observability?
As part of the Platform Extensions team, I’m one of those responsible for services that include the Dynatrace OneAgent SDKs, which are libraries that allow us to extend end-to-end visibility for technologies and frameworks for which there is no code module available yet. Custom code. What about proprietary code? Database calls.
Organizations can now accelerate innovation and reduce the risk of failed software releases by incorporating on-demand synthetic monitoring as a metrics provider for automatic, continuous release-validation processes. Dynatrace combines Synthetic Monitoring with automatic release validation for continuous quality assurance across the SDLC.
Real user monitoring can help you catch these issues before they impact the bottom line. What is real user monitoring? Real user monitoring (RUM) is a performance monitoring process that collects detailed data about a user’s interaction with an application. Real user monitoring collects data on a variety of metrics.
Monitoring Kubernetes is an important aspect of Day 2 o perations and is often perceived as a significant challenge. A container with inefficient code might affect critical workloads and practically make the whole node unusable , or worse, because of replication, it can impact the whole cluster. Node and w orkload health .
Despite its benefits, serverless computing introduces additional monitoring challenges for developers and IT Operations, particularly in understanding dependencies and identifying issues in the end-to-end traces that flow through a complex mix of dynamic and hybrid on-premise/cloud environments. Azure Functions in a nutshell.
Log monitoring, log analysis, and log analytics are more important than ever as organizations adopt more cloud-native technologies, containers, and microservices-based architectures. What is log monitoring? Log monitoring is a process by which developers and administrators continuously observe logs as they’re being recorded.
Many of our customers—the world’s largest enterprises—have embraced the Dynatrace SaaS approach to monitoring, which provides critical business insights powered by AI and automation for globally-distributed, heterogeneous IT landscapes. New self-monitoring environment provides out-of-the-box insights and custom alerting.
Every software development team grappling with Generative AI (GenAI) and LLM-based applications knows the challenge: how to observe, monitor, and secure production-level workloads at scale. Production performance monitoring: Service uptime, service health, CPU, GPU, memory, token usage, and real-time cost and performance metrics.
Open-Sourcing a Monitoring GUI for Metaflow, Netflix’s ML Platform tl;dr Today, we are open-sourcing a long-awaited GUI for Metaflow. The Metaflow GUI allows data scientists to monitor their workflows in real-time, track experiments, and see detailed logs and results for every executed task.
As Dynatrace is a leader in Cloud monitoring, we have architected our Software Intelligence Platform specifically to complement Kubernetes by providing extensive functionality to tame the complexities and prevent performance issues that can occur across the development and deployment cycles. Don’t underestimate complexity.
If you want to know more about keptn, I encourage you to check out www.keptn.sh , “What is keptn and how to get started” (blog), “Getting started with keptn” (YouTube) or my slides on Shipping Code like a keptn. In my case, both prometheus.knative-monitoring pods jumped in Process CPU and I/O request bytes.
Despite its benefits, serverless computing introduces additional monitoring challenges for developers and IT Operations, particularly in understanding dependencies and identifying issues in the end-to-end traces that flow through a complex mix of dynamic and hybrid on-premise/cloud environments. Azure Functions in a nutshell.
I’m willing to bet you still monitor TTFB , even though you know your customers will have no concept of a first byte whatsoever. If you aren’t (able to) monitoring custom metrics around your application’s interactivity, hydration state, etc., Or are they…? Technically Meaningful Not all metrics need to be user-centric. View unabridged.
Furthermore, a centralized Kubernetes management view offers extended centralized monitoring and alerting capabilities, particularly for node failure incidents. Additionally, users benefit from the Dynatrace Davis ® AI engine, which offers proactive monitoring capabilities like real-time tracking and alerting for critical health signals.
Dynatrace ownership functionality supports configuration-as-code via its proprietary Monaco (Monitoring as code) CLI or Terraform. An example can be seen in our platform engineering demo (If you want to try out the platform engineering demo, please look at this repository , where you can run the demo within GitHub codespaces.
To ensure high standards, it’s essential that your organization establish automated validations in an early phase of the software development process—ideally when code is written. Ensure expected production behavior One Dynatrace team is responsible for the demo applications we use to demonstrate Dynatrace capabilities.
The show surrounding logs function provides Dynatrace users with the ability to dive deeper and surface context-specific log lines of the components and services linked to the problem—all without a single line of code or complex query language knowledge. Learn how Dynatrace can address your specific needs with a custom live demo.
Not just infrastructure connections, but the relationships and dependencies between containers, microservices , and code at all network layers. Comprehensive observability is also essential for digital experience monitoring (DEM). This crucial context also enables teams to understand how all entities are connected. Watch webinar now!
Kubernetes (k8s) provides basic monitoring through the Kubernetes API and you can find instructions like Top 9 Open Source Tools for Monitoring Kubernetes as a “do it yourself guide”. End-to-end code-level tracing. End-user monitoring. Dynatrace news. Full-stack observability. Service mash insights.
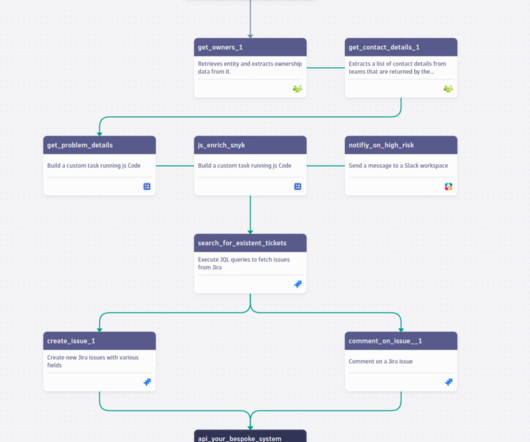
To address this need, Dynatrace now provides automation for DevSecOps collaboration that associates ownership information with monitored services to further minimize mean-time-to-restore (MTTR). Associating ownership-team details with monitored services is flexible. team structure, or links to external resources such as a wiki.
Instead, we want to focus on detecting and stopping attacks before they happen: In your applications, in context, at the exact line of code that is vulnerable and in use. Likewise, operation specialists can prioritize their efforts on monitoring the highest-risk tactics, and executives can better communicate the business risk.
You took advantage of the launch of AutomationEngine , configured ownership information for all the monitored entities in your IT landscape, and set up workflows that automatically create tickets and route them to the responsible teams when security vulnerabilities are detected. Build a custom task running JS code.
Code development also benefits from a serverless approach. Then, they can apply DevSecOps best practices to fully test new code and see what breaks without affecting current operations. Serverless architecture makes it possible to host code anywhere, rather than relying on an origin server. Difficult to monitor.
“Digital workers are now demanding IT support to be more proactive,” is a quote from last year’s Gartner Survey Understandably, a higher number of log sources and exponentially more log lines would overwhelm any DevOps, SRE, or Software Developer working with traditional log monitoring solutions.
While logging is the act of recording logs, organizations extract actionable insights from these logs with log monitoring, log analytics, and log management. Comparing log monitoring, log analytics, and log management. Log monitoring enables the collection of log data, and log analysis promotes intelligent, data-driven decision making.
Part one also provided an overview of Dynatrace’s Cloud Automation solution, Microsoft’s GitHub Actions , and open-source examples you can use and extend related to deployment and release monitoring. Example #3 – Automate Monitoring configuration as code. Example #3 – Automate Monitoring configuration as code.
Someone hacks together a quick demo with ChatGPT and LlamaIndex. The system is inconsistent, slow, hallucinatingand that amazing demo starts collecting digital dust. Check out the graph belowsee how excitement for traditional software builds steadily while GenAI starts with a flashy demo and then hits a wall of challenges?
In 2015, the Spring folks already regarded Dynatrace as the gold standard for performance monitoring. We’ll demonstrate this with a demo Spring application, which uses the Spring Web and Dynatrace Micrometer registry, as shown below. Either way, the Dynatrace Micrometer Registry adds proper topology without modifying your code.
There’s no lack of metrics, logs, traces, or events when monitoring your Kubernetes (K8s) workloads. At Dynatrace we’re lucky to have Dynatrace monitor our workloads running on K8s. One of those workloads is Keptn , a CNCF project Dynatrace is contributing to, that we use internally for different SLO-driven automation use cases.
IDC predicted, by 2022, 90% of all applications will feature microservices architectures that improve the ability to design, debug, update, and use third-party code. Monolithic architecture is development where an application is built on a single codebase, and the code is unilateral. Less code and stack lock-in. Better testing.
I could upgrade the vehicle in the app, or simply get in the car and use the QR code to exit the garage. How well do the IT departments for each of these companies monitor critical user journeys and business transactions? Based on my experience, here are my guesses: The airline IT team does not monitor user journeys.
In recent years, function-as-a-service (FaaS) platforms such as Google Cloud Functions (GCF) have gained popularity as an easy way to run code in a highly available, fault-tolerant serverless environment. GCF also enables teams to run custom-written code to connect multiple services in Node, Python, Go, Java,NET, Ruby, and PHP.
Real-time monitoring with out-of-the-box features Real-time data and monitoring are crucial for maintaining situational awareness of IT environment stability and performance, especially during a crisis. They also enable companies to measure the effectiveness of their remediation activities to ensure that recoveries proceed as expected.
As such, we recently opened up our platform for metric ingestion and log monitoring and built integrations for key formats in those spaces. Say you’re running the Online Boutique , a cloud-native microservices demo application, that allows users to browse items, add them to a shopping cart, and purchase them. Detailed use case.
DevOps teams are responsible for all phases of the software development lifecycle, from code commit to the deployment of products and services. Version control system and source code management with end-to-end DevOps platform and cloud-hosted Git services. Infrastructure as code (IaC) configuration management tool.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content